WordPress über das Web-Interface zu steuern ist recht komfortabel. Zumindest in vielen Fällen. Gerade als Linux-Nutzer wünscht man sich aber dann doch manchmal eine Kommandozeile, gerade wenn Tätigkeiten automatisiert werden sollen. Zum Glück gibt es mit WP-CLI („WordPress Commandline Interface“) eine Lösung. Und was WP-CLI kann, kann sich sehen lassen: WordPress installieren, Plugins aktualisieren, Datenbank-Dumps erstellen und wieder einlesen, Kommentare verwalten und noch vieles mehr.
Der Vorteil bei Nutzung von WP-CLI ist zudem, dass die WordPress-Dateien nicht vom Web-Server beschreibbar sein müssen. Gegenüber den automatisierten Updates, die WordPress mitbringt, ist dies ein klares Plus an Sicherheit, da kompromittierte Plugins dadurch keine weiteren Dateien ändern können.
[toc]
Voraussetzungen
Um WP-CLI nutzen zu können, musst du SSH-Zugriff auf Deinen Server haben. Ein billiger Shared Hosting tut es hier also nicht. Auch empfiehlt es sich, ein bisschen Erfahrung mit der Kommandozeile zu haben. Ich gehe daher im folgenden davon aus, dass du die Grundlagen einer Linux-Shell beherrschst.
WP-CLI installieren
Die Installation von WP-CLI ist relativ einfach. Dazu wechselst du zunächst in dein Home-Verzeichnis (wo man nach dem Einloggen wahrscheinlich schon ist). Dort lädst du dann WP-CLI mit folgendem Kommando herunter:
curl -O https://raw.githubusercontent.com/wp-cli/builds/gh-pages/phar/wp-cli.phar
Es empfiehlt sich, zu testen, ob alles funktioniert:
$ php wp-cli.phar --info
PHP binary: /usr/bin/php5
PHP version: 5.6.17-0+deb8u1
php.ini used: /etc/php5/cli/php.ini
....
Gibt es dies oder ähnliches aus, dann funktioniert alles. Du kannst die Datei dann in deinen Pfad verschieben und ausführbar machen. Als root kann man sie z.B. nach /usr/local/bin kopieren, hier verschiebe ich sie allerdings in mein lokales bin/-Verzeichnis:
chmod 755 wp-cli.phar
mv wp-cli.phar ~/bin/wp
Nun heißt es also wp und kann entsprechend aufgerufen werden:
wp --info
Die Ausgabe hat sich hoffentlich nicht geändert.
So rufst du WP-CLI auf
Der Aufruf ist ja oben schon zu sehen, nur wird hinter wp dann noch ein Kommando und ggf. ein Unterkommando angehangen. So kannst du z.B. mit
wp comment list
alle Kommentare in deinem Blog auflisten lassen. Voraussetzung ist allerdings, dass du dieses Kommando innerhalb deiner WordPress-Instanz aufrufst (also dort, wo wp-login.php liegt oder tiefer im Verzeichnisbaum). Ansonsten kann ja WP-CLI schlecht wissen, auf welcher WordPress-Instanz es arbeiten soll.
Alternativ kannst du auch den Pfad zur WordPress-Instanz angeben:
wp --path=/var/www/example.org/htdocs/ comment list
Hier gehe ich davon aus, dass dein WordPress unter /var/www/example.org/htdocs/ liegt.
Multisite
Wenn du eine Multisite-Installation hast, wirst Du merken, dass du z.B. bei wp comment list nur die Kommentare des ersten Blogs angezeigt bekommst. Hier weiß WP-CLI nicht, welches Blog gemeint ist, da ja beide dieselbe WordPress-Installation und Datenbank besitzen.
Um eine bestimmte Site einer Multisite zu selektieren, musst du daher noch den --url-Parameter benutzen:
wp comment list --url=http://site2.example.org
Damit werden dann die Kommentare von site2.example.org aufgelistet. Dies gilt entsprechend für alle anderen Kommandos.
Die eingebaute Hilfe
WP-CLI hat eine ganze Menge von Kommandos und Unterkommandos. Hinzu kommen individuell noch diverse Parameter. Damit man sich das nicht alles merken oder dauernd nachschlagen muss, gibt es eine eingebaute Hilfe. Diese erreichst du, indem Du einfach
wp help
eingibst. Dies listet alle Kommandos und globale Parameter auf. Mit einem wp help <kommando> wird dann die Hilfe und die Unterkommandos zum entsprechenden Kommando ausgegeben und mit wp help <kommando> <unterkommando> dann die Beschreibung des Unterkommandos.
WP-CLI aktualisieren
Um WP-CLI zu aktualisieren, kannst du WP-CLI selbst nutzen, indem du
wp cli update
aufrufst. Stelle aber sicher, dass du das wp-Kommando auch schreiben kannst. Wenn du es global als root installiert hast, musst du wp cli update auch als root aufrufen, dann allerdings noch den Parameter --allow-root anhängen. Generell weigert sich WP-CLI nämlich, als root zu laufen.
Um herauszufinden, welche Version du installiert hast, kannst du wp cli version aufrufen. Um zu prüfen, ob ein Update bereitsteht, nutzt du wp cli check-update.
WordPress installieren
Um WordPress zu installieren, brauchst du
- eine schon eingerichtete Datenbank (also Datenbankname, Benutzername und Passwort)
- einen eingerichteten Web-Server, der auf das Verzeichnis zeigt, wo du WordPress installieren willst
Wechsel dazu in das Verzeichnis, wo WordPress installiert werden soll. WordPress kann dann in 3 einfachen Schritten installiert werden (auch einfach zu automatisieren):
1. WordPress herunterladen
Rufe folgenden Befehl auf, um WordPress herunterzuladen:
wp core download
Dies lädt die aktuellste Version von WordPress herunter. Willst Du eine andere Version herunterladen, kannst Du optional noch ein --version=<version> anhängen. <version> ersetzt du dabei durch die gewünschte Version, also z.B. wp core download --version=3.9.1.
Das lädt allerdings die englische Version von WordPress herunter. Willst du stattdessen die deutsche Version nutzen, muss noch der --locale-Parameter angehangen werden:
wp core download --locale=de_DE
Oder im Falle der Sie-Version:
wp core download --locale=de_DE_formal
2. WordPress konfigurieren
Als nächstes muss WordPress konfiguriert werden, also die wp-config.php geschrieben werden. Dazu gibt es den Befehl wp core config.
Diesen rufst du in der Basis-Version wie folgt auf:
wp core config --dbname=wp_database --dbuser=wp --dbpass=securepswd
Dies konfiguriert die Datenbank mit den angegebenen Werten (die du natürlich ersetzen solltest). Zudem werden automatisch die Salts generiert. Auch wird geprüft, ob die Datenbank mit den angegeben Daten ansprechbar ist.
Ich persönlich würde die weitere Konfiguration mit einem Texteditor vornehmen. Manchmal ist es aber hilfreich, dies auch über ein Kommando erledigen zu können (Stichwort wieder Automatisierung). Dazu kann man weitere Konfigurationsdirektiven über das Flag --extra-php übergeben:
wp core config --dbname=testing --dbuser=wp --dbpass=securepswd --dbprefix=myprefix_ --extra-php <<PHP
define( 'WP_DEBUG', true );
PHP
In diesem Fall setze ich zusätzlich zum Debug-Modus auch noch den Tabellenprefix (immer eine total gute Idee).
3. WordPress-Installation abschliessen
Jetzt haben wir also die Dateien am richtigen Ort und die Konfigurationsdatei geschrieben. Wir könnten jetzt schon auf per Web-Browser auf die Instanz zugreifen und den Installations-Wizard durchlaufen. Müssen wir aber nicht, denn wir können auch dies über die Kommandozeile erledigen:
wp core install --url=example.org \
--title="Titel der Website" \
--admin_user=dont_call_me_admin \
--admin_password=sicheres_passwort_0815_4711 \
--admin_email=my_email@example.org
Ich denke mal, das die Parameter hier selbsterklärend sind. Wer im übrigen keine Benachrichtigungs-E-Mail erhalten will, kann diese mit --skip-email unterdrücken.
Und damit haben wir eine voll funktionsfähige WordPress-Instanz aufgesetzt. Bislang natürlich ohne spezielles Theme und Plugins. Das kommt daher gleich dran. Vorher noch ein Wort in Sachen Sicherheit.
WordPress aktualisieren
Jeder weiß hoffentlich, wie wichtig es ist, WordPress auf dem aktuellsten Stand zu halten. Dankenswerterweise hilft auch hier WP-CLI. Um WordPress zu aktualisieren, ruft du folgenden Befehl auf:
wp core update
Dies lädt die aktuellste Version herunter und installiert diese. Dies installiert sowohl Unterversionen als auch Hauptversionen. Letztere allerdings will man ggf. vorher testen. Von daher empfiehlt es sich bei einer Automatisierung (z.B. via Cronjob), die Aktualisierungen auf Unterversionen einzuschränken. Dies geht mit
wp core update --minor
Manchmal will man außerdem eine spezielle Version installieren. Dies kannst du mit
wp core update --version=4.4.2
tun. Wenn die Versionsnummer kleiner als die installierte Version ist, musst du zudem --force benutzen, da WP-CLI dich das sonst nicht tun lässt.
Du kannst auch den Namen eines ZIP-Files angeben, wenn Du WordPress schon heruntergeladen hast:
wp core udpate latest.zip
Eventuell muss dann noch die Datenbank aktualisiert werden. Dies kannst du mit folgendem Befehl tun:
wp core update-db
Plugins mit WP-CLI verwalten
Nun also zu den Plugins. Hier kann man mit WP-CLI die komplette Verwaltung vornehmen, also Installation, Aktualisierung, Aktivierung usw. Das ist auch ungemein hilfreich, wenn man nicht mehr ins Web-Backend reinkommt.
Plugins installieren, aktivieren und löschen
Der erste Schritt ist wohl die Installation von Plugins. So kannst du mit dem Befehl
wp plugin install w3-total-cache
das Plugin W3 Total Cache installieren. Als nächstes kannst du es mit
wp plugin activate w3-total-cache
aktivieren. Oder aber du tust dies in einem Schritt mit
wp plugin install --activate w3-total-cache
Deaktivieren geht entsprechend mit deactivate. Es gibt auch noch toggle, welche diesen Status immer umschaltet, ich finde aber eine explizite Angabe meist sinnvoller.
Bleibt die Frage, welchen Namen man denn beim Plugin angeben muss. Und zwar ist dies der sogenannte slug (hier w3-total-cache). Dies ist der Teil der URL der Plugin-Seite des WordPress-Plugin-Verzeichnisses:
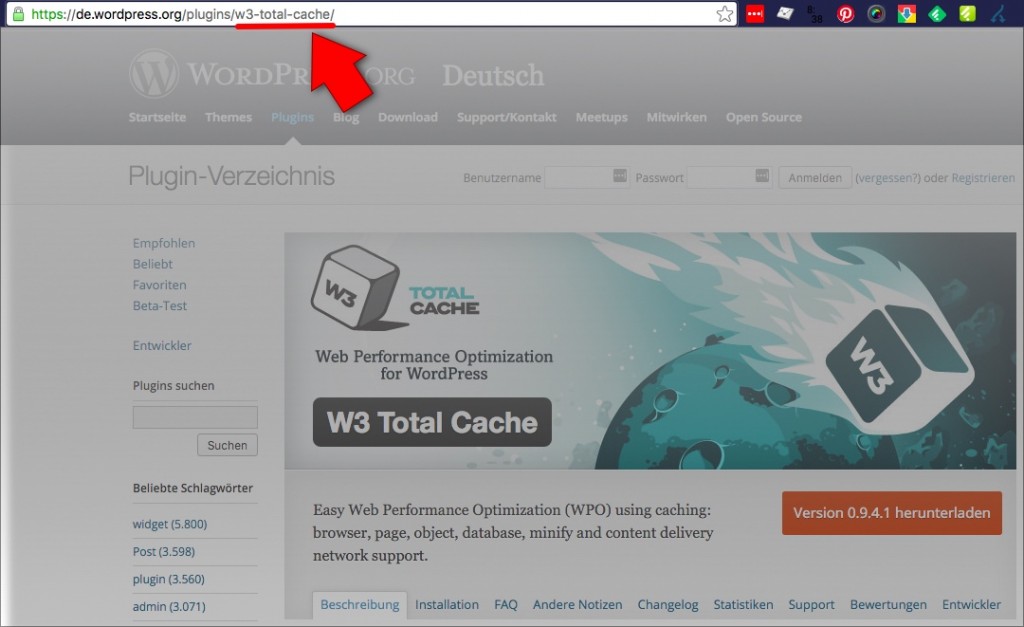
Wie man den Plugin-Slug für WP-CLI findet
Du kannst auch Plugins installieren, die nicht im WordPress-Verzeichnis vorhanden sind (z.B. kommerzielle Plugins). Dazu ersetzt du den Plugin-Slug einfach durch den Namen oder die URL eines ZIP-Files:
wp plugin install my-super-commercial-plugin.zip
wp plugin install https://example.org/plugins/my-super-commercial-plugin.zip
Plugins löschen
Löschen kannst du ein Plugin natürlich auch wieder. Das machst du wie folgt:
wp plugin deactivate w3-total-cache
wp plugin uninstall w3-total-cache
Man kann auch das wieder zusammenfassen:
wp plugin uninstall --deactivate w3-total-cache
Alle Plugins deaktivieren
Wenn mal nichts mehr geht, ist eine der Ratschläge, einfach mal alle Plugins zu deaktivieren. Das ist natürlich schwerlich im Web-Interface zu erledigen, wenn nichts mehr geht. Wer WP-CLI hat, ist da klar im Vorteil, denn hier geht es einfach mit
wp plugin deactivate --all
Wie man alle Plugins wieder aktiviert, wird dem Leser als Hausaufgabe überlassen.
Plugins suchen
Nach Plugins suchen kannst du ebenfalls (z.B. um den Slug herauszufinden). Willst du z.B. ein SEO-Plugin installieren, kann der folgende Befehl helfen, das richtige (oder zumindest irgendeins) zu finden:
$ wp plugin search seo
Success: Showing 10 of 1843 plugins.
+-------------------------------+-------------------+--------+
| name | slug | rating |
+-------------------------------+-------------------+--------+
| SEO | seo-wizard | 76 |
| SEO Ultimate | seo-ultimate | 78 |
| WordPress SEO Comments Plugin | blog-comments-seo | 88 |
| Link to us - SEO Widget | link-to-us | 100 |
| SEO by SQUIRRLY™ | squirrly-seo | 90 |
| WP Meta SEO | wp-meta-seo | 90 |
| SEO Post Content Links | content-links | 98 |
| SEO Plugin LiveOptim | liveoptim | 88 |
| Yoast SEO | wordpress-seo | 80 |
| The SEO Framework | autodescription | 100 |
+-------------------------------+-------------------+--------+
Um die nächsten 10 Einträge einzusehen, kannst du die Option –page=2 nutzen. Du kannst die Anzahl der Ergebnisse pro Seite mit Hilfe von --per-page=50 ändern.
Weiterhin kannst du die angezeigten Felder mit Hilfe des --fields-Parameters bestimmen. Gebe wp help plugin search ein, um eine komplette Liste der Felder zu erhalten.
Wenn du dieses Kommando in einem Script verwendest, willst du vielleicht auch ein anderes Ausgabeformat wählen. Dies kannst du mit --format tun, wobei man zwischen table, csv, json, count und yaml wählen kann. Sortieren (z.B. nach Rating) geht aber leider nicht.
Hier ein weiteres Beispiel:
$ wp plugin search seo --format=csv --per-page=2 --fields=name,slug,tested
Success: Showing 2 of 1843 plugins.
name,slug,tested
SEO,seo-wizard,4.5.1
"SEO Ultimate",seo-ultimate,4.3.3
Beachte, dass hier noch eine Zeile mit Success angezeigt wird, was bei der Nutzung in einem Script vielleicht stören könnte. Willst du solche Meldungen unterbinden, musst du noch --quiet als Parameter anhängen. Gerade in Scripts macht diese Funktion wohl auch am ehesten noch Sinn, denn ansonsten sind Plugins wohl einfacher über das Web zu finden.
Plugins auflisten
Um herauszufinden, welche Plugins überhaupt installiert sind, kannst Du wp plugin list aufrufen:
$ wp plugin list
+-------------------------------------+----------+-----------+----------+
| name | status | update | version |
+-------------------------------------+----------+-----------+----------+
| above-the-fold-optimization | inactive | none | 2.3.14 |
| advanced-custom-fields | active | none | 4.4.7 |
| amp | active | none | 0.3.2 |
| antispam-bee | active | none | 2.6.8 |
...
Plugins aktualisieren
Eine sehr hilfreiche Funktion von WP-CLI ist es, Plugins per Script aktualisieren zu können. Dies hat den Vorteil, dass die WordPress-Dateien einen anderen Besitzer als den Web-Server haben können. Somit kann ein Angreifer diese auch nicht ändern. wenn er „nur“ Zugriff auf das Web-Interface hat.
Zunächst aber will man wahrscheinlich den Status seiner Plugins erfahren. Dazu rufst du folgendes auf:
$ wp plugin status
5 installed plugins:
I above-the-fold-optimization 2.3.14
A advanced-custom-fields 4.4.7
A amp 0.3.2
A antispam-bee 2.6.8
UA fb-instant-articles 2.9
...
Anhand der ersten Spalte siehst du dann, dass above-the-fold-optimization nur installiert, aber nicht aktiviert ist, die drei nächsten auch aktiviert sind und fb-instant-articles ein Update braucht.
Dieses kannst du dann mit
wp plugin update fb-instant-articles
installieren. Willst du auf eine spezifische Version aktulisieren, kannst du das mit --version=1.2.3 tun.
Du kannst auch alle zu aktualisierenden Plugins auf einmal aktualisieren:
wp plugin update --all
Themes verwalten
Wenn alle Plugins bereit sind, braucht es noch ein Theme. Ich gehe hier zunächst davon aus, dass ein bestehendes Theme installiert werden soll. Dies funktioniert ähnlich wie bei Plugins.
Theme installieren
So installierst Du ein Theme mit
wp theme install <theme>
<theme> kann dabei sein:
Du kannst das Theme dabei direkt mit --activate aktivieren oder das separat tun:
wp theme activate clean-journal
Themes aktualisieren, suchen, auflisten
Ähnlich wie bei Plugins kannst Du auch Themes aktualisieren. Dies geschieht mit
wp theme update <theme>
wobei man auch hier --all und --version wie bei den Plugins angeben kann.
Dasselbe gilt für die Kommandos list und status. Auch die entsprechen den oben beschriebenen Plugin-Kommandos.
Permalinks konfigurieren
Die Permalinks können ebenfalls mit WP-CLI verwaltet werden. Dies geht mit dem wp rewrite-Kommando. Will man die Permalink-Struktur auf /2016/04/postname ändern, so geht dies mit
wp rewrite structure '/%year%/%monthnum%/%postname%'
Dabei kannst Du auch die Kategorie- und Schlagwort-Basis setzen (wie in den Permalink-Einstellungen):
wp rewrite structure --category_base '/kat/' --tag-base '/stichwort/' '/%year%/%monthnum%/%postname%'
Die Rewrite-Rules können dann mit wp rewrite flush aktualisiert oder mit wp rewrite list aufgelistet werden.
Benutzer verwalten
Kommen wir zur Benutzerverwaltung. Will man einen neuen Autor mit Benutzername klaus und E-Mail-Adresse klaus@comlounge.net anlegen, so ruft man Folgendes auf:
wp user create klaus klaus@comlounge.net --role=author
Gibt man keine Rolle an, wird die Default-Rolle genutzt (normalerweise wohl subscriber). Weitere Parameter sind:
--user_pass=<pass> übergibt ein Passwort für den neuen Nutzer--display_name=<anzeigename> definiert den Anzeigenamen--first_name=<vorname> speichert den Vornamen--last_name=<nachname> entsprechend den Nachnamen--send_email gibt an, ob eine Mail an den neuen Benutzer gesendet werden soll oder nicht--porcelain gibt nur die Benutzer-ID zurück, sinnvoll bei einer Automatisierung
Benutzer wieder löschen geht mit
wp user delete klaus
Will man dabei die Artikel des Benutzers an einen anderen Benutzer „übergeben“, so geht dies mit --reassign=<user_id>.
Dazu braucht man natürlich die ID, die man mit Hilfe der Benutzerliste herausbekommt:
wp user list
Auch hier gibt es wieder viele hilfreiche Parameter, wie z.B.
--role=<rolle> zeigt nur die Benutzer mit der angegebenen Rolle an--format=<format> definiert das Ausgabeformat (table, csv, json, count, yaml)
Datenbank verwalten
Wenn es um die Datenbank geht, ist ja zunächst mal ein Export (z.B. für ein Backup interessant). Das geht mit
wp db export
Praktischerweise muss man hier keinen Benutzernamen und Passwort angeben, da dies ja schon in der wp-config.php konfiguriert ist. Nach Ausführung des Kommandos liegt eine SQL-Datei mit dem Namen <dbname>.sql im aktuellen Verzeichnis. Willst du sie an einen anderen Ort exportieren, kannst du den Pfad dorthin angeben:
wp db export /tmp/export.sql
Das Importieren der Datenbank ist dann ebenfalls recht einfach möglich:
wp db import /tmp/import.sql
Praktisch ist manchmal auch, einfach einen Datenbank-Prompt zu haben. Dies geht ganz einfach mit
wp db cli
Weitere Kommandos können die Datenbank optimieren, reparieren usw. Weiteres findest du mit Hilfe von wp help db heraus.
Kommentarverwaltung mit WP-CLI
Spätestens, wenn sich Tausende bis Milliarden von Spam-Kommentaren angesammelt haben, wünscht man sich einen Weg, diese relativ flott löschen zu können. Das Web-Backend ist dabei nur leider alles andere als flott und kann das Lösch-Glück ggf. mit einem Timeout ins Gehege kommen. Abhilfe schafft auch hier wieder WP-CLI:
wp comment delete $(wp comment list --status=spam --format=ids)
Hier arbeiten sogar 2 Kommandos zusammen: Mit wp comment list werden alle Kommentare angezeigt, die den Status spam haben. Der Parameter --format=ids definiert, dass nur die IDs ausgegeben werden. Diese werden dann von wp comment delete als Eingabe genutzt.
Für die normale Kommentar-Moderation ist die Kommandozeile wahrscheinlich eher schlecht geeignet, für Batch-Operationen wie oben bietet sie sich aber definitiv an. Gerade wegen der Timeouts.
Suchen und Ersetzen
Wer schon einmal eine WordPress-Instanz umziehen musste, wird sich darüber gefreut haben, dass das Meiste an Konfiguration in der Datenbank und nicht etwa in Konfigurationsdateien abgelegt wird. Will man also die URL der Site ändern, ist das nicht so einfach möglich und mit vielen Plugins dennoch oftmals manuelle Arbeit.
Einfacher ist da mal wieder die Kommandozeile. Bei WP-CLI gibt es daher das passende Kommando:
wp search-replace live.example.org dev.example.org
In diesem Beispiel werden alle Vorkommen von live.example.org durch dev.example.org ersetzt. WP-CLI handhabt dabei ebenfalls von PHP serialisierte Daten.
Wer dem Suchen und Ersetzen erstmal nicht so traut, der kann sich mit Hilfe von --dry-run ausgeben lassen, wie viele Vorkommnisse in welcher Tabelle denn geändert werden würden:
$ wp search-replace live.example.org dev.example.org
+------------------+-----------------------+--------------+------+
| Table | Column | Replacements | Type |
+------------------+-----------------------+--------------+------+
| wp_options | option_name | 1 | SQL |
| wp_options | option_value | 15 | PHP |
| wp_users | user_email | 4 | SQL |
+------------------+-----------------------+--------------+------+
In dieser Ausgabe sieht man jetzt z.B., dass der Such-String auch in E-Mail-Adressen vorkommt. Diese will man wahrscheinlich nicht ändern und zum Glück kann man das search-replace dabei auf bestimmte Tabellen (wie wp_options) einschränken. Dazu gibt man einfach die gewünschten Tabellen noch am Ende an:
wp search-replace live.example.org dev.example.org wp_options wp_irgendwas ...
Allerdings muss man sich dazu schon ein bisschen auskennen oder sollte zumindest noch einmal sicherstellen, dass man ein Backup hat (das macht ihr doch eh immer, oder?). Ansonsten ist ein wp db export ja schnell gemacht.
Multisite
Bei einer Multisite ist natürlich noch mehr zu beachten, z.B. dass man das Suchen und Ersetzen auf den richtigen Sites durchführt. WP-CLI arbeitet daher zunächst auf der Standard-Site oder der durch den --url-Parameter angegeben Site. Mit Hilfe von --network kannst du das Suchen und Ersetzen aber auf allen Sites gleichzeitig durchführen.
Plugins und Erweiterungen für WP-CLI
WP-CLI beinhaltet schon recht viele Kommandos. Mehr ist aber immer besser und daher kann WP-CLI mit Hilfe von Plugins erweitert werden. Mehr noch: Manche Plugins, wie W3 Total Cache haben schon Support für WP-CLI eingebaut. Hast du also W3 Total Cache und WP-CLI installiert, kannst Du mit
wp total-cache flush
den Cache von der Kommandozeile aus leeren. Die Liste aller Kommandos erhält man dabei wie beschrieben mit wp help.
Wenn du wissen willst, welche andere Plugins WP-CLI-Unterstützung haben oder welche gar nur neue Befehle bereitstellen, dann kannst du das im Tool-Verzeichnis nachsehen.
Packages
Es gibt aber nicht nur Plugins, sondern auch noch sogenannte Packages. Diese sind im Gegensatz zu Plugins nur in WP-CLI aktiv. Sie werden daher vom Web-Frontend gar nicht erst geladen und sind auch nicht von WordPress selbst abhängig. D.h. sie können auch ausgeführt werden, wenn WordPress noch gar nicht aktiv oder defekt ist.
Eine Liste der verfügbaren Packages gibt es im Package-Index oder über die Kommandozeile selbst:
wp package browse
Installiert wird ein Package wie folgt:
wp package <package_name>
Ein Beispiel wäre:
wp package install petenelson/wp-cli-size
Danach gibt es dann ein neues Kommando namens wp size:
wp size database
Artikel-Revisionen verwalten
Ähnlich wie zu viele Spam-Kommentare in der Datenbank können auch zu viele Artikel-Revisionen WordPress ausbremsen. Doch wie löscht man die nicht mehr benötigten Revisionen alle auf einmal? Hier kommt das Plugin wp-revisions-cli zum Einsatz. Ein Problem nur: Es existiert nur als Source-Code-Repository auf github und nicht im WordPress-Plugin-Verzeichnis.
Was also tun?
Wie oben beschrieben, kann man Plugins auch aus einem ZIP-File installieren. Weiterhin muss diese Datei gar nicht lokal vorliegen, sondern kann auch per URL referenziert werden. Die URL bekommt man dabei von github, denn dort wird das Repository auch als ZIP-Datei bereitgestellt:
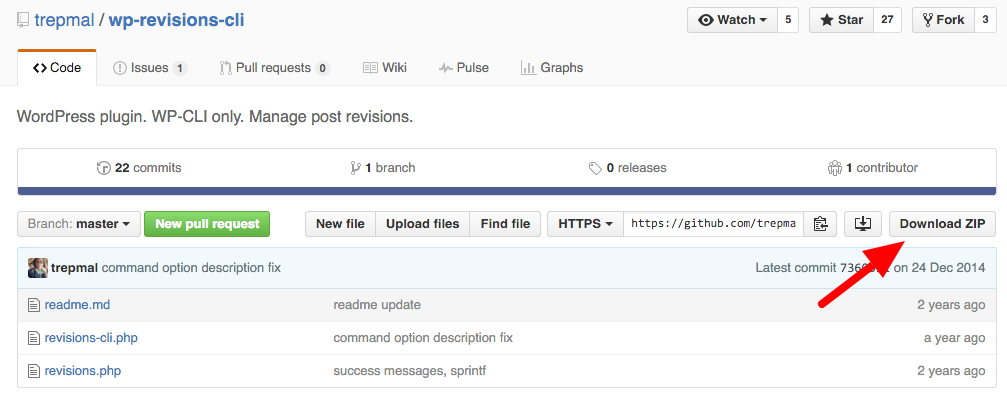
Download-Link zum WP-Revisions-Plugin
Mit einem Rechtsklick kann man dann die URL des Links kopieren und dann das Plugin damit installieren:
wp plugin install --activate https://github.com/trepmal/wp-revisions-cli/archive/master.zip
Dies installiert und aktiviert das Revisions-Plugin. In WordPress selbst sieht man außer dem Plugin in der Plugin-Liste nichts davon, denn es stellt nur ein WP-CLI-Kommando bereit.
Nun, da das Plugin installiert ist, kann du mit wp help revisions die vom Plugin bereitgestellten Unterkommandos ansehen.
Revisionen ansehen
Alle gespeicherten Revisionen kannst du mit
wp revisions list
auflisten lassen. Das sind wahrscheinlich recht viele, so du die maximale Anzahl von anzulegenden Revisionen nicht in wp-config.php eingeschränkt hast (das kannst du z.B. mit wp revisions status prüfen). Mit Hilfe von --post_id= und --post_type= kannst du die Liste aber entsprechend auf einen Artikel oder einen Artikeltyp einschränken.
Revisionen löschen
Eigentlich wollten wir Revisionen aber ja löschen. Hier gibt es gleich zwei Kommandos: clean und dump.
Der Unterschied zwischen den Kommandos ist, dass dump einfach alle Revisionen komplett löscht, während man bei clean mehr Kontrolle hat. Mit wp revisions dump sind also einfach alle Revisionen weg.
Will man aber noch 5 Revisionen behalten und nur alle älteren löschen, dann kann man das mit
wp revisions clean 5
tun. Optional kann man auch wieder die oben schon beschriebenen Parameter --post_id und --post_type angeben, um nur einen Artikel oder einen Artikel-Typ zu behandeln.
Es gibt noch viel mehr…
Obwohl der Artikel schon recht lang ist, gibt es in WP-CLI natürlich noch viel mehr. Ich werde den Artikel also ggf. noch erweitern. Wer selbst noch ein bisschen stöbern will, kann dies aber natürlich mit wp help tun.
Und wenn ihr WP-CLI schon nutzt, wäre ich an interessanten Anwendungsfällen in den Kommentaren sehr interessiert.
Wer schon immer mal wissen wollte, wo genau sich denn welche Baustellen in Aachen befinden, der konnte bislang nur die lange Liste der Stadt Aachen durchforsten. Doch viel besser wäre es doch sicher, das mal auf einer Karte anzuschauen.
Der Import der Baustellen
Das geht jetzt auch, denn wir haben uns die Liste mal genommen und mit einer Kartenanwendung versehen, die unter baustellen.offenes-aachen.de zu finden ist. Grundlage ist die oben genannte Liste, die wir leider bislang noch per Hand abtippen müssen. Das soll sich zwar irgendwann einmal ändern, wenn die neue Datenbank-Anwendung für diese Baustellen eingeführt wird, die wohl auch einen Export haben soll. Da uns das aber irgendwie zu lange dauert, haben wir das einfach schonmal selbst umgesetzt.
Die Anwendung selbst bietet im Moment nur die Basisfunktionen, man kann aber zumindest zwischen Baustellen unterscheiden, die nur auf Gehwegen stattfinden (wie Glasfaser-Ausbau) oder aber auch auf der Fahrbahn. In Kürze wird es zudem noch einen Export der Daten geben und wir arbeiten an einem Editor, um die Baustellen noch genauer einzeichnen zu können (soweit dies aus der Baustellen-Liste ersichtlich ist). Und auch eine mobile Version ist in Arbeit (vielleicht machen wir auch eine App draus).
Nicht alle Baustellen sind im Moment übrigens richtig platziert. Dies werden wir mit dem Editor dann beheben. Die Automatisierung hat bei den vorhandenen Daten leider ihre Grenzen.
Wer den Source-Code einsehen will, der kann auch dies tun, indem er einfach diesem Link folgt. Dort ist auch eine CSV-Datei der aktuellen Daten mit Stand 22.4.2013 zu finden.
Und mit diesem Blogpost ist dann auch unser neues Blog eröffnet, dass als Fokus hoffentlich auch viel Technik haben wird 🙂 (und alle weiteren Einstellung, Plugins usw. kommen dann nach der re:publica dran).
Website: baustellen.offenes-aachen.de
Update: Inzwischen hat die Stadt Aachen eine offizielle Schnittstelle implementiert und wir haben die Anwendung aktualisiert, so dass wir diese Schnittstelle nutzen. Kein Abtippen mehr und damit eine bessere Datenqualität sind die Folge. Außerdem ein gutes Beispiel, was man machen kann, wenn öffentliche Institutionen Ihre Daten offenlegen.
Am letzten Wochenende war es wieder soweit: Das PythonCamp 2016 in Köln fand statt, jetzt schon zum 6. Mal, wenn ich mich richtig erinnere.
Wie immer habe ich viele bekannte Gesichter gesehen (teilweise nach Jahren mal wieder) und auch neue getroffen. Sogar ein paar Barcamp-Neulinge waren dabei. Geographisch waren die am weitesten gereisten wohl aus München und der Schweiz.
Nicht mehr selten auf einem PythonCamp: JavaScript
Thematisch ist es schon interessant zu beobachten, wie es nicht mehr nur um Python alleine geht. Die Zeiten, wo man rein mit einer Sprache alles erledigen kann, sind ja schon etwas länger vorbei – vor allem im Web-Bereich. Natürlich kam auch Django (z.B. in der Session zu Wagtail) noch vor, aber wenn es um Web geht, dann geht es natürlich auch um JavaScript oder Deployment generell. Und tatsächlich war ich wohl meist in Nicht-Python-Sessions.
Eine dieser Sessions, wo es dann um JavaScript ging, war die von Timo Stollenwerk, wo er auf JavaScript-Bundling einging oder die Frage diskutierte, ob man sich nun Angular 2 oder React .js ansehen sollte. Auch Ember.js wurde genannt, hatte aber scheinbar nicht so viele Fans.
In Sachen Bundling ging er kurz auf die Historie ein, wie man damals grunt als Taskrunner und Bower als Package-Manager genutzt hat (damals ist in JavaScript allerdings gar nicht mal sehr lange her). Inzwischen ist er persönlich bei npm und webpack gelandet, wobei aber auch rollup.js interessant sei.
Der Vorteil zur grunt/bower-Kombo: Die Abhängigkeiten werden automatisch aufgelöst und es ist viel weniger an Konfiguration zu schreiben. Dank tree-shaking wird sogar auch nur das in das Bundle eingebaut, was man wirklich auf der HTML-Seite nutzt. Weiteres dazu in der Session-Doku.
Die Framework-Frage
„Welches Framework soll ich denn nun nutzen?“ war dann die zweite Fragestellung der Session. Und die Antwort dazu lautet natürlich wie immer: Es kommt drauf an.
Auf Twitter kam z.B. dieses Reply:
@mrtopf that should be an easy answer, if the person tells you his/her favourite python fw first 🙂
— Balázs Reé (@reebalazs) April 2, 2016
So ähnlich hat das auch Timo beschrieben. Wenn jemand die Zope Component Architecture (ZCA) von Zope 3 mag, mag er wahrscheinlich auch Angular 2. Ansonsten sei React.js natürlich auch keine schlechte Wahl, vor allem, wenn man näher an der eigentlichen Programmiersprache bleiben will. Alles also eine Frage des Geschmacks (wenn man mal React Native usw. unbeachtet lässt).
Personen, die ZCA lieben, nutzen auch: Angular 2
Timo Stollenwerk testet ein Ansible-Playbook, das Jenkins in Docker installiert
Testen, testen, testen!
Timo hat direkt weitergemacht mit einem seiner Lieblingsthemen, nämlich dem Testen. Hier hat er ein paar Beispiele gezeigt, wie er z.B. eine Solr-Konfiguration testet oder aber ein Ansible-Playbook, welches Jenkins in Docker installiert. Für ersteres hat er pytest genutzt, für letzteres Robot Framework.
Robot Framework wird dabei meist genutzt, wenn es um Akzeptanz-Tests und Behaviour Driven Development geht.
Eine Besonderheit ist bei diesem Testing-Tool, dass man keyword-basierte Test-Szenarien entwickeln kann. Wenn man z.B. das Selenium2-Modul nutzt, kann ein Test so aussehen:
Valid Login
Open Browser To Login Page
Input Username demo
Input Password mode
Submit Credentials
Welcome Page Should Be Open
[Teardown] Close Browser
Das Gute daran: Man muss kein Programmierer sein, um solche Tests schreiben zu können.
Zum Ende der Session ging es dann noch um Testing-Tools speziell für Django. Eine Linkliste dazu findet man in der Session-Doku.
Docker, Web-Security, Fitness und vieles mehr
Weitere Sessions drehten sich z.B. um Web-Security. Dies war zwar mehr ein Einführungskurs, ist aber natürlich dennoch hilfreich, wenn man gerade mit Web-Entwicklung beginnt. So wurden hier vor allem CSRF und XSS im Detail beschrieben und wie man seine Seiten in Bezug auf diese Aspekte absichert.
Auch eine Einführungs-Session in Docker gab es, die von Martin Christen und Florian Macherey gehalten wurde. Das habe ich auch gefilmt (die Slides dazu gibt es hier).
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Docker-Session beim PythonCamp 2016 in Köln from Christian Scholz on Vimeo.
PythonCamp 2016 Sessionplan
Barcamptools-Einsatz
Das PythonCamp ist wahrscheinlich der Event, der die von uns entwickelten Barcamptools am intensivsten nutzt. So wurde z.B. die komplette Session-Planung rein über das Tool online abgewickelt.
Ich persönlich denke zwar, dass man es dennoch offline machen sollte, da sich so jeder selbst einen Slot suchen kann. Danach kann man es dann online übertragen. Dennoch ist es gut zu wissen, dass auch die reine Online-Variante funktioniert.
Der Vorteil des Online-Sessionplans ist ja auch, dass die Session-Etherpads direkt verlinkt sind. So hat an sich niemand mehr eine Ausrede, keine Session-Notizen zu schreiben.
Wer also Interesse hat, kann die Session-Dokus vom Samstag hier und vom Sonntag hier einsehen.
Ein weiterer Vorteil der intensiven Nutzung ist außerdem, dass ich mir jetzt überlegen kann, wie ich diese Doku am besten für die Nachwelt präsentiere.
Danke also auch an die Orga für diese Möglichkeit!
Auch ein paar Bugs und Verbesserungen sind offensichtlich geworden. So können die Etherpad-Titel teilweise zu lang werden und der Status „Ich komme vielleicht“ ist zu verwirrend. Letzterer wird also demnächst wohl wegfallen. Stattdessen plane ich dann eine Möglichkeit, einen externen Newsletter einzubinden.
Es gibt also wie immer noch viel zu tun bis zum nächsten Jahr!
Zum Schluß möchte ich noch einmal vor allem dem Orga-Team und natürlich auch allen Teilnehmern für ein wieder mal gelungenes Barcamp danken! Bis zum nächsten Jahr!
Vielen Dank an die Sponsoren!











Das PythonCamp 2016 in Bildern
Wie (fast) jedes Jahr war ich mal wieder auf dem Barcamp Ruhr und was soll man sagen: Toll wie immer! (auch wenn an das erste Barcamp, auf dem man war, natürlich nichts rankommt).
Eigene Session: twitch.tv
Diesmal habe ich sogar auch mal wieder eine Session vorbereitet bzw. aktualisiert, da ich sie auch schon beim GMKCamp letztes Jahr gehalten habe. Es ging um die wohl größte Livestreaming-Plattform, die es meines Wissens gibt, nämlich Twitch.tv und welche sich auf Gaming spezialisiert hat. Kanäle können da auch schonmal 100.000 oder mehr gleichzeitige Viewer haben. Wenn man wissen will, was die Jugend so macht und wo das Entertainment jenseits von YouTube so hingeht, sollte das auf dem Schirm haben.
Ich habe die Präsentation auch mal auf Slideshare hochgeladen und hier ist sie zu sehen:
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Weitere Informationen
Twitch-Einführung vom Barcamp Ruhr 9 from Christian Scholz
Leider hat es das Video nicht in die Präsentation geschafft, daher kommt das hier noch separat. Es handelt sich um einen kleinen Überblick, was eigentlich so auf Twitch passiert:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Snapchat

Snap-Code Christian Scholz
Dank der Session von Romy Mlinzk und Johannes Mirus weiß ich nun auch endlich, was auf Snapchat abgeht. Installiert hatte ich das schonmal, das Problem war nur, Kontakte zu finden. Snapchat gleicht ja nur das Telefonbuch ab, aber das ist leider der Ort, wo ich die wenigsten Kontakte habe (die zumindest dafür in Frage kämen). Facebook wäre da schon hilfreicher (das mag bei Jugendlichen sicherlich anders aussehen). Hinzu kommt, dass die Bedienung nicht ganz so intuitiv ist (man muss z.B. lange auf sein Gesicht klicken, damit die Gesichtsfilter aktiv werden).
Aber dank der Session habe ich nun zumindest einen groben Überblick und ein paar Kontakte mehr. Wer mich hinzufügen will, kann das mit Hilfe des Bildes rechts tun, indem man es mit Snapchat einscannt, es ist nämlich ein QR-Code (wie man jetzt das Bild noch in die Mitte bekommt, weiß ich leider nicht, aber ich bin ja noch Anfänger).
Für alles weitere über Snapchat verweise ich dann mal lieber auf das Buch „Snap me if you can“ von Philip Steuer, bevor ich hier alles falsch wiederhole, was ich in der Session gelernt habe.
Impressionen vom Barcamp Ruhr 9
Natürlich gab es auch wieder viel gutes Essen, viele gute Gespräche bis tief in die Nacht und viele andere schöne Sessions. Wer also noch nie auf einem Barcamp war, sollte auf jeden Fall mal zu einem hinfahren, eine Liste gibt es z.B. hier. Die Mailingliste für das Barcamp Ruhr gibt es hier.
Zum Schluß noch ein paar Fotos vom Barcamp:
Und last but not least natürlich noch einen Riesen-Dank an die Sponsoren des Barcamp Ruhr 9, ohne die es nicht möglich gewesen wäre!
(schön auch, dass es so manche Session von denen gab, ohne es in eine Marketing-Session zu verwandeln)






 3
3






Wer kennt das nicht? Man schreibt einen tollen Beitrag und was fehlt? Genau: Ein Titelbild. Wenn man dann nicht selbst zum Fotoapparat greifen will (wie ich das hier oft tue), stellt sich die Frage: Wie findet man passende Bilder und wie baut man diese rechtssicher in sein Blog oder seine Website ein? Und da ich gerade auf der re:publica war und dort vom Lizenzhinweis-Generator gehört habe, schien es mir sinnvoll, auf das Thema Bilder und Internet noch einmal einzugehen.
Wo finde ich Bilder?
Zunächst also die Frage: Wo finde ich Bilder? Und wie jeder weiß, lautet die Antwort: Im Internet.
Dass bei der Nutzung von Bildern aus dem Netz allerlei rechtliche Gefahren drohen, wissen dabei sicherlich auch schon viele Leute. Bekannt dürfte auch sein, dass man in solchen Fällen nach Bildern mit einer Creative Commons (CC)-Lizenz Ausschau halten sollte. Denn Bilder mit CC-Lizenz dürfen unter bestimmten Bedingungen frei verwendet werden. Eine der Quellen, wo es viele solcher CC-lizensierten Bilder gibt, ist Wikimedia Commons.
Primär dient Wikimedia Commons als Mediendatenbank für Wikipedia und angeschlossene Projekte. Da die Mediendateien dort aber nicht speziell für Wikimedia lizensiert sind, sondern eben als Creative Commons, können sie natürlich auch woanders eingebunden werden. Und mit über 31 Mio. Mediendateien ist die Auswahl nicht gerade klein.
Einzig das Finden kann ein Problem sein. Eine Möglichkeit ist, zunächst die Medienart zu wählen, und dann die entsprechende Kategorie:

Wikimedia Commons: Erst Medienart wählen
Wikimedia Commons: Dann Kategorie wählen
Wie man aber sieht, ist dies nicht die zeitgemäßeste Art, Bilder zu suchen. Moderner wäre hier ein visuelles Tool. Zum Glück gibt es das auch und es nennt sich Google.
Bezogen auf Wikimedia Commons geht das so: Will ich dort nach Robotern suchen, dann gehe ich zunächst zur Google Bilder-Suche (kommt jetzt etwas überraschend, ich weiß). Dann gebe ich zur Suche nach „robot“ Folgendes ein:
site:commons.wikimedia.org robot
site: ist dabei das Zauberwort, denn dadurch wird Google angewiesen, nur solche Ergebnisse auszugeben, die auf der Website mit dieser Domain vorkommen. Und so finden wir also schließlich viele, viele Roboter.
Wie baue ich Bilder rechtssicher ein?
Wer jetzt meint: „Super, bau ich das Bild mal einfach ein, ist ja CC-lizensiert!“ der wird sich ggf. später über eine Abmahnung freuen. Denn Bild einbauen ist nicht gleich Bild einbauen.
Wie Henning Krieg und Thorsten Feldmann in ihrem Jahresrückblick Social Media Recht 2016 auf der re:publica berichteten, soll es wohl auch Fotografen geben, die ihre Bilder auf Wikimedia Commons hochladen und es darauf anlegen, dass ein Bild falsch eingebaut wird, um diese Personen dann abzumahnen. Uncool, aber zumindest in Deutschland erlaubt.
Lizenz beachten
Damit das nicht passiert, muss man die Lizenz beachten. Das beginnt damit, dass es überhaupt die richtige Lizenz für die eigene Website ist. Bei Creative Commons kann man als Urheber nämlich seine eigene Lizenz aus einem Baukasten zusammenbauen. Und dabei kann man auch entscheiden, ob das Werk auch kommerziell oder nur nicht-kommerziell genutzt werden. Auch kann man angeben, ob es verändert werden darf.
Hast du also eine kommerzielle Website, darfst du schon keine Bilder verwenden, die nur für die nicht-kommerzielle Nutzung freigegeben sind. Willst du ein Bild in eine Collage einbauen, dann solltest du darauf achten, dass man es auch verändern darf. All dies steht in den Lizenzvereinbarungen und die Creative-Commons-Website hilft zudem dabei, die CC-Icons zu identifizieren.
Bei Wikimedia Commons scheint es nur Werke zu geben, die relativ frei sind, also auch kommerziell genutzt werden dürfen. Dennoch sollte man auf Nummer sicher gehen. Das gilt erst recht, wenn man Bilder aus anderen Quellen nutzen will. Auch hierbei kann Google wieder helfen, denn man kann Google anweisen, die Suche auf eine bestimmte Lizenz zu begrenzen.
Klickt man nämlich auf „Suchoptionen“, erscheinen weitere Sucheinschränkungen und man kann hier die gewünschten Nutzungsrechte selektieren:

Google: Nutzungsrechte selektieren
Natürlich sollte man bei einem Bild danach immer noch sicher gehen, dass es auch wirklich unter der gewünschten Lizenz veröffentlicht wurde, denn Google kann sich ja auch mal vertun.
(Im Übrigen sind auch die anderen Suchoptionen hilfreich. So hilft die Auswahl von „transparent“ unter „Farbe“ z.B. dabei, Logos mit einem transparenten Hintergrund zu finden)
Lizenzhinweis richtig einbauen
Wenn du das richtige Bild mit der richtigen Lizenz gefunden hast, bleibt noch der richtige Einbau des Lizenzhinweises. Wie oben schon erwähnt, kann man sonst abgemahnt werden (wie z.B. dieser Fall zeigt). Doch wie genau der Lizenzhinweis aussehen muss, ist vielleicht nicht immer ganz klar.
Für Wikimedia Commons kann da der auch auf der re:publica vorgestellte Lizenzhinweis-Generator helfen. Dieser funktioniert wie folgt:
- Man ruft lizenzhinweisgenerator.de auf
- Man gibt die URL einer Mediendatei auf Wikimedia Commons oder eines Wikipedia-Artikels ein
- Ist es ein Wikipedia-Artikel, zeigt der Generator alle dort verwendeten Bilder an und man selektiert das gewünschte Bild.
- Man selektiert eine Nutzungsart (Online oder Print)
- Man selektiert, ob es in einer Collage/Galerie/etc. oder einzeln verwendet werden soll
- Man gibt an, ob man es noch verändern will
Am Ende erscheint dann der fertige Lizenzhinweis in verschiedenen Formaten. Baut man diesen entsprechend ein, sollte man dann vor Abmahnungen gefeit sein.
So sieht das am Ende dann aus:
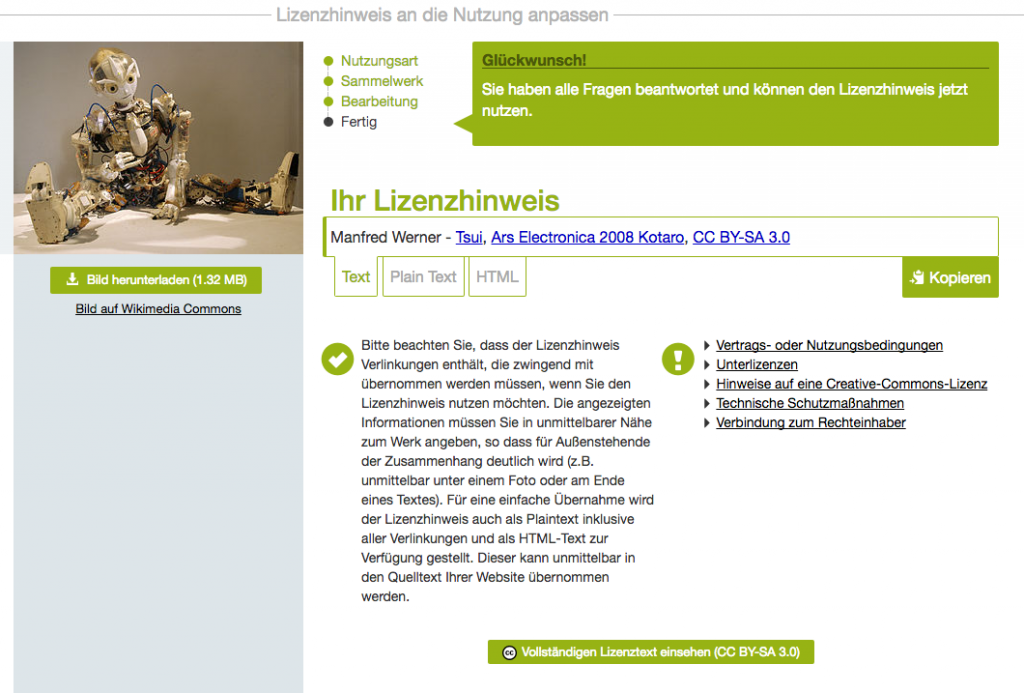
Wikimedia Commons: Nutzungsrechte für ein Roboter-Bild.
(Manfred Werner – Tsui (https://commons.wikimedia.org/wiki/File:Ars_Electronica_2008_Kotaro.jpg), „Ars Electronica 2008 Kotaro“, https://creativecommons.org/licenses/by-sa/3.0/legalcode)
Und dies ist der dafür notwendige Lizenzhinweis (der hiermit dann auch eingebaut wäre):
Fazit
Wie man sieht, ist es gar nicht so schwer, interessante Bilder für sein Blog oder seine Website zu finden. Und wenn man dennoch kein passendes Bild findet, helfen verwandte Bilder vielleicht dabei, mit etwas Kreativität doch noch ein passendes Titelbild selbst zu erstellen. Dies muss man bei abstrakteren Themen ja eh tun (z.B. beim Thema Verkehrswege-Planungsbeschleunigungsgesetz).
Und dank des Lizenzhinweis-Generators ist auch die rechtssichere Einbindung dann hoffentlich kein Problem mehr.
Bildnachweis Titelbild:
Rama; edited by user Jaybear, Leica-II-Camera-1932 cropped, Komposition von Christian Scholz, CC BY-SA 3.0
Wie letztens berichtet, hat Facebook auf der diesjährigen f8-Entwicklerkonferenz ein neues Feature präsentiert: Facebook Messenger-Bots. Zeit also, sich einmal anzuschauen, was man mit diesen Chat-Bots so machen kann. In diesem Tutorial beschreibe ich daher zunächst das Setup und anschließend eine Beispiel-Implementierung eines einfachen Bots mit Hilfe von Flask und Python. Dies in einer anderen Sprache zu implementieren sollte dabei aber kaum komplizierter sein. Alles, was du können musst, ist, einen Web-Server aufzusetzen, JSON zu verarbeiten und HTTP-Requests abzusenden. Die Facebook-Dokumentation findest du ansonsten hier.
[toc]
Was du für einen Facebook Messenger-Bot brauchst
Um einen Facebook Messenger-Bot zu implementieren brauchst du nicht viel. Hauptsächlich benötigst du einen Web-Server mit SSL-Unterstützung, auf dem der Bot dann laufen soll. Weiterhin bedarf es einer Facebook-Seite und einer Facebook-App. Es können dazu auch bestehende Seiten und Apps genutzt werden. Beides muss nicht zwangsläufig veröffentlicht sein, um den Bot damit betreiben zu können.
Die Seite dient dabei als Ankerpunkt des Bots, denn auf Facebook sendet man Nachrichten ja entweder an Personen oder an Seiten. Die App dient dazu, die notwendige Infrastruktur (wie den Webhook) bereitzustellen. Damit kann dann ein Mensch über die Seite mit deiner App und damit deinem Server kommunizieren.
Für dieses Tutorial benötigst du außerdem noch Python 3, flask und die requests-Library. Python-Kenntnisse sind sicherlich auch hilfreich. Wie oben schon gesagt, sollten die Konzept aber recht einfach auf andere Sprachen zu übertragen sein.
Python aufsetzen
Zunächst setzen wir die Server-Seite auf. Ich gehe davon aus, dass Python 3 installiert ist. Python 2.7 tut es sicherlich auch, nur die Syntax ist dann leicht anders. Zudem braucht man das venv-Paket. Wechsel dann in das Verzeichnis, in dem der Bot leben soll. Dort erstellst Du dann ein virtual environment und installierst die notwendigen Pakete:
pyvenv .
source bin/activate
pip install flask requests
Danach erstellst Du zum Testen eine einfache Flask-App mit dem Namen bot1.py. Diese dient zunächst nur zum Testen des Servers.
https://gist.github.com/mrtopf/e8604b71ac9e54370628eafa45f9b160
Danach kann man den Server mit python bot1.py starten.
Als nächstes musst du dann deinen Web-Server so konfigurieren, dass er diesen Python-Server unter einer öffentlichen URL bereitstellt. Wichtig ist dabei, dass er unter https, also verschlüsselt, erreichbar sein muss. Da dies hier ein bisschen zu weit führen würde, verweise ich dazu mal auf Google. (Dort findet man z.B. eine Anleitung für nginx mit uwsgi). Ich persönlich habe das einfach auf unserer Domain laufen lassen (denn die hat schon SSL) und unter nginx wie folgt konfiguriert:
location /testbot {
proxy_pass http://127.0.0.1:8888;
}
Wenn alles funktioniert hat, sollte der Server dann unter dem Pfad /testbot mit Hello, World! antworten.
Seite und App einrichten
Wenn du noch keine Seite hast, die du mit dem Bot assoziieren willst, musst du eine erstellen. Dies geht unter diesem Link. Der Typ dürfte egal sein, für meinen Test habe ich einfach Community genommen. Die Seite selbst muss dazu nicht veröffentlich werden, sie muss aber existieren.
Auch bei der App kann man entweder eine bestehende App nutzen oder eine neue erstellen. Dies geht mit Hilfe dieses Links. Ich habe dazu den Typ „Website“ gewählt und das sieht dann wie folgt aus:
Facebook Messenger-Bot: App erstellen
Als nächstes musst du eine Kontakt-E-Mail-Adresse angeben und die Kategorie auf „Apps für Seiten“ stellen. Test-Version bleibt ausgeschaltet. Nach Absenden des Formulars bist du an sich fertig, du kannst dann auf „Skip Quickstart“ oben rechts klicken. Danach erscheint das App-Dashbord.
Seite und App für den Facebook Messenger-Bot verknüpfen
Im App-Dashboard gibt es jetzt einen neuen Menüpunkt „Messenger“. Klickt man auf diesen zum ersten Mal, erscheint eine Info-Box, die man bestätigen muss. Danach erscheint dann folgender Screen:
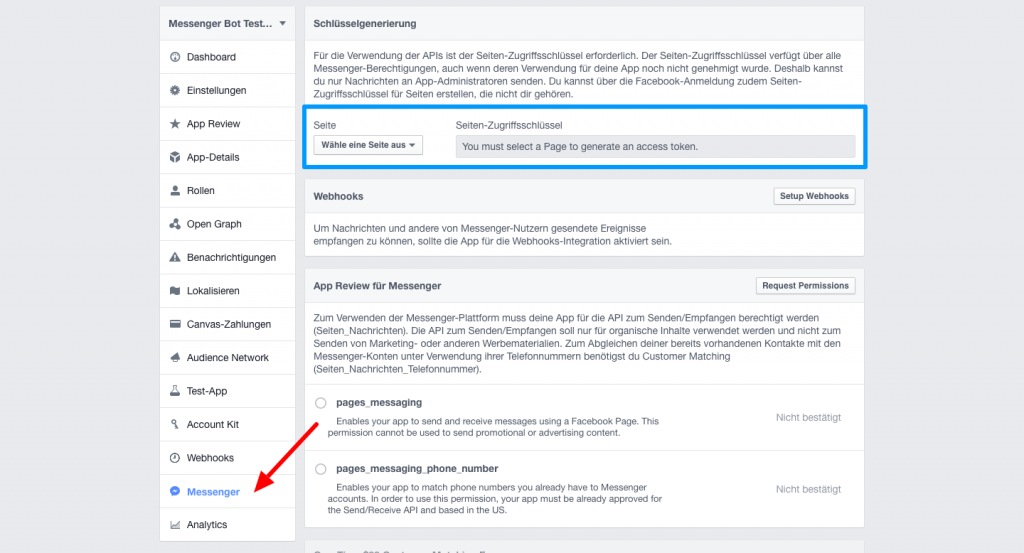
Facebook Messenger-Bot: Das App-Dashboard
Dort kannst du diese App mit der entsprechenden Seite verknüpfen. Wähle dazu in dem oberen Bereich (hier blau umrahmt) die zu verknüpfende Seite aus (ggf. gehen dabei ein paar Facebook-Popups auf, die nach weiteren Berechtigungen fragen). Ist dies geschehen, erscheint ein Access-Token neben der Seitenauswahl. Klicke darauf, um es zu kopieren. Beachte, dass dies dort nicht stehen bleibt. Wenn du es also erneut brauchst, musst du erneut die Seite auswählen und es erscheint wieder (bleibt wohl auch immer gleich).
Dieses Token wird dann im folgenden Aufruf genutzt, den du in einer Shell tätigen musst:
curl -ik -X POST "https://graph.facebook.com/v2.6/me/subscribed_apps?access_token=<token>"
Der Aufruf sollte ein {"success":true} zurückgeben.
Damit erhält dann die App Updates von der Seite (denn normalerweise empfängt ja eine Seite Chat-Nachrichten und keine App). Wenn Du das nicht tust, dann wird nie eine Nachricht an die Seite bei der App und damit bei deinem Bot/Server ankommen. Das Token ist zudem nur für genau diese App- und Seiten-Kombination gültig.
Webhooks einrichten
Damit nun die App auch Nachrichten empfängt, muss ein Webhook eingerichtet werden. Dies ist der Server-Endpunkt auf deiner Seite, wo Facebook dann die vom Benutzer empfangenen Nachrichten hinschickt.
Dazu kannst du folgendes flask-Programm nutzen, das du unter bot2.py speichern kannst.
https://gist.github.com/mrtopf/1e7f1500ae1277fd04ec8887a9bcba25
Wichtig dabei ist die Zeichenkette cd7czs87czds8chsiuh9eh3k3bcjhdbjhb. Diese kannst du selbst wählen und dient dazu, dass Facebook weiß, dass dieser Server und die App vom selben Autor kommen (also ein shared secret). Diese Zeichenkette muss sowohl in deinem Programm als auch im Webhook-Dialog eingetragen sein.
Sobald der Bot mit python bot2.py dann läuft, kannst du auf den Button „Webhooks“ im Messenger-Bereich der App klicken (nicht den Menüpunkt „Webhooks“).
Folgendes erscheint und hier trägst du dieselbe Zeichenkette wie im Script ein:
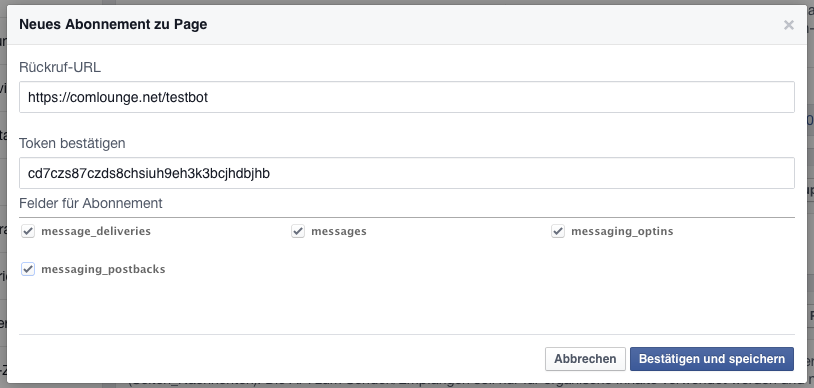
Setup der Facebook Messenger Webhooks
Am besten nutzt du natürlich ein eigenes Token. Die Berechtigungen klickst du am besten alle an.
Wenn alles funktioniert hat, sollte nach Absenden des Formulars ein „Abgeschlossen“ im Webhook-Bereich erscheinen.
Und damit haben wir jetzt die Seite und die App verknüpft sowie die App mit dem Server.
Nachrichten empfangen und senden
Das heißt, dass wir jetzt bereit sind, Nachrichten zu empfangen. Dazu braucht es natürlich noch etwas Code.
Regeln wir zunächst den Empfang. Sendet ein Benutzer nun etwas an den Bot (bzw. der Seiten-Administrator, solange der Bot noch nicht von Facebook freigeschaltet wurde), so kommt dies an dem Webhook an, der auch die Verifizierung geregelt hat. Es ist also dieselbe URL, nur ein POST- statt einem GET-Request.
Die Nachricht selbst ist JSON-kodiert und sieht bei einem „Hallo Bot!“ wie folgt aus:
https://gist.github.com/mrtopf/9c2220729a7b7cff683f290597470cff
Wichtig ist der messaging-Teil, der eine Liste von Nachrichten enthält. Diese wiederum enthalten eine Message-ID (mid), eine Sequenz-Nummer (mir ist nicht bekannt, ob die auch gemischt angekommen können), den Empfänger (die Seiten-ID) sowie den Sender als ID und einen Timestamp. Die Sender-ID ist dabei nicht die Facebook-ID des Benutzers, sondern eine eigene ID für diese Anwendung.
Mit bot3.py können wir dies nun lesen und mit einer einfachen Textnachricht antworten:
https://gist.github.com/mrtopf/91b2b3fbe970c7b4849fc77a8272a6d2
Wie man sieht, braucht man zum Senden ein Page-Token. Dies ist dasselbe Token, das man oben im curl-Befehl benutzt hat. Du findest es wie gehabt im Menüpunkt „Messenger“ im App-Dashboard ganz oben nach Auswahl der verknüpften Seite. Solange PAGE_TOKEN nicht das richtige Token enthält, wird der Bot nicht antworten.
Mit Hilfe dieses Tokens kann dann die Graph-API angesprochen werden. Der Bot sendet die Nachricht also nicht als Antwort direkt an den Webhook zurück, sondern asynchron. Dies hat den Vorteil, dass man auch später noch Nachrichten schicken kann, ohne dass der Benutzer erst wieder etwas sagen muss. Man sollte dabei nur die Facebook-Richtlinien und den gesunden Menschenverstand beachten. So dürfen z.B. keine reinen Werbenachrichten darüber versendet werden.
Das Format der Nachrichten werde ich ausführlicher in einem separaten Artikel beschreiben (zusammen mit den strukturierten Nachrichten). Im Prinzip sieht eine Text-Nachricht aber wie folgt aus:
https://gist.github.com/mrtopf/9db67af2036b9cee390df382011358c2
Die Recipient-ID ist dabei die Sender-ID aus der Anfrage.
Ein Bild senden
Ein Bild sagt mehr als 1000 Worte! Wie also sendet man ein Bild? Ironischerweise, indem man gefühlt 1000 Worte schreibt, denn der Code für ein Bild ist schon ein bisschen größer. Hier ist die Methode send_image():
https://gist.github.com/mrtopf/3b63c5eb1e43a518a5e21c9d683f352e
Diese kann man einfach in bot3.py einfügen und dann wie folgt aufrufen:
https://gist.github.com/mrtopf/936e0ddae9c4cf21b44cea60b9ad77e8
Hier wird also zusätzlich zum Text noch eine weitere Text-Nachricht und dann ein Bild gesendet. Das sieht im Messenger dann wie folgt aus:
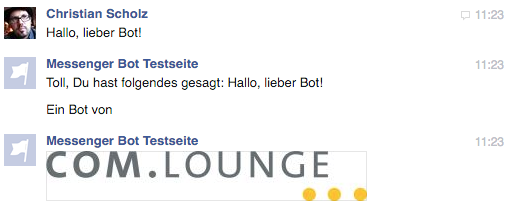
Messenger Bot Beispiel: Antwort mit Text und Bild
Die Struktur der Nachricht ist dabei so komplex, da es schon in Richtung strukturierter Nachrichten geht. Da dieser Artikel aber schon ein wenig lang ist, gibt es weitere Details und eine Beispiel-Implementierung im nächsten Artikel.
Troubleshooting
Wenn man einen Bot implementiert, funktioniert natürlich nicht immer alles. Ein paar der Probleme, die ich hin und wieder hatte und wie man diese behebt, findest du hier:
Der Bot bekommt keine Nachrichten
Wenn der Bot keine Requests bekommt, kann es sein, dass man vergessen hat, die Page-App-Verbindung herzustellen. Dazu führt man einfach den oben beschriebenen curl-Befehl mit dem Page-Access-Token aus.
Die Webhooks konnten nicht (mehr) erreicht werden
Es kann manchmal bei der Entwicklung sein, dass der Server nicht immer läuft. Facebook merkt das ggf. und beendet dann die Webhook-Verbindung. Dies sieht man dann im Menüpunkt „Benachrichtigungen“ im App-Dashboard. Der einfachste Weg, diese wieder zu aktivieren, ist eine erneute Aktivierung des Webhooks. Dazu entfernt man den bestehenden Webhook im Menüpunkt „Webhooks“ im App-Dashboard. Danach kann man den ihn mit dem Verifizierungs-Token im Menüpunkt „Messenger“, wie oben beschrieben, neu erstellen. Danach sollte wieder alles funktionieren (soweit der Server funktioniert).
Ein Fehler im Script ist aufgetreten
Hat man einen Fehler in seinem Server und antwortet dieser daher mit etwas anderem als Status-Code 200, gibt es ein kleines Timeout bei Facebook. D.h. nach Fixen des Fehlers muss man ca. 1 Minute warten, bis Facebook wieder Nachrichten an den Server schickt. Leider etwas nervig und es wäre schön, wenn unveröffentlichte Bots diese Einschränkung nicht hätten.
Ich hoffe, diese Tutorial war hilfreich. Im nächsten Artikel beschreibe ich dann, wie man strukturierte Nachrichten sendet, wie diese strukturiert sind und wie man einen Willkommens-Screen erstellt.
Bildnachweis:
D J Shin, S.H Horikawa – Star Strider Robot (スターストライダーロボット) – Front, D J Shin, QSH Tin Wind Up Mechanical Robot (Giant Easelback Robot) Side, Collage von Christian Scholz, CC BY-SA 3.0
Da wir ja mitgeholfen haben, die Bürgerbeteiligung für den Radschnellweg Euregio auf die Beine zu stellen, will ich auch darüber berichten, wie es weiterging.
Zur Erinnerung: Bei der Bürgerbeteiligung hatte jeder interessierte Bürger die Chance, Strecken für den geplanten Radschnellweg zwischen Aachen und Herzogenrath online als auch offline einzureichen. Zusammengekommen sind knapp 90 Vorschläge. Diese wurden dann von der Verwaltung und dem Planungsbüro geprüft. Das Resultat waren 3 Vorschläge pro Streckenabschnitt.
Diese Strecken sollten dann in Phase zwei der Bürgerbeteiligung in Workshops in den jeweiligen Stadtteilen vorgestellt und mit den Bürgern diskutiert werden.
Einer dieser Workshops fand gestern, am 20.4.2016 in der Städteregion statt und wir waren vor Ort, um dies zu dokumentieren. Vor Ort waren z.a. Uwe Zink (Dezernent für Bauen, Umwelt und Verbraucherschutz), Ralf Oswald (Radverkehrs-Beauftragter der Städteregion Aachen), Vertreter der Stadt Aachen sowie des zuständigen Planungsbüros, Büro Berg.
Einführung in die Thematik
Zu Beginn hat Ralf Oswald von der Städteregion in die Thematik eingeführt. So erklärt er, warum man überhaupt auf die Idee eines Radschnellwegs kommt und was genau ein solcher ist.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Was ist ein Radschnellweg
Ein Radschnellweg zeichnet sich durch die folgenden Kriterien aus:
- Ein Radschnellweg hat eine Mindestbreite von 4m. So hat man 2m pro Richtung. Dies ist genug, damit man auch noch überholen kann.
- Ein Radschnellweg hat Vorrang an Kreuzungen. Noch besser: Er ist möglichst kreuzungsfrei, was z.B. mit Tunneln oder Brücken bewerkstelligt werden kann. Wichtig ist nämlich nicht unbedingt die Geschwindigkeit auf der Strecke, sondern möglichst geringe Wartezeiten an den Knotenpunkten.
- Geringe Steigung: Auch wenn es mehr und mehr Pedelecs gibt, so sind sie doch mit 2 Mio. Pedelecs gegenüber 70 Mio. Fahrrädern in der Minderheit. Eine geringe Steigung auf der gesamten Strecke ist daher trotzdem sehr wichtig.
- Ein guter Fahrkomfort durch Asphalt erklärt sich wohl von selbst.
- Ein möglichst geringer Umwegfaktor, so dass er eben auch schnell ist.
Dabei gibt es zwei Möglichkeiten der Umsetzung:
- Ein Zweirichtungsradweg: Dieser ist 4m breit, erlaubt nur Fahrräder und die Fußgänger werden separat geführt. So kommt sich niemand in die Quere.
- Fahrradstraße: Hier wird eine normale Straße umgewidmet. Fahrräder haben auf jeden Fall vor PKW Vorrang, die Breite beträgt ebenfalls 4m. Außerdem gilt dann automatisch eine Höchstgeschwindigkeit von 30 km/h.
Herr Oswald ging zudem noch auf ein paar Fragen ein, die schon im letzten Workshop gestellt wurden:
Generell gilt, dass auf einem Radweg nur Fahrzeuge ohne Nummernschild zugelassen sind. Somit dürfen Pedelecs darauf fahren, E-Bikes aber nicht. Denn diese sind bis 45 km/h zugelassen und man ab 25 km/h braucht man ein Nummernschild.
Nach derzeitigem Stand werden wohl auch keine Naturschutzgebiete berührt (anders sieht es allerdings je nach Vorschlag mit Landschaftsschutzgebieten aus).
Eine Beleuchtung ist innerorts wegen der sozialen Sicherheit wichtig. Ob sie auch außerorts vorhanden sein wird, hängt von der Förderung ab.
Zu den Kosten gab es zu sagen: 80% trägt normalerweise das Land. Es wird jedoch gerade eine Gesetzesänderung in NRW diskutiert, wo bestimmte Abschnitte dann ggf. auch mit 100% gefördert werden können (vor allem wohl außerorts).
Der Workshop
Der Workshop selbst fand im Anschluß statt und war in verschiedene Stationen aufgeteilt. So gab es den Bereich Infrastruktur, wo verschiedene Streckenabschnitte vorgestellt wurden. Pro Streckenabschnitt gab es dann drei Tafeln:
- Den Streckenverlauf der drei Vorschläge auf einer Karte mit entsprechenden Markierungen für Brücken, Knotenpunkte usw.
- Das Steigungsprofil
- Eine Bildwand mit ausgesuchten Stellen der Vorschläge und einem Beispiel, wie der Radschnellweg dort aussehen könnte.
Weiterhin gab es einen Stand zur Potentialanalyse, die anhand eines Modells zeigt, wie viel ein solcher Radschnellweg genutzt werden könnte.
An einer weiteren Station konnte man die Auswirkungen auf die Umwelt (zu fällende Bäume, Größe der Versiegelung etc.) sehen. Zum anderen gab es eine Aufstellung der grob geschätzten Kosten der einzelnen Streckenvorschläge.
Ralf Oswald hat auch zu diesen Bereichen eine kurze Einführung gegeben:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Bürgerbeteiligung in Form von Karteikarten
An jeder Station konnten die Bürger dann mit den Moderatoren diskutieren. Weitere Fragen und Anregungen konnten auf Karteikarten festgehalten werden und nehmen Einzug in die weitere Planung im Rahmen der Machbarkeitsstudie.
Die Vorschläge wurden am Ende kurz zusammengefasst:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Der Ausblick
Zum Ende hin hat der zuständige Dezernent für Bauen, Umwelt und Verbraucherschutz, Uwe Zink, den weiteren Verlauf skizziert:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Die nächsten Veranstaltungen finden dann noch an folgenden Terminen und Orten statt:
25.04.16, 18 – 20:30 Uhr
Herzogenrath-Kohlscheid
Aula der Gesamtschule, Kircheichstraße 60, 52134 Herzogenrath
26.04.16, 19 – 21:30 Uhr
Herzogenrath-Mitte
Aula des Schulzentrums, Bardenberger Str. 72, 52134 Herzogenrath
Fazit
Ich habe mit ein paar Leuten vor Ort gesprochen und soweit scheint diese Art der Bürgerbeteiligung recht gut anzukommen.
Wichtig war vor allem, dass es kein reiner Konsultationsprozess ist, wo man einmal Input gibt, aber im Zweifel lange Zeit auf eine Reaktion warten muss. In vielen Fällen wird dann auch nicht mehr konkret auf den eigenen Vorschlag eingegangen.
Hier lief das bislang anders. Bürger konnten online und offline Strecken vorschlagen und haben auch direkt Feedback bekommen, wenn z.B. schon absehbar war, dass die Kosten zu groß wurden.
Ebenso lief es bei diesen Workshops ab. Hier gab es noch einmal die Möglichkeit, direkt mit Verwaltung und Planungsbüro in Kontakt zu treten.
Schön wäre jetzt nur noch, wenn die Strecken mitsamt aller Metadaten und vielleicht einer Kommentarfunktion auch wieder online einzusehen wären. Zwar gab es bei dem Workshop thematisch gegliederte Stände, manchmal will man jedoch vielleicht auch alles mal auf einen Blick sehen.
Aber vielleicht passiert dies ja noch, vielleicht ja auch in Form von offenen Daten. Wir haben das auf jeden Fall schonmal angeregt und werden beizeiten noch einmal nachfragen.
Alle Materialien zu den Workshops können ansonsten ab sofort auf der Website des Radschnellwegs Euregio heruntergeladen werden.
Layouts mit Cards oder Boxen sieht man ja immer noch recht viel. Man braucht dazu nur auf unsere Blog-Startseite zu schauen oder die verwandten Artikel in diesem Artikel. Je nach Inhalt haben diese Boxen dann aber gerne mal unterschiedliche Höhen. In diesem Artikel erfährst Du, wie man Boxen mit gleicher Höhe nur in CSS implementiert.
Schauen wir das Problem mal im Detail an: Nimmt man einfach eine panel-Klasse von Bootstrap, eine feste Breite und einen float:left , sieht das so aus:
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Der Code dazu:
<style>
.panel-test {
width: 30%;
padding: 20px;
float: left;
margin: 10px;
border: 1px solid #aaa;
}
</style>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist kurze Headline</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
Recht schön sieht das nicht aus (zumindest nicht, wenn dann große Löcher entstehen).
Eine Abhilfe kann hier die Definition einer festen Höhe sein. Dann muss man aber sehr genau darauf achten, dass man nicht zu viel Text schreibt, da dieser sonst aus der Box läuft oder abgeschnitten würde.
Boxen mit gleicher Höhe dank flexbox
Zum Glück gibt es ein CSS-Konstrukt, das hier Abhilfe schafft und inzwischen auch vom Großteil der Browser unterstützt wird.
Gemeint ist das flexbox-Modell (hier geht es zum Standard). Dies ist eine Layout-Methode, die Boxen innerhalb eines Containers effizient verteilen und ausrichten kann, auch wenn die Größen unterschiedlich/unbekannt sind.
Die Grundidee ist, dass Boxen innerhalb eines Containers anhand einer Achse ausgerichtet und verteilt werden. Dies kann dann mit entsprechenden Direktiven genauer gesteuert werden.
Allerdings soll dies jetzt keine komplette Einführung sein, sondern nur ein Beispiel, wie man das obige Problem mit Hilfe des Flexbox-Modus lösen kann.
Dazu brauchen wir zunächst einen Container und die Boxen dann innerhalb des Containers:
<div id="flex-container">
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist kurze Headline</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
</div>
Als nächstes muss das CSS eigentlich nur noch um die entsprechenden Flex-Direktiven erweitert werden:
<style>
#flex-container {
display: -webkit-flex;
display: -ms-flex;
display: flex;
-webkit-flex-wrap: wrap;
-ms-flex-wrap: wrap;
flex-wrap: wrap;
}
.panel-test2 {
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
width: 30%;
padding: 20px;
float: left;
margin: 10px;
border: 1px solid #aaa;
}
</style>
Wie man sieht, wird hier das Flex-Layout mit display: flex sowohl für den Container als auch die Child-Elemente eingeschaltet. Dies führt schon automatisch dazu, dass alle Boxen die gleiche Höhe bekommen. Die Höhe ist dabei die des größten Elements.
Allerdings würden dann alle Boxen in einer Zeile erscheinen und entsprechend schmaler werden. D.h. die definierte Breite würde ignoriert werden.
Damit stattdessen die vordefinierte Breite von 30% genutzt wird, wird flex-wrap: wrap eingesetzt. Dies sagt dem Container, dass „überschüssige“ Boxen in die nächste Zeile rutschen sollen.
Das Ergebnis sieht dann so aus:
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Wie man sieht, ist die Lösung für dieses Problem relativ einfach.
Man sollte dabei natürlich auf Browser-Kompatibilitäten achten. So gibt es Flexbox in allen modernen Browsern und im IE ab Version 11. Testen sollte man es aber natürlich dennoch.
Als ich dieses Blog aufsetzte, war ich natürlich auch auf der Suche nach einem Plugin, mit dem ich verwandte Artikel verlinken kann. Es gibt diverse Plugins für WordPress, die das automatisiert machen können, wie z.B. Yet Another Related Posts Plugin oder Contextual Related Posts – ich aber will diese Artikel manuell aussuchen. So habe ich mehr Kontrolle und bin mir sicher, dass die Artikel auch Sinn machen.
Die Anforderungen
Die Anforderungen waren für mich im Detail:
- Ich will bei einem Artikel zu anderen Artikeln angeben
- Bis zu 3 Verweise sollen unter dem Artikel erscheinen
- Verlinke ich einen Artikel, soll dieser Artikel auch automatisch einen Backlink bekommen.
- Trotzdem sollen insgesamt nur 3 Artikel in der Liste angezeigt werden, wobei die ausgehenden Links Vorrang haben sollen.
Ich habe mir zunächst das Manual Related Posts Plugin angeschaut, das allerdings seit 7 Monaten nicht mehr aktualisiert wurde. Zudem hatte ich auch ein paar Probleme mit dem Styling, da er z.B. feste style-Angaben in den Code schreibt, die man zwar theoretisch per Filter ändern kann, was aber für mich nicht so richtig funktioniert hat.
Die nächste Idee war dann, das direkt selbst im Theme zu implementieren. Problem hierbei: Benutzer-Interfaces in WordPress zu implementieren ist nicht gerade ein Spaß (zumindest out of the box). Und an dieser Stelle kam dann das Advanced Custom Fields Plugin ins Spiel. Hier muss man zwar immer noch selbst ein bisschen Code schreiben, aber die UI-Arbeit ist damit zum Glück schon erledigt. (Dank geht an Claudia von Chilliscope, die mich wieder dran erinnerte, dass es dieses Plugin ja auch noch gibt).
Was ist das Advanced Custom Fields Plugin (ACF)?
Kurz gesagt, lassen sich mit dem Advanced Custom Fields Plugin neue Metadaten-Felder für Artikel, Seiten und Custom Content Types definieren. Diese Felder sind dabei deutlich ausgereifter im UI als die Standard-WordPress-Implementierung. Hinzu kommt eben, dass man sich um das Benutzer-Interface dann gar nicht mehr selbst kümmern muss.
Allerdings muss man schon etwas programmieren können, um ACF nutzen zu können, denn es fragt nur die Daten ab, zeigt sie aber zunächst nicht wieder an. Dazu muss man das Theme entsprechend anpassen, was PHP-Kenntnisse benötigt.
Verwandte Artikel mit Advanced Custom Fields implementieren
Wie geht man also nun vor, um eine manuelle Verlinkung von Artikeln zu implementieren? Am Anfang steht die Definition des benötigten Feldes, in dem man die Artikel aussucht, die man verlinken will. Dazu legt man unter dem Menüpunkt Eigene Felder zunächst eine neue Gruppe an, die man beliebig nennen kann. Bei mir heißt sie „Post Links“. Direkt darunter kann man dann ein neues Feld erstellen. Als Titel habe ich „Verwandte Artikel“ gewählt, als internen Namen „related_posts“ und als Feld-Typ Beziehung. Man hätte auch den Artikel-Typ nehmen können, aber dann bekommt man nur eine lange Liste von Artikeln angezeigt. Das Beziehungs-Feld dagegen hat noch eine Suche eingebaut ähnlich dem Link-Dialog.
Wichtig für mich war weiterhin, dass ich nur Posts erlaube, dass man nicht zwingend etwas auswählen muss, und dass man mehrere Artikel selektieren kann.
Insgesamt sieht das dann so aus:
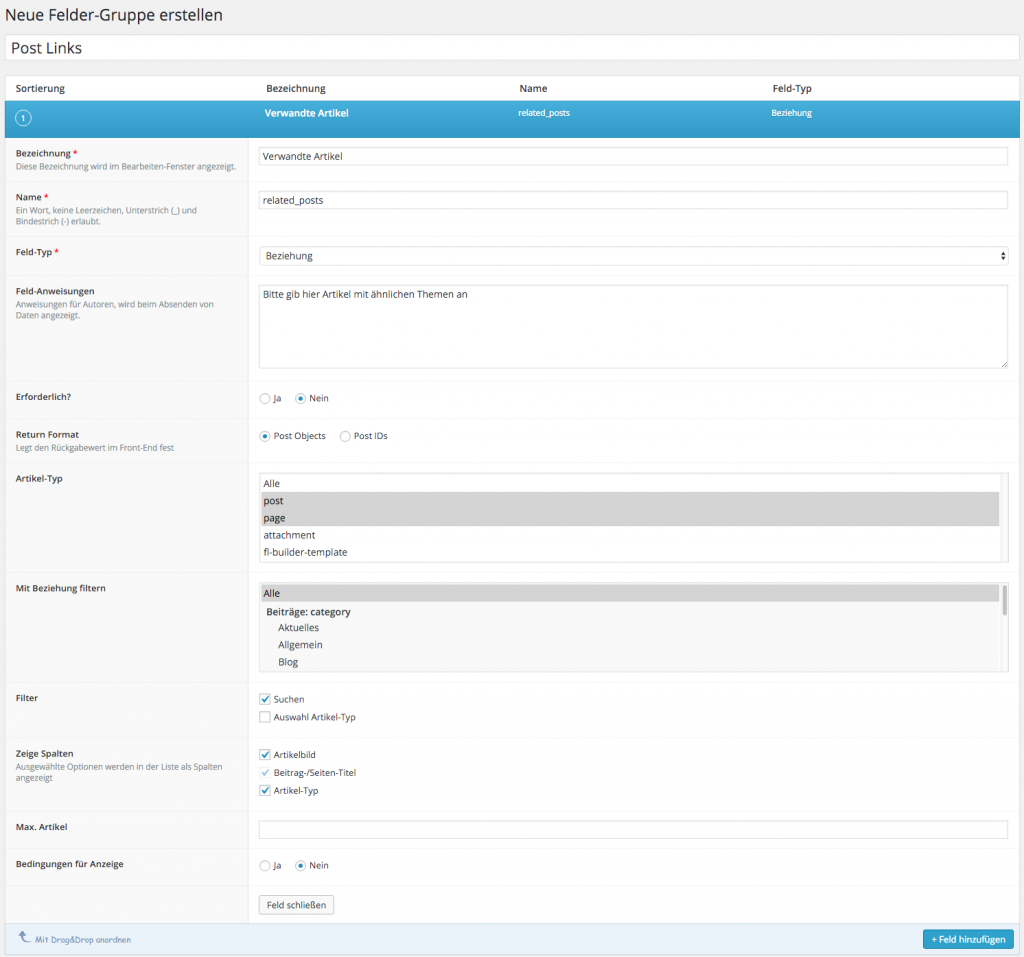
Beziehungsfeld für die verwandten Artikel anlegen
Bei den Optionen kann man dann noch angeben, dass die Gruppe unter dem Inhalt („normal“) angezeigt werden soll und dass der Stil „Standard“ sein soll (also mit Rahmen). Und bitte nicht vergessen, vorher auch das Feld hinzuzufügen, die Optionen gelten nämlich für die ganze Gruppe.
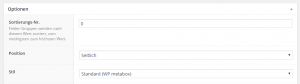
Optionen in ACF einstellen
Hat man das alles gemacht, erscheint rechts in der Seitenleiste bei den Artikeln eine neue Box namens „Post Links“, wo man dann beliebig viele Artikel selektieren kann (von denen wir später aber nur maximal 3 anzeigen).
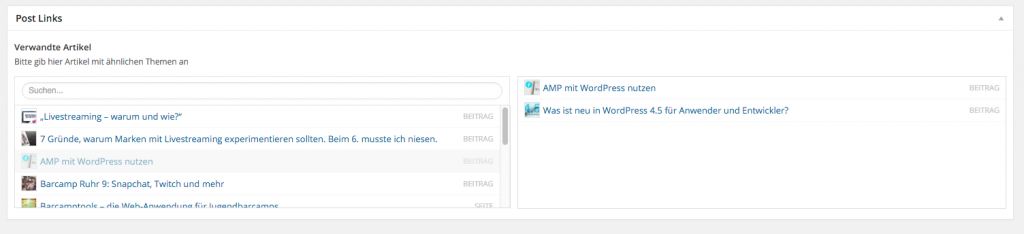
Das Beziehungsfeld in Aktion
Optional: Feld-Liste als PHP exportieren
Ich persönlich habe dies zunächst auf meiner Test-Installation gemacht und habe danach unter „Eigene Felder“ den Punkt „Export“ und dann „Export als PHP“ gewählt. Heraus kommt PHP-Code, der in die functions.php im Theme eingebaut werden kann.
Der Vorteil: Ich muss die Feld-Definition nicht bei jedem Blog vornehmen, sondern sie ist fest im Theme verankert (ACF muss aber installiert sein). In meinem Fall kann ich einfach das Theme auf die Live-Site deployen und schon erscheinen die Felder. So würde ich mir das bei allen Plugins wünschen.
Man sollte allerdings die Gruppe im Backend wieder löschen, nachdem man den PHP-Code ins Theme eingebaut hat, da ansonsten die Felder doppelt erscheinen könnten.
Verwandte Artikel ausgeben
Jetzt können wir Artikel selektieren, jedoch werden sie noch nicht ausgegeben. Gehen wir dazu am besten Schritt für Schritt vor. Dazu habe ich in der Datei single.php im HTML einen neuen Bereich für die Artikel-Liste geschaffen und folgenden Code für die Liste selbst genutzt:
<?php
$related = get_field("related_posts");
// output all the related articles
if( $related ): ?>
<h2>Vielleicht auch total interessant:</h2>
<div class="row">
<?php foreach( $related as $post): setup_postdata($post); ?>
<div class="col-md-4">
<div class="panel">
<a href="<?php the_permalink(); ?>" title="<?php echo esc_attr( the_title_attribute( 'echo=0' ) ); ?>" rel="bookmark">
<?php echo the_post_thumbnail("featured-wide", array( 'class' => 'img-responsive') ); ?>
<div class="panel-heading">
<h5 class="entry-title clearfix"> <?php the_title(); ?> </h5>
</div>
</a>
</div>
</div>
<?php endforeach; ?>
</div>
<?php
wp_reset_postdata();
endif;
?>
Noch erfüllt das allerdings nicht alle Anforderungen, vor allem werden die auf diesen Artikel zeigenden Artikel noch nicht dargestellt. Außerdem werden mehr als 3 Artikel angezeigt, wenn sie vorhanden sind. Darauf kann man natürlich im Backend achten, wenn aber noch die eingehenden Links dazukommen, können es auch deutlich mehr als 3 werden.
Eingehende Links darstellen
Um die eingehenden Artikel-Verlinkungen auch darstellen zu können, muss man die Datenbank befragen. Dies geht mit folgendem Code-Schnipsel:
$incoming = get_posts(array(
'post_type' => 'post',
'meta_query' => array(
array(
'key' => 'related_posts', // name of custom field
'value' => '"' . get_the_ID() . '"', // matches exaclty "123", not just 123. This prevents a match for "1234"
'compare' => 'LIKE'
)
)
));
Es wird hier wieder das Feld related_posts genutzt, allerdings wird gefragt, welche Artikel die ID des aktuellen Artikels in diesem Feld beinhalten. Die Liste dieser Artikel wird dann in $incoming abgespeichert.
Als nächstes müssen wir das noch mit den ausgehenden Links zusammenführen und auf 3 Artikel insgesamt begrenzen:
if (!$related) {
$related = array();
}
$related = array_merge($related, $incoming); // merge own and incoming together
// limit to 3 articles, own links always take precedence
$related = array_slice($related, 0, 3);
Wichtig ist auch der erste Teil, wo wir sicherstellen, dass die $related-Variable auch wirklich ein Array ist, damit array_merge keinen Fehler wirft.
Insgesamt kommen wir dann auf folgenden Code:
<?php
$related = get_field("related_posts");
// merge in articles pointing to this post
$incoming = get_posts(array(
'post_type' => 'post',
'meta_query' => array(
array(
'key' => 'related_posts', // name of custom field
'value' => '"' . get_the_ID() . '"', // matches exaclty "123", not just 123. This prevents a match for "1234"
'compare' => 'LIKE'
)
)
));
if (!$related) {
$related = array();
}
$related = array_merge($related, $incoming); // merge own and incoming together
// limit to 3 articles, own links always take precedence
$related = array_slice($related, 0, 3);
// output all the related articles
if( $related ): ?>
<h2>Vielleicht auch total interessant:</h2>
<div class="row">
<?php foreach( $related as $post): setup_postdata($post); ?>
<div class="col-md-4">
<div class="panel">
<a href="<?php the_permalink(); ?>" title="<?php echo esc_attr( the_title_attribute( 'echo=0' ) ); ?>" rel="bookmark">
<?php echo the_post_thumbnail("featured-wide", array( 'class' => 'img-responsive') ); ?>
<div class="panel-heading">
<h5 class="entry-title clearfix"> <?php the_title(); ?> </h5>
</div>
</a>
</div>
</div>
<?php endforeach; ?>
</div>
<?php
wp_reset_postdata();
endif;
?>
Und das ist auch der Code, der jetzt hier auf der Site im Einsatz ist. Dank Advanced Custom Fields war das recht flott zu implementieren und erfüllt alle meine Anforderungen. Ein ingesamt kleines Beispiel, aber man sieht gut daran, dass hier mit etwas Fantasie noch sehr viel mehr möglich ist.
Was habt ihr denn so damit gebaut?
Am 12. April wurde WordPress 4.5 veröffentlicht. Zeit also, mal zu schauen, was neu ist. Die aktuelle Version gibt es wie gehabt bei WordPress auf der Dowload-Seite (hier die englische Version).
Neues für Anwender
Nativer Logo-Support in Themes
Bislang konnte man bei Themes im Customizer nur das Site-Icon (also favicon) ändern, nicht jedoch das Logo. Dies musste man als Theme-Autor per Hand implementieren.
Mit WordPress 4.5 hat das ein Ende und es gibt offiziellen Support für Site-Logos. Diese findet man dann im Customizer an derselben Stelle, wo man das Icon hochlädt. Für Theme-Entwickler spart dies also Arbeit. Für Anwender bedeutet dies, dass man den Logo-Upload nun ggf. an einer anderen Stelle findet. Natürlich muss ein Theme dies unterstützen, es erscheint nicht einfach von selbst.
Device-Preview im Customizer
Im Customizer hat sich eine weitere Sache geändert: Man kann nun zwischen Desktop-, Tablet- und Mobilansicht wechseln und sieht so genau, wie die Seite in den verschiedenen Größen aussieht. Zu finden ist der Umschalter ganz unten im Customizer.
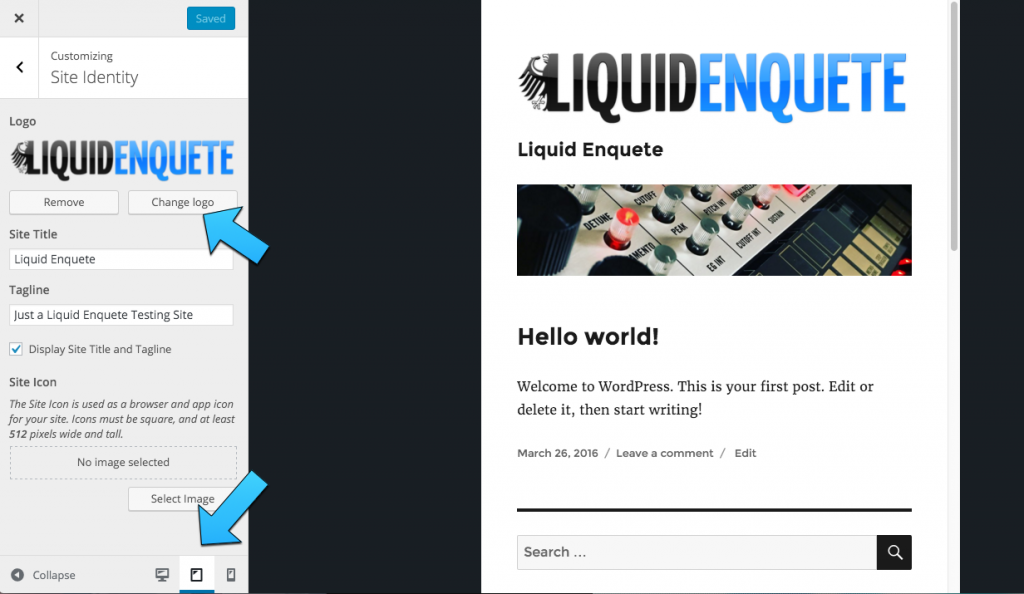
Custom Theme Logo und Device Preview
Neue Shortcuts für den Texteditor
Im Texteditor kann man nun mit --- eine horizontale Linie (also <hr> in HTML) generieren und mit `text` kann Source-Code ausgezeichnet werden, wird also zu <code>text</code>. Eigentlich waren noch weitere Kürzel implementiert, wurden aber in Beta 4 wieder entfernt, da sie wohl für manche Benutzer irritierend waren. Sie kommen dann ggf. in einer späteren Version.
Inline-Linkeditor
Ebenfalls neu im Editor ist der Inline-Link-Editor. So geht beim Klick auf einen Link oder CTRL/CMD-K kein großes Popup mehr auf, sondern es erscheint ein kleines Inline-Popup, um den Link einzugeben oder zu ändern. Mit Klick auf das Zahnrad öffnet wieder das bisherige Popup, die restliche Funktionalität soll aber später auch noch in das kleine Popup integriert werden.
WordPress Inline-Toolbar zum Link-Editieren
Bessere Kommentaransicht
Die Detailansicht, auf die in E-Mail-Benachrichtigungen für zu moderierende Kommentare verlinkt wird, wurde generalüberholt und zeigt jetzt sinnvolleren Inhalt an (z.B. einen gerenderten Kommentar statt Source-Code).
Effizientere Bildkomprimierung
Bilder werden nun effizienter komprimiert, z.B. durch das Weglassen von nicht benötigten Metadaten. Inwiefern das wirklich eine Verbesserung bringt (auch im Vergleich zu Plugins) muss man sicher individuell betrachten.
Mehr Fehlermeldungen im Debug-Modus
Hat man den Debug-Modus in wp-config.php angeschaltet, so erscheinen jetzt auch Datenbankfehler. Dies war vorher nicht der Fall, macht aber Sinn, da man nur Fehler beheben kann, die man auch kennt.
WordPress 4.5 für Entwickler
Nicht nur für Anwender hat sich was getan, sondern auch für Entwickler. Wer also Themes und Plugins entwickelt, sollte sich möglichst bald WordPress 4.5 installieren, um die Änderungen zu testen. Ich selbst habe jetzt nicht alles ausprobiert, da ich z.B. keine Plugins im Bereich Term-Editing implementiere, hoffe aber trotzdem, alles richtig dargestellt zu haben. Anmerkungen dürft ihr daher gerne in den Kommentaren hinterlassen. Im Zweifel sind auch die relevanten Blog-Posts verlinkt.
JavaScript und CSS
Verschiedene externe Libraries wurden aktualisiert, vor allem Backbone und Underscore (auf 1.2.3 bzw. 1.8.3) . Dabei gibt es ein paar Breaking Changes, also aufpassen, wenn ihr diese in euren Projekten nutzt. Ebenfalls aktualisiert wurden jQuery (auf 1.12.2) und jQuery Migrate (auf 1.4.0). Auch hier sollte man also testen.
Außerdem wurde der Script-Loader verändert, weitere Informationen findet man hier. So man keine veralteten Funktionen nutzt, sollte man davon allerdings wohl nichts merken.
Änderungen an der Term Edit Page
Wer Plugins besitzt, die sich irgendwie um Terms drehen, der sollte diesen Blogpost lesen, da die Terms-Liste und das Formular nun getrennte Seiten sind. Eventuell müssen dann Scripte neu registriert werden.
Live Preview: Schneller, erweiterbarer und mehr Features
Der oben schon erwähnte Customizer hat auch intern Änderungen erfahren. Zusätzlich zur genannten Device-Preview gibt es einerseits die sogenannten Setting-Less Controls und andererseits den Selective Refresh.
Setting-Less Controls sind dabei einfach UI-Elemente, die keinerlei interne Datenspeicherung haben. Solche braucht man z.B. um bestimmte Elemente im UI ein- oder auszublenden. Es erübrigen sich also Datenfelder, die gar keinen Inhalt haben.
Selective Refresh erlaubt es, die Preview schneller zu rendern und das mit weniger Code. Allerdings müssen Theme- und Plugin-Entwickler dazu entsprechende Anpassungen machen. So müssen dann nicht mehr alle Widgets neu gerendert werden, wenn man nur etwas an den Theme-Settings ändert und andersrum (wenn ich das richtig verstehe).
Weitere Details zur Implementierung findet ihr in diesem Artikel.
Custom Theme Logos
Wie man die oben erwähnten neuen Logos in sein Theme einbaut und die Darstellung anpasst, wird hier beschrieben.
Embed Templates
Auch an Embdes wurde gearbeitet (wenn man z.B. eine YouTube-URL eingibt, so erkennt WordPress dies und bindet das Video direkt als embed ein). So hat das iframe jetzt einen besseren title (gut für Barrierefreiheit) und es gab eine Performance-Steigerung bei der Discovery von oEmbeds.
Für Theme-Entwickler dürften aber die Änderungen an den embed-Templates interessant sein. Es gibt nämlich jetzt nicht mehr nur eine Datei, die für das Layout zuständig ist, sondern diverse (Header, Footer usw.). Diese kann man dann in seinem Theme überschreiben. Außerdem kann man via Template-Hierarchie jetzt für verschiedene Post-Types verschiedene Embed-Templates definieren. So könnte ein Video in einem Video-Post anders dargestellt werden als in einem normalen Blog-Post.
Multisite
Die größte Änderung hier ist wohl die Einführung eines WP_Site-Objekts, sowie neuer Actions und Filter.
Änderungen in der REST-API (breaking)
Die REST-API wurde so geändert, dass sie jetzt immer unslashed Data zurückgibt. Näheres zu den Gründen dieser Änderung und worauf man achten muss, findet man in diesem Artikel.
Alles weitere
Hier konnte jetzt nicht alles beschrieben werden, z.B. gab es auch noch diverse behobenen Bugs, neue Hooks oder neue Parameter für diese. Es lohnt daher ein Blick in Trac oder auf das offizielle Entwickler-Blog.
Natürlich solltet ihr vor einem Upgrade dann auch überprüfen, ob denn alle von euch genutzten Plugins kompatibel sind. Ein vorheriger Backup versteht sich hoffentlich von selbst.
Wenn es beim Update auf WordPress 4.5 Probleme gibt
Obwohl die Anzahl der Änderungen überschaubar ist, kann es beim Update dennoch ein paar Probleme geben. Eine Ursache können die Updates der JavaScript-Libraries sein. Wenn hier z.B. der Cache nicht richtig geleert wird, können Seiten noch die alten Versionen nutzen oder einen Mix aus alten und neuen. Dies wiederum kann zur falschen Anzeige von Seiten führen.
Sollte es beim Update Probleme geben, kann man Folgendes probieren, um sie zu beheben:
- Alle Caches löschen. Dies betrifft Plugins wie WP Super Cache, W3 Total Cache, Varnish, aber auch autopimize und ähnliche Tools, die CSS und JS zusammenfassen und komprimieren.
- Auch bei Nutzung eines Content Delivery Network sollte sichergestellt sein, dass dort die aktuellen Versionen zu finden sind
- Browser-Caches sollten aktualisiert werden. Bei einem eigenen Theme kann dies dadurch geschehen, dass man die Versionsnummer der eingebundenen Script aktualisiert (wie das geht, erfährst Du in diesem Artikel).
Sollten danach noch keine Besserung eingetreten sein, muss man mehr im Detail debuggen. So kann man
- im Browser den Debugger einschalten (z.B. in Chrome unter Anzeigen -> Entwickler -> Entwicklertools). In der Konsole erscheinen dann ggf. JS-Meldungen, die einen Hinweis auf das Problem geben könnten.
- Alle Plugins deaktivieren. Tritt das Problem dann immer noch auf, weiß man, dass es eher am Theme als den Plugins liegt. Tritt es nicht auf, sollte man Plugin für Plugin aktivieren, bis man das Plugin gefunden hat, welches das Problem verursacht.
- Ebenso kann man auf ein Standard-Theme umschalten und testen, ob der Fehler dann noch auftritt. Wenn man sich nicht mehr einloggen kann, kann man per FTP (bitte Backup vorher machen) alle Themes bis auf Twentysixteen entfernen. Dann wird dieses automatisch genutzt.
Voraussetzung ist dabei allerdings eine gewisse Erfahrung mit PHP und JavaScript.
Wenn alles nichts nutzt, kannst Du versuchen, WordPress manuell zu aktualisieren. Dazu lädt man das ZIP herunter und lädt die Dateien dann separat auf den Server hoch. Dabei mann man wp-includes und wp-admin vorher löschen, wp-content und wp-config.php sollten aber unbedingt beibehalten werden, da dort die eigenen Daten liegen. Mehr dazu findest Du in diesem Artikel.
Eine Liste mit weiteren Problemen und deren möglichen Ursachen und Lösungsvorschlägen findest Du auf wordpress.org.
Generelle Hinweise
Wie immer bei neuen Versionen, vor allem, wenn es um WordPress selbst geht, empfiehlt es sich, diese auf einer Test-Instanz zu testen. Ein Update des Live-Systems zu machen und dann zum Debuggen alle Plugins oder das Theme deaktivieren zu müssen, das tut niemand gerne. Also teste sowas am besten immer mit einer Test-Version.
Zusätzlich empfiehlt es sich, das Update vielleicht nicht direkt bei Erscheinen durchzuführen, sondern noch ein wenig zu warten. Damit ist die Gefahr geringer, dass ein Plugin oder Theme noch nicht für die neue Version aktualisiert wurde. Zur Sicherheit sollte man zudem natürlich immer die Release-Notes aller Plugins und Themes durchlesen. Zusätzlich kann man auch noch ein Blick auf die Foren werfen, ob dort Probleme gemeldet wurden.
Am 12. und 13. April fand die 2-tägige Facebook-Entwicklerkonferenz f8 mit diversen Keynotes und allerlei Ankündigungen statt. Dass Live-Streaming eine große Rolle spielen wird, war ja vorher schon bekannt. Dass Chat-Bots auf der Facebook Messenger Platform eine Rolle spielen würden, war zumindest eine gut begründete Annahme. Und nun da es Gewissheit ist, will ich in diesem Artikel einen kleinen Überblick geben, wozu und wie man sie nutzen kann.
Chat-Bots auf der Facebook Messenger Platform
900 Millionen Personen nutzen laut Mark Zuckerberg den Facebook Messenger. Und pro Tag werden im Moment 3 mal so viele Nachrichten über Facebook und WhatsApp gesendet als SMS gesendet werden. Zeit also für Facebook, es diesen 900 Millionen Menschen zu ermöglichen, mit Bots in Kontakt zu treten.
Die Zielgruppe für die Bots sind dabei Unternehmen, die dann ihre Dienstleistungen oder Produkte auch über den Facebook Messenger anbieten können.
Warum Bots?
Was aber bieten Bots für Vorteile und warum sollte ich sie als Unternehmen oder Kunde nutzen? Die Antwort von Mark Zuckerberg: Mit Unternehmen in Kontakt zu treten, ist normalerweise nicht einfach. Man muss entweder anrufen oder eine E-Mail schicken oder aber eine App installieren. Warum also nicht einfach ein Tool nutzen, das 900 Millionen Leute rund um die Welt eh schon nutzen?
Der Vorteil ist dabei klar: Wer einen Bot baut, braucht ggf. keine eigene App bauen. Ein Bot hat dabei viele Vorteile:
- Er ist normalerweise in der Entwicklung billiger, da man ja nur eine API abdecken muss.
- Der Benutzer braucht nichts weiter zu installieren
- Der Benutzer muss keine App-Benachrichtigungen erlauben (was wohl weniger und weniger gemacht wird). Solange der Messenger Nachrichten schicken darf, kann es auch der Bot.
- Er kann serverseitig aktualisiert werden, der Benutzer muss nichts tun
Es gibt natürlich auch Nachteile:
- So ein Bot läuft nur auf Facebook.
- Ein Bot ist trotz strukturierter Messages (siehe unten) trotzdem in der Interaktion eingeschränkter als eine App oder Web-Anwendung
- Man unterliegt den Facebook Content Guidelines
Es hängt also von der Zielgruppe ab, welche Vor- und Nachteile wirklich relevant sind. Es ist aber zumindest ein weiterer Vermarktungsweg, den man ggf. mit abdecken will.
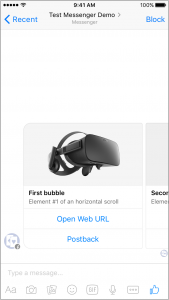
Beispiel für eine structured Messages eines Bots
Was bieten Bots?
Wer jetzt bei einem Chat-Bot an ein text-basiertes, einfaches Frage-Antwort-Spiel denkt, der liegt falsch. Die Facebook-Bots erlauben nämlich nicht nur Textnachrichten, sondern können auch strukturierte Messages zurück liefern. Dies können z.B. Buttons sein oder auch ein Produkt-Karussell, wo ich mir das gewünschte Produkt aussuchen kann.
Ich kann dem Bot außerdem meine Location über den Messenger mitteilen, was bei location-based Services wie einem Wetter-Bot Sinn macht (den gibt es als Beispiel auch schon von Facebook, kennt sich aber wohl nur in den USA aus).
Im Moment kann man folgende Elemente senden:
- Eine Text- und Bild-Nachricht
- Ein Button-Template mit einer beliebigen Anzahl von Buttons.
- Ein generisches Template mit einer beliebigen Anzahl von „Bubbles“. Eine Bubble beinhaltet dabei eine Headline, ein Bild, einen Text und eine beliebige Anzahl von Buttons. Dies ist, was im Bild dargestellt wird.
- Ein Receipt-Template, das z.B. einen Warenkorb auflisten kann.
Jeder Button kann dabei sowohl ins Web verlinken oder zu einem Hook in der eigenen Applikation, z.B. um eine Antwort zu senden.
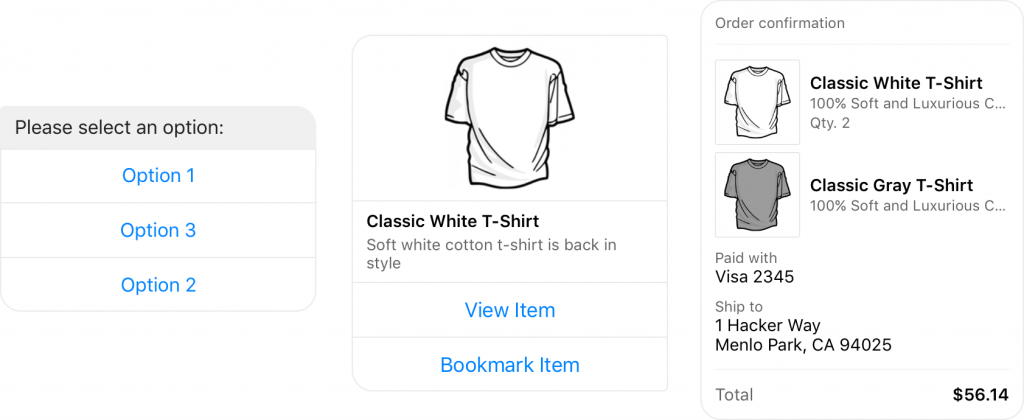
Beispiel für die Messenger UI
Wie implementiert man Chat-Bots für den Messenger?
Zur neuen Bot-Infrastruktur gehören verschiedene Komponenten, wie die eigentliche API zur Implementierung des Bots. Hinzu kommen Möglichkeiten, einen Bot auffindbar zu machen oder einen Benutzer zu identifizieren. Und auch eine Engine für künstliche Intelligenz fehlt nicht. (Angst vor einem neuen Nazi-Bot braucht man allerdings nicht zu haben, da diese Engine nicht komplett frei lernt).
Der eigentliche Bot wird über die sogenannte Send/Receive-API implementiert. Die Bot-Logik läuft dabei auf dem eigenen Server und man bekommt die Benutzereingaben über Webhooks übergeben. Man kann dann mit eigenen Nachrichten antworten, seien es reine Textnachrichten oder die oben erwähnten strukturierten Messages.
Weiterhin kann ein Willkommens-Screen definiert werden, um dem Benutzer zu erklären, was mit dem Bot so möglich ist. Den Benutzer kennt Facebook im übrigen im Gegensatz zu E-Mail oder einem Anruf auch schon und als Entwickler hat man über die User Profile API Zugriff auf Namen und Profilbild.
Direkt live sind Bots im übrigen nicht, Facebook muss diesen erst zustimmen, also ein ähnlicher Prozeß wie bei Apps.
Hier geht es zur ausführlichen Entwickler-Anleitung bei Facebook.
Wie finde ich Bots?
Der schönste Bot nutzt nichts, wenn Kunden ihn nicht finden. Facebook hat dazu mehrere Möglichkeiten vorgesehen. Eine davon ist die permanent eingeblendete Suchfunktion im Messenger. Dazu muss man natürlich trotzdem schon wissen, welche Bots es so gibt. Deswegen gibt folgende weitere Möglichkeiten:
Neue Facebook-Plugins: Send-to-Messenger und Message-Us
Facebook bietet zwei neue Plugins an, nämlich das „Send-to-Messenger„- und das „Message Us„-Plugin. Dies sind Buttons, die auf der Website eingebaut werden können und entweder einen Benutzer nur authentifizieren oder direkt eine Konversation öffnen. Wenn ich das richtig verstehe, bekommt man beim Send-To-Messenger-Plugin als Entwickler nur einen authentifizierten Benutzer zurück, dem man dann eine Nachricht schicken kann. Man wird also nicht automatisch von der Webseite zu einer Konversation geleitet.
Das sieht dann z.B. so aus, wenn man schon angemeldet ist (ansonsten muss man sich in Facebook einloggen):
Send-to-Messenger-Plugin in Aktion
Im Falle des Message-Us-Plugins kommt man durch einen Klick auf den Button direkt zum Messenger (wer es nicht wusste, es gibt eine reine Web-Version unter www.messenger.com). Dies sieht dann so aus:
Das Message-Us Plugin
Messenger-Codes
Ähnlich wie bei Snapchat auch, kann man eine Konversation jetzt mit einem einscannbaren Code starten. Der von CNN sieht dabei z.B. so aus:

Dies gibt es theoretisch schon seit einer Woche und auch nicht nur für Bots, sondern jedermann. In meiner App ist es allerdings noch nicht zu finden.
Neue Newsfeed-Ads
Neu sind zudem spezielle Newsfeed-Ads für Bots, die per Klick dann direkt eine Konversation im Messenger öffnen.
Laut TechCrunch sollen demnächst wohl auch Ads in Messenger selbst erscheinen. Das aber wohl nur sehr limitiert, da es Benutzer ja schon sehr nerven kann.
Künstliche Intelligenz inklusive
Schön wäre es ja, wenn ein Bot nicht nur stur auf Keywords reagiert, sondern ein bisschen intelligenter beim Verstehen als auch beim Antworten ist. Da hilft Künstliche Intelligenz (KI oder AI).
Facebook bietet dazu die WIT.AI Bot Engine an. Um mehr dazu sagen zu können, muss man wohl etwas mehr damit rumgespielt haben. Ich befürchte allerdings, dass sie zunächst wohl nur für englische Bots funktionieren wird. Bots sind dabei im übrigen nicht das einzige Einsatzgebiet, auch Home Automation oder mobile Anwendungen können damit erweitert werden.
Das Interface sieht recht nett aus, so kann man seine KI mehr oder weniger per Drag’n’Drop zusammenklicken:

wit.ai Interface
Fazit
Dass der Chat mehr und mehr als Absatzkanal genutzt wird, ist ja nichts neues. Und es macht ja auch viel Sinn, da man den Messenger im Zweifel eh schon den ganzen Tag nutzt. Warum also nicht eine Nachricht an ein Unternehmen schicken statt einen Freund, wenn man etwas von diesem will?
Und wenn dann ein Bot mit strukturierten Messages antwortet und man direkt auch kaufen kann – was will man mehr?
Aufpassen muss man natürlich, wenn die Konversation den geplanten Verlauf verlässt, z.B. wenn ein Kunde sich beschwert. Auch dafür muss man planen, denn nichts ist geschäftsschädigender, als wenn man zwar einen Chat-Kanal anbietet, aber Anfragen dann nicht beantworten kann.
Ein Bot allein tut es also nicht. Aber er kann helfen!
Am letzten Wochenende war es wieder soweit: Der Open Data Hackday Niederrhein in Moers fand jetzt schon zum 2. Mal statt. Ich selbst konnte leider nur am Sonntag vor Ort sein, habe aber gehört, dass auch der Samstag super gewesen sein soll. Und das trotz meiner Abwesenheit.
Das Drumherum war dank Claus Arndt von der Stadt Moers und der Bertelsmann-Stiftung natürlich wie immer perfekt (vielleicht bis auf das WLAN, das leider für Livestreaming dann nicht so geeignet war). Anwesend waren über 70 Personen und die jüngsten Teilnehmer waren gerade mal 11 Jahre alt (siehe deren Präsentation weiter unten).
Traditionell begann der Samstag mit Vorträgen, auf die ich aber dank Abwesenheit meinerseits schlecht eingehen kann. Ich kann allerdings dafür über die Ergebnisse berichten, die am Sonntag zum Besten gegeben wurden.

Rocket Girls
Es begann mit den Rocket Girls, einem Workshop von 2 mal 4 Stunden, der von Patricia Ennenbach und Marie-Louise Timcke durchgeführt wurde. Der Workshop richtete sich hauptsächlich an Frauen und Schülerinnen. Das Ziel war eine Einführung in die Programmierung und Datenvisualisierung auf Basis von offenen Daten.
Dazu gab es zunächst am Freitagabend einen Workshop, in dem Patricia erklärte, was offene Daten sind und erste Schritte auf der Command-Line vermittelte. Danach wurde mit Hilfe von Python und Jupyter Notebook gezeigt, wie man Daten verarbeitet und visualisiert. Zum Schluß wurde noch eine Anwendung mit flask gebaut.
Am Samstag übernahm dann Marie-Louise und hat die Themen Programmierung und Datenvisualisierung mit Hilfe der Sprache R aufgezeigt.
Die Folien findet man hier (musste ich allerdings kopieren, damit das Einbinden funktioniert):
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Weitere Informationen
Bußgeldanalyse von Julius und Mats
Dass man nicht wirklich alt sein muss, um mit Open Data zu beginnen, zeigen Julius und Mats (beide 11 Jahre alt). Sie haben sich die Bußgelddaten der Stadt Moers vorgenommen und visualisiert. Dabei haben sie einige interessante Erkenntnisse gewonnen.
Und gut vortragen können sie auch schon! Hut ab!
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
VRR-Qualitätsanalyse
Als nächstes waren zwei „alte“ Hasen der Open Data-Szene dran. Elmar Burke und David Krystof haben sich den Qualitätsbericht des VRR vorgenommen und visualisiert.
Der Haken an der Sache: Bislang gibt es diesen nur als PDF. Das Gute am Hackday: Jemand vom VRR war vor Ort und eventuell bessert sich das.
Hier aber die Präsentation:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Datenwaben für alle!
Ein weiterer alter Hase ist Thomas Tursics, der ja schon so einiges im Bereich Open Data gemacht hat. Er hat beim Hackday Niederrhein an seinem Datenwaben-Projekt gearbeitet.
Er nimmt dabei die Datensätze eines Open Data Portals einer Stadt und stellt diese als Waben mit einem interessanten Wert da. Das sieht für Wien z.B. so aus:

Datenwaben für Wien
Beim Hackday wurde eine Seite für Moers bearbeitet, aber auch für Aachen gibt es jetzt wohl schon Infrastruktur. Schaue ich mir auf jeden Fall demnächst mal an.
Hier stellt er es aber noch einmal selbst vor:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Der Hausaufgabenplaner
Lennart war letztes Jahr schon auf dem Open Data Hackday und hat diesen zum Anlass genommen, Programmieren zu lernen.
Sein Ziel: Seinen Schulalltag mit einer App besser planen zu können. Dies hat er auch erreicht und inzwischen ist es nicht nur eine App, sondern auch ein Webservice, damit man auch Daten von außen einspeisen kann.
Auf dem Hackday Niederrhein hat er zudem noch zwei Mitstreiter gefunden, die ihr Projekt im folgenden Video vorstellen:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
InstallYourSport
Bei der letzten Präsentation ging es um Sport und die Frage, wie man Trendsportarten populärer machen kann. Genannt wurden u.a. BMX oder Cheerleading (oder Lacrosse aus dem Publikum).
Die App soll mit Hilfe von Videos, News und Locations Lust an diesen Sportarten wecken und zudem helfen, diese in den Schulalltag einzubauen. Dazu wurden u.a. Open Data-Quellen genutzt (z.B. Sportstätten), die sogar live während des Hackdays von Claus Arndt zur Verfügung gestellt wurden.
Hier die Präsentation der beiden:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Geolocations für das Ratsinfo Aachen und Umgebung
Ich selbst habe leider nicht so viel geschafft, habe aber immerhin ein Python-Script geschrieben, welches die Geodaten unserer Ratsinformations-Datenbank aktualisiert.
Dazu muss man wissen, dass wir mit Hilfe unseres ALLRIS-Parsers die Geokoordinaten einer Vorlage grob anhand der Straßennamen ermitteln. Dann liest das Projekt unserac.de dies ein und dort sitzt dann noch eine Redaktion, die diese Daten überprüft und ggf. korrigiert.
Und genau diese Daten fließen dann jetzt auch zurück in unsere Datenbank.
Weiterhin habe ich begonnen, die Schnittstelle unserer Ratsinfo-Datenbank (die ja immerhin Daten aus Aachen, Alsdorf, Würselen, Herzogenrath, Eschweiler und der Städteregion Aachen umfasst) einmal zu dokumentieren. Auf diese Art können diese Daten ja vielleicht in Zukunft noch von anderen Projekten genutzt werden.
Danke für einen gelungenen Open Data Hackday Niederrhein!
Zum Schluss möchte ich mich noch einmal bei allen Beteiligten bedanken. Es war wieder super, Stimmung war toll und gute Ergebnisse gab es, wie ich fand, auch!
Wenn ihr im übrigen noch Links zu euren Projekten habt (Code, Homepage), dann hinterlasst sie doch einfach in den Kommentaren, dann schreibe ich die noch rein.
Hoffentlich also bis zum nächsten Jahr!
Wir alle kennen Facebook als das soziale Netzwerk, was man beim Anstehen mal so nebenbei bedienen kann. Es ist Text und Bild und vielleicht ab und zu mal ein Video. Zwar gibt es seit einiger Zeit auch Facebook Live, also Livestreaming innerhalb von Facebook, das kommt bei mir in der Timeline aber gar nicht so oft vor.
Das aber könnte sich jetzt ändern, denn Facebook pusht diesen Dienst gerade massiv.
Neue Features bei Facebook Live
Laut einem Newsroom-Post von Facebooks Product Management Director Fidji Simo werden derzeit diverse neue Funktionen ausgerollt.
Zum einen gibt es Livestreams bald auch für Gruppen und Veranstaltungen. Nachdem dies letztens schon für alle Facebook-Pages ausgerollt wurde, gibt es kaum einen Bereich mehr, wo es nicht den Streaming-Button gibt.
Direkt von Periscope übernommen ist zudem die Möglichkeit, bei einem Livestream direktes Feedback zu geben, nämlich in Form von Facebook Reactions.
Auch bei der Wiedergabe eines aufgenommenen Streams gibt es Neuerungen. Waren nämlich die Kommentare bislang einfach unter dem Post zu finden, so werden sie in Zukunft synchron beim Abspielen wiedergegeben. Auch dies kennt man schon von Periscope (aber auch Twitch). Das macht es deutlich einfacher, eine Konversation zwischen Streamer und Zuschauern auch in der Aufnahme nachverfolgen zu können.
Natürlich dürfen auch Filter nicht fehlen und so gibt es bald 5 Videofilter, allerdings eher basic. Geplant ist auch die Möglichkeit, direkt auf das Video zu malen.
Zuschauer erhalten ebenfalls ein neues Feature, nämlich die Möglichkeit, Freunde zum Stream-Gucken einzuladen.
Facebook Live statt Messenger
Wie ernst es Facebook mit Live-Video ist, zeigt aber eine ganz andere Änderung: In der App nämlich wird der Messenger-Button durch einen Live-Button ersetzt. Klickt man darauf, kommt man zu einem Live-Video-Verzeichnis mit Suchfunktion. Noch deutlicher kann Facebook wohl nicht zeigen, wie ernst es ihnen ist.
Desktop-Benutzer erhalten auch ein solches Verzeichnes, allerdings in Form einer (wohl im Moment hier noch nicht erreichbaren) Facebook Live Map, auf der Videos per Karte auffindbar sein sollen. Und auch das wurde ja direkt von Periscope kopiert.
Neue Metriken für Facebook Live
Wo es neue Inhalte gibt, will man auch messen, wie gut sie funktionieren. Daher wird es laut dem Facebook Media Blog auch neue Metriken rund um Live-Video geben. Z.B. ist es als Streamer interessant, zu wissen, wie hoch der Peak war, wie viele Leute wann das Video geschlossen haben usw. Dazu gibt es zwei neue Statistiken: Die Gesamtzahl der eindeutigen Besucher, die das Video angeschaut haben, während es live war und eine visuelle Darstellung der Zuschauer während jeden Zeitpunkts des Livestreams.
Zu finden wird das unter Page Insights und in der Video-Library sein und demnächst dann auch via API und als Export.
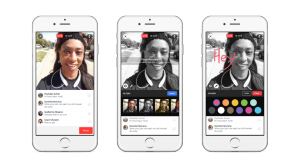
Facebook Live Filters
Facebook zahlt für Live-Streams
Nicht nur, dass es zig neue Features gibt oder geben wird, Facebook pusht auch Inhalte. So hat Fidji Simo re/code erzählt, dass Facebook großen Medienfirmen sogar Geld zahlt, damit sie Facebook Live nutzen. Dabei sind Firmen die BuzzFeed, New York Times und laut einem Redakteur von The Verge wohl auch Vox Media.
Wohin entwickelt sich Facebook?
Mit diesem großen Push in Richtung Live-Video stellt sich natürlich die Frage, warum Facebook dies macht. Schließlich hat Video ja auch Nachteile, vor allem im Vergleich zu Text-Inhalten. Es braucht länger, um konsumiert zu werden. Man kann es nicht mehr nur nebenbei machen. Es braucht Ton und WLAN sollte man je nach Datentarif auch haben. Viele Gründe also, die dagegen sprechen.
Die Zahlen sprechen aber wohl eine andere Sprache. So wird laut Fidji Simo bei Live-Videos z.B. bis zu 10 mal mehr kommentiert. Und auch Casey Newton von The Verge attestierte letztens in einem Stream, dass er deutlich mehr Reichweite bei Facebook Live hatte als es je bei Periscope der Fall gewesen war.
Und eines ist bei Facebook sicher: Sie tun nichts, was sie nicht messen und vorausplanen können. Und ein bisschen Erfahrung mit Live-Video haben sie ja inzwischen auch sammeln können.
Was ist mit Periscope?
Wenn es einen Verlierer gibt, dann ist es wohl Periscope. Das merkt man auch ohne Facebook recht schnell. Denn Videos bei Periscope werden nur 24 Stunden gespeichert, danach hat der Tweet dazu keinen Inhalt mehr. Das ist ärgerlich, wenn man Inhalte streamt, die nicht nur im Moment relevant sind. Dies betrifft z.B. Session-Mitschnitte wie beim PythonCamp (und da habe ich gestreamt) oder auch Interviews. Gerade für Medienhäuser und Unternehmen in meinen Augen ein großer Nachteil.
Und jetzt, wo Facebook die anderen Features eh alle kopiert hat, bleibt bei Periscope nicht mehr viel an USP übrig, außer vielleicht der Twitter-Einbindung. Also wohl leider Chance verpasst.
Ich persönliche finde das alles aber auf jeden Fall spannend. Auch bei der f8-Konferenz nächste Woche wird wahrscheinlich auch noch das ein oder andere dazu gesagt werden. Und zudem ist das alles ein Grund, sich auch als Unternehmen mal Livestreaming anzuschauen.
März und April scheinen die Monate zu sein, wo sich die Events nur so knubbeln. So gab es Ende März das Barcamp Ruhr, dann letztes Wochenende das PythonCamp und nächstes Wochenende geht es direkt weiter! Alles anstrengend, aber auch alles gut und vor allem eine Möglichkeit, neue und alte Bekannte zu treffen!
Hier mal meine Reiseliste, vielleicht ist ja für euch auch noch was dabei. Twittern dazu werde ich auf unserem Twitter-Account und die Events dann hier auf dem Blog zusammenfassen.
Aber so geht es los:
9./10. April: Hackday Moers (#oddmo16)
Nächstes Wochenende findet der 2. Open Data Hackday Niederrhein in Moers statt. Organisiert wird es von der Stadt Moers in Zusammenarbeit mit der Bertelsmann Stiftung. Ich war auch letztes Jahr schon dort und kann nur sagen, dass es sich auf jeden Fall lohnt!
Gerade Moers ist ja dank Claus Arndt Vorreiter in Sachen Open Data. Insofern also der beste Ort in NRW für solch einen Event. Es sollten viele aus der Open Data-Community dort anzutreffen sein.
Wenn ihr also dazugehören wollt: Kommt vorbei! Dabei muss man nicht notwendigerweise programmieren können, auch die Bereiche Visualisierung, Kommunikation, Design, Konzepte oder auch nur Ideen sind bei Open Data wichtig.
Noch sind (soweit ich weiß) Plätze frei und wer kommen will, mag sich in das Organisationspad eintragen. Auch Ideen können dort dokumentiert werden, vielleicht findet sich ja schon im Voraus ein Mitstreiter.
(Ich persönlich bin leider nur Sonntag da)
Hier noch ein paar Bilder vom letzten Hackday:
13. April 2016: NetzpolitikCamp in Dortmund (#netzpolitikcamp)
Weiter geht es direkt am Mittwoch drauf mit dem NetzpolitikCamp im Dortmunder U. Organisiert wird es wieder durch cortex digital im Auftrag der Staatskanzlei NRW.
Ein Thema gibt es dieses Mal auch, nämlich Freifunk. Wenn ihr also etwas zum Thema Freifunk oder generell Netzpolitik diskutieren wollt, dann seid ihr bei diesem Barcamp richtig (bei Barcamps ist man natürlich generell richtig, egal welches Thema).
Tickets gibt es scheinbar auch noch, also schnell anmelden!
2.-4. Mai 2016: re:publica in Berlin (#rpTEN)
Zur re:publica muss man sicherlich nicht viel sagen. Begann es als Blogger-Treffen, so ist sie inzwischen zu DER Konferenz rund um die Themen Internet und Gesellschaft geworden. Immerhin feiert sie dieses Jahr auch 10-jähriges. Der Ort ist wie die letzten Jahre schon die STATION Berlin. Sogar Tickets gibt es noch.
Ich werde die ganze Zeit dort sein und hoffentlich viele von euch treffen!
Und das waren auch meine nächsten Reisen. Es gibt wahrscheinlich noch viel mehr, aber irgendwann muss man ja auch mal daheim sein 😉
Wer sich treffen will, darf sich gerne melden (z.B. per Facebook oder Twitter).
Facebook Reactions gibt es jetzt weltweit seit ca. 1 Monat. Da kann man schonmal fragen: Werden sie denn überhaupt genutzt?
Diese Frage hat sich auch Ranjani Raghupathi von Unmetric gestellt und hat es deswegen eingehender untersucht.
Allerdings bietet Facebook die Zahlen (noch) nicht über die API an und selbst wenn, könnte man es ja nur für die eigenen Inhalte sehen.
Deswegen ist er hingegangen und hat vom 25. Februar bis 5. März die 10 populärsten Posts von Top-Marken auf Facebook manuell untersucht.
Das Ergebnis ist interessant, zeigt es doch, dass fast alle Besucher nur auf Like klicken und die anderen Reactions fast ungenutzt bleiben.
Woran liegt das?
Ranjani Raghupathi nimmt an, dass es an folgenden Faktoren liegt:
- Sowohl mobil als auch auf dem Desktop dauert es deutlich länger, etwas anderes als Like auszuwählen. Man muss entweder drüber hovern oder lange drauf halten und dann noch die richtige Reaction auswählen.
- Like ist man einfach gewohnt und man klickt es fast schon automatisch. Sein Verhalten zu ändern dauert einfach seine Zeit.
- Benutzer kennen die neuen Reactions noch nicht wirklich oder wissen nicht, wie man sie benutzt. Das Interaktionsmuster „Lange draufhalten“ erschliesst sich einem ja nicht sofort.
Den letzten Punkt hat er versucht zu überprüfen, denn seine Annahme war: Ja länger es Facebook Reactions gibt, umso eher kennt und nutzt man sie auch.
Ein weiterer Test vom 6.-15. März hat dann allerdings ein ähnliches Resultat ergeben – es bleibt bei den 93% Likes.
Andererseits sollte man vielleicht etwas mehr Zeit verstreichen lassen, bevor man das Experiment wiederholt.
Was bedeutet eigentlich eine Reaction?
Für mich stellt sich auch noch die Frage, wann man als Besucher eigentlich welche Reaction nutzt. So muss ja ein Post schon sehr lustig oder traurig sein, damit ich auch wirklich auf die entsprechende Reaction klicke. Und traurige oder wütend machende Posts kommen vielleicht bei Marken eh eher selten vor.
Selbst bei WOW oder Love muss der Post schon sehr speziell oder ich ein großer Fan der Marke sein. Insofern bleibt es wahrscheinlich oftmals beim Like.
Was es für Unternehmen bedeutet
Trotzdem ist es natürlich besser, diese Daten zu haben, als gar keine. Sie können trotzdem genutzt werden, um die eigene Content-Strategie anzupassen und zu überprüfen, ob Posts auch die gewünschte Reaktion hervorrufen.
Am ehesten mag sogar eine wütende Reaktion hilfreich sein, zeigt sie doch einen direkten Handlungsbedarf auf. Allerdings muss man das natürlich wieder im Kontext des Posts selbst sehen.
Ranjani Raghupathi hat noch einen anderen Tipp parat: Haltet nach Leuten Ausschau, die einen oder gar mehrere Posts mit Love markieren, das sind ggf. gute Multiplikatoren.
Ich persönlich bin ja gespannt, wie sich das weiterentwickelt und ob auf Dauer mehr Personen mehr als nur Like benutzen.
Wie sind eure Erfahrungen auf euren Seiten? Sind die Zahlen ähnlich? Wie reagiert ihr darauf und was lernt ihr daraus?
via SocialTimes.
Livestreaming ist wahrlich keine neue Erfindung, gab es doch seit den 90ern den RealPlayer und seit 2007 dann Dienste wie ustream.tv, livestream.com (früher mogulus) oder justin.tv (jetzt twitch.tv). Während letztere das Streaming deutlich vereinfacht haben, war es dennoch immer etwas, was eher den Profis vorbehalten war.
Dank mobilen Services wie Twitters Periscope, Facebooks Live Feature oder vielleicht auch bald YouTube Connect ist es aber nun etwas für alle. Man braucht kein großes Studio mehr, das Handy reicht.
Livestreaming via Periscope – der weiße Fleck ist Deutschland.
So wurde Periscope dieser Tage ein Jahr alt und sie berichten, dass in diesem Jahr 200 Millionen Broadcasts erzeugt und 100 Jahre an Live-Video täglich angeschaut wurden. Es scheint also sowohl Streamer als auch Zuschauer zu geben.
Schaut man sich die Streams an, so wird aber auch schnell klar, dass es wie bei YouNow eher Jugendliche sind, die für ihre Peer-Group streamen. Dank der Verbindung von Periscope zu Twitter einerseits und der Facebook Live-Integration andererseits, sollte es aber im Vergleich zu YouNow damit deutlich einfacher sein, auch andere Zielgruppen zu erreichen. Wir sehen das z.B. bei Robert Scoble und anderen Influencern aus dem amerikanischen Raum, die gerne und oft streamen.
Zeit also, sich auch als Marke mal wieder zu überlegen, ob nicht Livestreaming ins Marketingkonzept passt.
Die 7 Gründe, warum Marken sich mit Livestreaming beschäftigen sollten
1. Die Bandbreite ist jetzt da
Dank mobilen Endgeräten und der verfügbaren Bandbreite ist Livestreaming nicht mehr nur was für wenige, die das mit viel Aufwand betreiben. Ein Handy reicht und man hat dank Periscope und Facebook Live schnell einen Livestream am Start. Videoqualität ist dabei gar nicht mal so wichtig, solange der Inhalt interessant ist. Und auch das Zuschauen ist jetzt mobil einfacher, da mehr Bandbreite da ist.
2. Der Medienmix macht’s!
Vor allem in Deutschland gibt es (meines Wissens) kaum Marken, die mal einen Live-Stream wagen. Und wenn, dann nur von größeren Veranstaltungen. Livestreaming kann also eine willkommene Abwechslung im Marketing-Mix sein. Schließlich gibt es ja Menschen, die lieber Texte lesen, andere, die lieber Podcasts hören und wieder andere, die mehr auf Videos stehen. Man kann also durchaus seine Zielgruppe erweitern.
3. Der Zuschauer ist „dabei“
Ein Livestream hat einen ganz anderen Appeal als z.B. ein YouTube-Video. Als Zuschauer ist man live dabei, es ist nichts geschnitten, auch alle Missgeschicke sind noch zu sehen. Selbst wenn einem als Streamer das vielleicht Angst macht, es macht auch den Reiz für den Zuschauer aus.
Das Dabeisein wiederum kann die Markenbindung stärken, wobei das natürlich auch vom Inhalt abhängt. Eine Pressekonferenz ist sicherlich weniger spannend als ein Behind-the-Scenes-Stream oder ein Interview mit Mitarbeitern. Eine Story muss dabei nicht mehr nur nacherzählt werden, sie muss live entstehen und kann auf die Zuschauer eingehen.
4. Ein Stream ist unaufschiebbar
Texte, Videos, Podcasts – das sind alles Dinge, die man auch später noch konsumieren kann. Aber wie oft tut man das dann wirklich? Ein Livestream ist da anders. Der passiert genau jetzt und den kann man nicht einfach aufschieben. Der Call-to-Consumption ist also deutlich stärker ausgeprägt.
Natürlich kann man später einen Mitschnitt ansehen, aber dann sind auch alle Möglichkeiten der Interaktion weg. Zudem: Wer nimmt wirklich ein Fußballspiel auf, um es dann später anzuschauen?
Es sei dennoch erwähnt, dass Streaming-Services wie Periscope oder Twitch durchaus versuchen, den interaktiven Teil auch im Mitschnitt wiederzugeben. So wird bei beiden auch der Chat synchron zum Video angezeigt. Bei Facebook Live dagegen ist das nicht der Fall, hier sind die Chat-Nachrichten am Ende einfach Kommentare, also ohne Zeitbezug zum Video.
5. Die Marke wird persönlicher
Wie immer bei Social Media ergibt sich immer dann eine stärkere Bindung zur Marke, wenn diese nicht als anonyme Entität daherkommt, sondern wenn man mit richtigen Menschen kommunizieren kann. Und in Sachen persönlicher Kontakt kann Livestreaming wahrscheinlich nur von einem persönlichen Treffen getoppt werden. Ich muss das Gefühl haben, dass mir jemand zuhört, mich ernst nimmt oder zumindest unterhaltsam ist. Mit einem Livestream ist das sehr einfach zu bewerkstelligen.
6. Es findet eine direkt Interaktion statt
Dank des Live-Aspekts eines Streams ergibt sich die Möglichkeit der direkten Interaktion zwischen Streamer und Zuschauern. Aber nicht nur. Auch die Zuschauer untereinander können ja interagieren. Das kann man täglich z.B. bei Twitch beobachten, wo der Chat oftmals ein integraler Bestandteil des Streams ist. Zuschauer werden nach ihrer Meinung (in Form von Polls) gefragt oder sie können dem Streamer wertvolle Hinweise geben. Auch ein AMA (Ask me anything) wird gerne mal gemacht.
All das muss nicht nur im Stream-Environment selbst passieren, es kann auch (gerade bei weniger interaktiven Streams) außerhalb passieren, wie auf Twitter mit einem Hashtag. Ein gutes Beispiel ist hier Red Bull Stratos, also der Fallschirmsprung von Rande des Weltalls, der sicherlich viel mehr auf Twitter stattgefunden hat als auf der Streaming-Seite selbst.
7. Es hilft beim Community-Building
Durch Zuschauerinteraktion entsteht auch eine Community. Dazu muss man aber regelmäßig streamen. Gut zu beobachten ist dies z.B. bei Leo Laporte’s This Week in Tech-Podcast-Netzwerk. Dort sind immer hunderte von Personen im Livechat (selbst wenn nicht gestreamt wird) und der Chat ist fester Bestandteil von so manchem Podcast. Weiß Leo mal etwas in seiner Radiosendung nicht, fragt er den Chat.
Das Gute an dieser Art der Interaktion ist, dass man sich als Chat-Teilnehmer noch ernster genommen fühlt, da man dem Streamer helfen konnte.
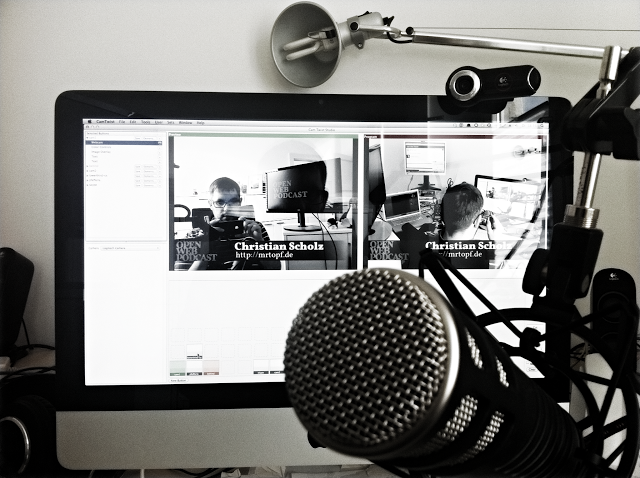
Livestreaming des OpenWebPodcasts
Sollen jetzt alle unbedingt streamen?
Ich würde sagen: Man sollte es auf jeden Fall ausprobieren, allerdings nicht ohne Konzept. Und auch nicht, ohne es zu messen. Wie immer sollte man sich Ziele setzen und analysieren, was ankommt, wie sich Veränderungen auswirken (z.B. die Zeit des Streams) und natürlich, ob es sich überhaupt lohnt.
Viel Aufwand muss es aber auch nicht sein, man braucht nicht unbedingt ein Studio, man braucht keinen perfekten Ton und kein perfektes Licht. Im Zweifel reicht das Handy, wenn denn der Inhalt passt.
Ich persönlich würde mir auf jeden Fall wünschen, mehr in diesem Bereich zu sehen.
Wer kennt das nicht: Man hat ein frisches WordPress-Blog und ein nettes Theme gefunden, doch irgendwie fehlen dem Theme noch 1-2 kleine Features, wie eine Lightbox oder ähnliches. Gibt es für das Problem kein passendes WordPress-Plugin, sondern nur ein jQuery-Plugin, stellt sich dann die Frage, wie man dies in das Theme einbaut.
Daher will ich in dieser Anleitung zeigen, wie man ein jQuery-Script in 2 einfachen Schritten in das eigene oder ein bestehendes Theme einbauen kann.
1. Das jQuery-Plugin im Theme-Verzeichnis ablegen
Dazu erstellt man, wenn es noch nicht vorhanden ist, ein neues Verzeichnis namens js/ innerhalb des Theme-Ordners. Dort kopiert man das jQuery-Script hinein, z.B. /js/query.plugin.min.js. Auch eigene Scripts kann man dort ablegen.
2. Das jQuery-Plugin aktivieren
Damit das jQuery-Plugin auch genutzt wird, muss man WordPress noch sagen, wo es liegt und wie es eingebunden werden soll. Dies geschieht in der functions.php des Themes.
Dort schreibst Du jetzt einfach folgenden Code rein, wobei Du den Dateinamen des Plugins natürlich entsprechend anpassen musst:
add_action( 'wp_enqueue_scripts', 'add_my_scripts' );
function add_my_scripts () {
wp_enqueue_script(
'my-plugin', // eigener Name
get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
}
Folgendes passiert hier:
add_action sagt WordPress, dass es für die Aktion wp_enqueue_scripts auch noch unsere Funktion add_my_scripts aufrufen soll. Diese ist in der 2. Zeile ff. definiert.- Wenn WordPress die Seite darstellen will, geht es u.a. auch alle registrierten Funktionen für diese Aktion durch und ruft dann unsere Funktion auf
- Mit
wp_enqueue_script (Nicht verwechseln mit dem Aktionsnamen) sagen wir dann WordPress, welche JavaScript-Dateien auf der Seite zusätzlich auftauchen sollen (Plugins und das Theme selbst können auch schon welche definiert haben).
- Dieser Funktion übergibt man als Parameter den Namen des Scripts, den Pfad zur eigentlichen JS-Datei und eine Liste von Abhängigkeiten (optional).
Hierbei musst Du auf folgende Sachen achten:
- Der Name muss einmalig sein (hier „my-plugin“). Dieses identifiziert das Plugin gegenüber WordPress. Der Name sollte am besten klein geschrieben sein und keine Leerzeichen enthalten.
- Der Pfad muss natürlich stimmen (hier
/js/jquery.plugin.min.js).
- Die Abhängigkeiten müssen stimmen, in diesem Fall normalerweise einfach
array("jquery"). Schließlich binden wir ja ein jQuery-Plugin ein und das benötigt sicherlich jQuery als Grundlage. WordPress weiß dadurch, dass es erst (das mitgelieferte) jQuery laden soll und dann unser Script.
Achtung: Child-Themes
Wenn Du ein Child-Theme nutzt (z.B. um das Original-Theme nicht ändern zu müssen), dann ändert sich der Aufruf wie folgt:
wp_enqueue_script(
'my-plugin', // eigener Name
get_stylesheet_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
Es wird also get_template_directory_uri durch get_stylesheet_directory_uri ersetzt, damit WordPress im richtigen Verzeichnis nachschaut (im Child-Theme und nicht im Haupt-Theme).
Und damit sollte das Plugin erfolgreich eingebunden sein.
Optional: Eigenes JavaScript als Datei einbinden
Oftmals muss man die Funktionen, die das jQuery-Plugin bereitstellt, auch noch aufrufen. Dies geschieht entweder direkt im Footer der Seite (also wahrscheinlich dann in footer.php) oder man lagert dies in ein eigenes Script aus. Gerade wenn es mehr Code wird, macht dies aus Organisations- und Performance-Sicht Sinn.
Nehmen wir also an, Du legst den JavaScript-Code in /js/scripts.js ab, dann musst Du noch einen weiteren wp_enqueue_script-Aufruf zu add_my_scripts hinzufügen:
add_action( 'wp_enqueue_scripts', 'add_my_scripts' );
function add_my_scripts () {
wp_enqueue_script(
'my-plugin', // eigener Name
get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
// jetzt noch eigenes Script laden
wp_enqueue_script(
'my-script', // eigener Name
get_template_directory_uri() . '/js/scripts.js', // Pfad
array('my-plugin') // Abhängigkeiten
);
}
Hier siehst Du folgende Änderungen im Aufruf:
- Das Script hat einen anderen Namen (
my-script)
- Der Pfad ist entsprechend anders (dieselben Regeln für ein Child-Theme gelten)
- Die Abhängigkeit ist nicht mehr
jquery, sondern jetzt my-plugin, also das Plugin, welches Du in Deinem Script benutzt. Man hätte auch noch jquery zusätzlich angeben können (dann als array('jquery', 'my-plugin')), aber da my-plugin schon jquery als Abhängigkeit hat, ist das nicht unbedingt notwendig.
Script-Versionen definieren
Der obige Aufruf von wp_enqueue_script funktioniert super, solange man immer dieselbe Version eines Scripts/Plugins nutzt. Aktualisiert man das Script aber, kann es je nach Caching-Setup dazu kommen, dass Benutzer noch die alte Version ausgeliefert bekommen. Um dies zu vermeiden, kann man an den Aufruf noch eine Versionsnummer übergeben, z.B. so:
wp_enqueue_script(
'my-script', // eigener Name
get_template_directory_uri() . '/js/scripts.js', // Pfad
array('my-plugin'), // Abhängigkeiten
'20160323'
);
Wie man sieht, wurde mangels offizieller Versionsnummer einfach ein Datum als Versions-String genutzt. Lädt man fertige Plugins aus dem Netz herunter, sollte man die offizielle Versionsnummer dort eintragen (immer als String).
Script im Footer laden
Nicht alles muss im Header der Seite geladen werden. Genauer genommen sollte eigentlich alles, was möglich ist, im Footer geladen werden. Dadurch kann eine Seite teilweise deutlich schneller angezeigt werden.
Um ein Script von WordPress in den Footer laden zu lassen, kannst Du einen weiteren Parameter an wp_enqueue_script anhängen:
wp_enqueue_script(
'my-script', // eigener Name
get_template_directory_uri() . '/js/scripts.js', // Pfad
array('my-plugin'), // Abhängigkeiten
'20160323', // Versionsnummer
true // lade es im Footer
);
Also einfach noch true anhängen und schon wird es im Footer geladen.
Scripts im Admin-Bereich laden
Wenn ihr das so, wie oben beschrieben, einbaut, dann werden die angegebenen Scripts nur im Frontend geladen. Normalerweise reicht das auch, denn es geht ja um das Theme und damit um die öffentliche Ansicht.
Wenn ihr aber jetzt Plugin- oder Theme-Entwickler seid, dann wollt ihr bestimmte JavaScript-Dateien ggf. auch im Admin-Bereich laden. Dazu nutzt ihr einfach eine andere Aktion, nämlich statt wp_enqueue_scripts dann admin_enqueue_scripts. Wichtig: Es geht hier um den Aktionsnamen, nicht etwa um die Funktion zum Definieren der Scripts, diese ist weiterhin wp_enqueue_script (Singular).
Das erste Beispiel würde also für den Admin-Bereich wie folgt aussehen:
add_action( 'admin_enqueue_scripts', 'add_my_scripts' );
function add_my_scripts () {
wp_enqueue_script(
'my-plugin', // eigener Name
get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
}
Ich hoffe, euch damit geholfen zu haben. Fragen könnt ihr gerne in den Kommentaren hinterlassen. Generell hilft auch, die Doku zu wp_enqueue_script und der zugehörigen Aktion wp_enqueue_scripts zu lesen oder aber Dinge einfach auszuprobieren.
Dienstag war kein guter Tag für die JavaScript-Welt. Denn so manch Entwickler staunte nicht schlecht, als sich sein JavaScript-Projekt nicht mehr zusammenbauen ließ. Grund dafür: Eine kleine JavaScript-Bibliothek namens left-pad wurde vom Autor aus dem Node Package Manager gelöscht.
Was ist NPM?
Der Node Package Manager (NPM) wurde einst für die JavaScript-Umgebung node.js ins Leben gerufen und ist ein System, bei dem JavaScript-Entwickler ihre Open Source-Bibliotheken registrieren können. Einmal auf NPM, können dann andere Entwickler diese Bibliotheken relativ einfach für eigene Projekte nutzen. Und weil NPM so praktisch ist, wird es inzwischen nicht nur für node.js-Projekte auf dem Server, sondern auch für die JavaScript-Entwicklung im Browser eingesetzt.
Eines dieser Pakete auf NPM war das Paket left-pad, was im Prinzip nicht mehr ist als ein 11-zeiliger Code-Schnipsel ist. Ein Schnipsel allerdings, den scheinbar viele Programmierer brauchten und deshalb in ihrer eigenen Bibliotheken via NPM eingebunden haben, die dann wieder in größeren Anwendungen genutzt werden. So kommen tausende von Projekten zustande, die direkt oder indirekt von left-pad abhängen.
Als nun left-pad Anfang der Woche plötzlich vom Autor aus NPM gelöscht wurde, brach daher das Chaos in der JavaScript-Community aus.
Am Anfang war ein Markenstreit
Doch wie kam es eigentlich dazu? Der Grund ist ein Streit zwischen dem Messenger Kik und , dem Autor von left-pad und einem Paket namens „kik„. Letzteres, so befand der Messenger Kik, könnte Verwirrung auslösen, da sie selbst auch planten, eine Open Source-Bibliothek zu veröffentlichen. Sie schrieben daher an Azer und baten ihn, auch aufgrund von Trademark-Regelungen, sein Paket umzubenennen. Doch Azer Koçulu verneinte.
Kik wandte sich dann an NPM Inc., die Firma, die das NPM-Repository hostet. Wie NPM Inc.-Mitgründer Isaac Z. Schlueter hier erklärt, haben sie daraufhin ihre Package Name Dispute Policy bemüht und auf dieser Grundlage entschieden, den Paketnamen dem Messenger zukommen zu lassen.
Azer Koçulu wollte das nicht auf sich sitzen lassen und hat all seine 273 Pakete von NPM entfernt, weil er meinte, dass NPM privates Land sei und er ja Open Source mache, um die „Macht dem Volke“ zu geben und eben nicht Firmen wie NPM Inc. oder Kik.
Das Resultat dieser Entscheidung war, wie gesagt, verheerend und das Problem wurde erst durch die Wiederveröffentlichung von left-pad durch einen anderen Autor gelöst (denn wenn ein Paket entfernt wird, wird der Name auch wieder frei).
Hat NPM Inc. richtig gehandelt?
In seinem Blogpost stellt Isaac nochmal seine Sicht der Dinge klar, nämlich dass
- es bei der Entscheidung nicht um das Markenrecht ging, sondern rein nach der Dispute Resolution gehandelt wurde.
- NPM das Paket left-pad nicht gestohlen habe, da die Lizenz des Pakets ausdrücklich eine Wiederveröffentlichung erlaubt
- sowohl Kik ihre neue Bibliothek hätten veröffentlichen können als auch Benutzer des alten kik-Pakets keine Beeinträchtigungen erfahren hätten, wenn Azer nichts getan hätte
Im Endeffekt besagt die Dispute Policy aber nur, dass NPM Inc. selbst eine Entscheidung fällt, wenn beide Parteien nicht innerhalb von ca. 4 Wochen zu einer eigenen Einigung kommen. Nach welchen Kriterien dann aber genau entschieden wird, ist dort leider nicht festgehalten. Das könnte man vielleicht noch verbessern oder zumindest im Nachhinein dokumentieren.
Eines aber lernt NPM aus diesem Debakel: Die Möglichkeit, einfach all seine Pakete aus dem Index zu nehmen, ist eine schlechte Idee. Hier wird also wahrscheinlich demnächst nachgebessert werden.
Meines Erachtens gibt es aber noch ein weiteres Problem: Man kann ein neues Paket unter gleichem Namen hochladen, wenn der Autor das alte Paket gelöscht hat. Wenn es sich bei dem neuen Paket um Malware handelt und ein Entwickler nicht aufpasst, hat man plötzlich eine Sicherheitslücke im eigenen Projekt. Auch hier sollte man vielleicht noch nachbessern.
Was die Aufstellung von NPM als private Firma betrifft, kann man ebenfalls Bauchschmerzen haben. Das Python-Pendant PyPI z.B. wird von der Python Software Foundation betrieben (war vorher aber auch in privater Hand, wenn ich mich recht erinnere). Das gibt der Community zumindest theoretisch mehr Mitspracherecht.
Hat Kik richtig gehandelt?
Trademark ist natürlich Trademark und auch wenn ich kein Anwalt bin, so weiß ich doch, dass man ein Trademark auch verteidigen muss. Denn sonst verliert man die Marke. So kann man das auch in diesem Fall sehen und Mike Roberts von Kik schreibt das ja auch genau so in einer Mail an Azer. Ob die Anfrage allerdings jetzt so freundlich formuliert ist, wie er meint, sei mal dahingestellt:
We don’t mean to be a dick about it, but it’s a registered Trademark in most countries around the world and if you actually release an open source project called kik, our trademark lawyers are going to be banging on your door and taking down your accounts and stuff like that — and we’d have no choice but to do all that because you have to enforce trademarks or you lose them.
Das hätte man sicher auch anders formulieren können, wobei aber auch Azer nicht gerade kompromissbereit war:
Sorry, I’m building an open source project with that name.
Mit ein bisschen mehr Wohlwollen von beiden Seiten hätte man die Situation sicherlich verhindern können.
Eine Frage, die sich mir allerdings noch stellt (bin ja kein Anwalt): Wie problematisch ist es für eine Marke, wenn eine Open Source-Bibliothek den gleichen Namen trägt? Schliesslich gibt es ja auch Bibliotheken, die z.B. die Twitter-API nutzen und „twitter“ heissen, aber nicht von Twitter veröffentlicht worden sind. Oder wie in diesem Fall, wo sich „kik“ ja mehr an „Kickstarter“ anlehnt und etwas ganz anderes macht als einen Messenger-Dienst zu implementieren.
Was lernt die JavaScript-Community daraus?
Interessanterweise führt dieser Vorfall zu viel weitreichenderen Diskussionen als nur NPM in der JavaScript-Welt. Da geht es dann nämlich plötzlich um das Paket left-pad selbst, das ja aus nur 11 Zeilen besteht. So fragt sich David Haney, wieso dazu überhaupt eine Bibliothek genutzt werden muss. Man hätte das ja als Entwickler auch schnell selbst implementieren können. Er analysierte daraufhin auch noch weitere Projekte auf NPM und fand solche, die aus nur 4 Zeilen oder gar nur 1 Zeile Code bestehen. Der 1-Zeiler hat dabei fast 1 Million Downloads pro Tag.
Er fragt daher, ob man denn verlernt habe zu programmieren oder ob man es als Job eines Entwicklers ansehe, die kleinstmögliche Anzahl von Code-Zeilen selbst geschrieben zu haben. Eine wilde Diskussion auf Hacker News ist die Folge.
Go- und JavaScript-Programmierer Felix Geisendörfer sieht allerdings nicht die Entwickler selbst als die Schuldigen an, sondern die Entscheidung von node.js, eine möglichst kleine Standard-Library haben zu wollen. Unix-Ansatz halt. Wäre ein left-pad standardmäßig dabei, wäre ja eine solche Abhängigkeit gar nicht nötig.
Und auch ECMAScript (sozusagen der offizielle Name von JavaScript) sei Teil des Problems, denn die kommen ja mit überhaupt keiner Standard-Library daher (stimmt nicht so ganz, aber es ist wenig und fest in die Sprache integriert). Historisch bedingt ist das auch kein Wunder, war sie doch zunächst nur als kleine Browser-Sprache konzipiert. Hätte man aber natürlich inzwischen ändern können.
Sie sehen gerade einen Platzhalterinhalt von Standard. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Weitere Informationen
Laut Antworten auf seinen Tweet sind aber sowohl node.js als auch ECMAScript dabei, selbst ein leftpad nativ zu implementieren. Insofern würde zumindest diese Abhängigkeit in Zukunft nicht mehr nötig sein.
Beim aktuellen Fall hätte dies geholfen, aber es gibt bestimmt noch weitere populäre Pakete, die vielleicht nicht ganz so klein sind, aber bei Löschung eine ähnliche Auswirkung hätten.
Das aktuelle Problem ist gelöst, aber die Diskussionen halten noch an. Und dass ein eher kleiner Markenstreit solche Auswirkung hat, hätte ich auch nicht gedacht. Aber manchmal braucht es vielleicht ein Gewitter, damit man danach klarer sehen kann.
Beim Barcamp Ruhr 9 am letzten Wochenende hat Michael Janssen von zedwoo gleich zwei Sessions zum Thema Google Analytics gehalten. Die eine hatte den Titel „Wie ich mir meine Google Analytics-Daten kaputt spiele oder die 7 Todsünden“. Ich habe das zwar auch auf Twitter dokumentiert, aber da man das ja ggf. schlecht wiederfindet, kommt hier noch eine (auch ausführlichere) Mitschrift.
1. Den Analytics-Code 2 mal einbauen
Wer das tut, hat eine Absprungrate von 0, denn als Absprungrate wird der Prozentsatz der Besuche einer einzelnen Seite bezeichnet. Wer den Code allerdings 2 mal eingebaut hat, der hat auch direkt zwei Hits und damit niemals einen Absprung. Sieht man das also in der Analyse, sollte man seinen Source-Code einmal überprüfen.
Bei einem Blog ist eine hohe Absprungrate übrigens ok, denn Fans des Blogs kommen meist für den neuen Artikel, lesen ihn und sind dann wieder weg. Um diese besser zu tracken, wäre ggf. ein Scroll-Event sinnvoll. Damit kann man herausbekommen, ob sie den ganzen Artikel gelesen haben.
2. Es werden zu viele Sitzungen gezählt
Zur Erinnerung: Eine neue Sitzung wird genau dann erzeugt, wenn man entweder 30 Minuten nichts mehr auf der Site gemacht hat oder über eine andere Kampagne wiederkommt. Dies kann bei Online-Shops z.B. dadurch passieren, dass man für die Zahlung zu PayPal weitergeleitet wird und dann wieder auf den Shop zurück kommt. Weil man von einer verweisenden Seite kommt, zählt Google Analytics das als Kampagne und macht eine neue Sitzung auf.
Wer dies verhindern will, kann PayPal von den Verweisen ausschliessen. Dann zählt es nicht mehr als neue Kampagne und die Sitzung bleibt erhalten.
3. Referrer fallen unter Other
Wenn man unter Akquisition -> Channels viele Einträge unter „(Other)“ hat, dann bedeutet das, dass Google das nicht richtig zuordnen konnte, z.B. wegen fehlenden Referrer. Wer dies vermeiden will, der kann
Wenn man Referrer nicht taggt, dann werden viele unter Other einsortiert und man kann sie nicht näher aufschlüsseln. Hier hilft die explizite Auszeichnung von URLs mit Hilfe des Tools zur URL-Erstellung von Google. Beim Medium sollte man dann nach Möglichkeit einen vordefinierten Wert nehmen, damit es nicht unter „Other“ auftaucht.
4. Die eigene Homepage als Startseite
Gerade in großen Firmen wird es zum Problem, wenn die eigene Homepage als Startseite gesetzt wird. Dies führt nämlich zu vielen Page Views, die in Wirklichkeit gar keine sind. Hier sollte man also darauf achten, diese Zugriffe per IP oder über ein Cookie auszuschliessen (bei WordPress macht das z.B. das Yoast-Plugin beim Einloggen automatisch).
5. Bots nicht rausgefiltert
Auch Bots sollten natürlich herausgefiltert werden, um die Daten sauber zu halten. Google hat dazu eine Liste von Standard-Bots, die man in den Einstellungen zur Datenansicht aktivieren kann. Hierbei erwähnte Michael auch, dass es generell sinnvoll ist, immer mindestens 2 Datenansichten zu haben, wobei eine die Rohdaten sind, wo nichts gefiltert wird. Dies hilft dabei, Probleme zu erkennen und im Zweifel auf die Rohdaten zurückgreifen zu können.
6. Parameter nicht herausgefiltert
Man sollte aufpassen, welche Parameter man an den URLs hängen hat und diese ggf. herausfiltern, weil sonst jede URL als separate Seite gilt. Dies kann passieren, wenn man z.B. eigene Parameter für Kampagnen benutzt. Auch dies kann in den Einstellungen zur Datenansicht erledigt werden.
Wer keine Ziele in Google Analytics definiert hat, braucht es gar nicht erst nutzen
7. Keine Ziele definiert
Michael war da etwas dogmatisch und meinte: Wer keine Ziele in Google Analytics definiert hat, braucht es gar nicht erst nutzen. Man solle sich immer die Frage stellen, was man denn mit seiner Website oder Blog erreichen will. Nicht immer muss das Ziel dabei ein Verkauf sein, es kann auch einfach sein „hat Kontaktseite aufgerufen“, „war länger als 60s auf der Site“, „hat bis zum Ende der Seite gescrollt“.
Das waren auch schon die 7 Todsünden, zumindest nach Michael. Ich hoffe, ich habe alles korrekt wiedergegeben, ansonsten Anmerkungen oder weitere Todsünden gerne noch in den Kommentaren. Vielen Dank nochmal an Michael für die Session.
Zahlen und Analyse sind ja immer gut, vor allem, wenn es um Marketing geht. Schliesslich will man wissen, was gut und was weniger gut funktioniert. Bei hubspot haben Sie daher mal untersucht, wie ihr Blog eigentlich Leads generiert. Leads bei denen sind z.B. der Download einer freien Ressource mit vorheriger Registrierung. Zur Lead-Generierung selbst nutzen sie verschiedene Calls-to-Action (CTAs), hatten aber nur Daten zu allen CTA-Arten insgesamt.
Lead-Generierung durch Anchor Text-CTAs
Nachdem sie die einzelnen CTAs mit verschiedenen Tracking-Codes ausgestattet und ein bisschen gewartet haben, war das Ergebnis für sie überraschend: Es sind nämlich nicht die CTAs am Seitenende (meist ein Banner-Ad), die den Großteil der Leads ausmachen. Sie tragen nämlich nur 6% dazu bei. Stattdessen sind es (wie sie es nennen) die Anchor Text-CTAs. Dies sind im Prinzip nur verlinkte Headlines in der Mitte des Artikels, die eine entsprechende Marketing-Botschaft enthalten („Laden Sie xyz jetzt hier herunter“). Dies schlagen mit einer Rate von 47% bis 93% zu Buche.
Sie haben auch noch einen weiteren CTA im Werkzeugkasten, nämlich im Prinzip einfache Links an der richtigen Stelle. Einerseits direkt ohne Marketingbotschaft verlinkt, andererseits mit Botschaft und etwas klarer abgesetzt. Zusammen kommen die Anchor Text-CTAs und die Links dann auf 83% bis 93% der Leads.
Die Gründe, die sie dazu anführen sind einerseits Banner-Blindness und natürlich die Tatsache, dass man ggf. gar nicht bis zum Ende des Artikels liest.
Einbau erst nachträglich
Hubspot geht dabei nicht hin und baut die CTAs direkt beim Erstellen des Blog-Posts ein. Der Grund ist, dass bei der Veröffentlichung der meiste Traffic von den Newsletter-Abonnenten kommt, die ja schon Leads sind. Erst später bekommt der Post dann ggf. Suchmaschinen-Traffic von neuen Personen und erst da macht dann die Lead-Generierung Sinn. Zudem wissen sie dann auch, für welche Posts genau es Sinn macht und wonach genau gesucht wurde.
Klar sollte sein, dass das pro Blog und Website anders sein kann. Man kommt also auch hier nicht drumherum, die Performance der eigenen Call To Actions zu messen und mit verschiedenen Formaten herum zu experimentieren.
Wer kennt das nicht: Man ist mit einem Mobilgerät unterwegs und versucht, eine Website zu laden, aber es dauert und dauert und dauert. Irgendwann gibt man auf. Leider sind aktuelle Forschungsergebnisse nur schwer zu finden, in einem Report von KISSMetrics aus dem Jahr 2011 ist jedoch nachzulesen, dass 47% der Benutzer eine Website problematisch finden, die länger als 2 Sekunden lädt. Das mag sich im Laufe der Zeit noch verschärft haben, da man früher vielleicht mobilen Websites gegenüber noch etwas nachsichtiger war. Im News-Bereich versuchen Facebook und Google dem nun zu begegnen, einerseits durch Facebook Instant Articles, andererseits durch Accelerated Mobile Pages. Beides Lösungen, die den einerseits die Datenmenge reduzieren und andererseits Seiten über das eigene CDN ausliefern.
Facebook Instant Articles
Facebook’s Antwort heißt Facebook Instant Articles. Mit dieser Technologie werden Artikel direkt von Facebook gehostet und sollen dadurch bis zu 10 mal schneller laden. Dazu muss man als Publisher allerdings die diversen Spezifikationen (und damit Einschränkungen) von Facebook einhalten. So kann zwar eigene Werbung genutzt werden, man ist aber in Bezug auf die Platzierung eingeschränkter als auf der eigenen Website, auch wenn die Regeln inzwischen gelockert wurden. Alternativ kann Facebook die Werbung schalten, dann muss man aber auf 30% der Erlöse verzichten. Verfügbar ist die Technologie bislang nur für ausgesuchte Publisher, soll aber zur f8-Konferenz am 12. April dann für alle geöffnet werden. Es ist jedoch ein etwas aufwändigerer Prozess zu durchlaufen, bevor man aufgenommen wird.
Da es rein um eine mobile Optimierung geht, werden Facebook Instant Articles auch nur in der Facebook-App auf Android und iOS angezeigt. Es muss aber trotzdem zu jedem Artikel auch eine Version auf der Website des Publishers existieren, denn schliesslich kann die Seite ja auch per E-Mail, Twitter und Co. außerhalb von Facebook geteilt werden.
Wie gut funktionieren Facebook Instant Articles?
Viel Erfahrung gibt es noch nicht, da ja nur größere Publisher bislang an dem Programm teilnehmen durften. Klar ist aber, dass die SEO-Auswirkungen hier keine Rolle spielen, da es ja nur im mobilen Facebook-Ökosystem passiert. Und selbst dort werden Instant Articles im Newsfeed nicht besser gerankt als normale Artikel. Der Hauptvorteil ist daher vor allem die Geschwindigkeit (und ggf. die Möglichkeit, Facebook Werbung schalten zu lassen).
Bei Business Insider gibt es erste Reaktionen und Erfahrungen jener teilnehmenden Publisher. Diese reichen von super bis hin zu OK. So richtig schlecht scheint es für niemanden zu laufen, im Zweifel sieht man keine Änderung. So sehen manche Publisher einen Anstieg von Shares auf Facebook oder wiederholte Besuche. Selbst mehr Unique Visits auf der eigenen Webpräsenz will man verzeichnet haben. Es ist allerdings zu früh, um mit Sicherheit sagen zu können, ob da ein Zusammenhang besteht. Finanziell scheinen die Instant Articles ähnlich zu performen wie die eigenen mobilen Angebote. Bedenken müsse man, so Gawker-Gründer Nick Denton, dass keiner soviel über die Ad-Zielgruppe und Platzierung weiß, wie Facebook. Und das kann vielleicht gerade für kleinere Publisher positiv sein.
AMP-Seiten im Google News-Karussell
Was sind Accelerated Mobile Pages?
Google geht einen ähnlichen Weg und dort heißt das Projekt Accelerated Mobile Pages (kurz AMP), was sie in Zusammenarbeit mit zunächst 30 Publishern im Oktober 2015 ins Leben gerufen haben.
Im Vergleich zu Facebook Instant Pages ist allerdings AMP seit diesem Februar sehr wichtig für SEO, vor allem wenn man News oder Blog-Artikel veröffentlich. Seitdem werden AMP-optimierte Seiten nämlich in Suchergebnislisten ganz oben in einem Karussell angezeigt – zumindest, wenn sie als Top Story qualifizieren und man auf einem Mobilgerät darauf zu greift. Aber allein aus diesem Grund ist die AMP-Unterstützung schon ein Muss!
Technisch wird eine AMP-Seite in einer reduzierten HTML-Variante namens AMP-HTML erstellt. Sie enthält keinerlei JavaScript (außer der AMP-Library selbst) und darf nur bestimmte CSS-Elemente enthalten. Interaktive Elemente werden durch spezielle Tags implementiert, die dann durch die Library dynamisch ersetzt werden. So kann dann auch eine bestimmte Ladereihenfolge bestimmt werden. Jene Tags allerdings sind zunächst von Google und den mitwirkenden Technologiefirmen definiert. Da es kein offener Standard ist, bleibt die Frage, ob und wie man eigene Tags beisteuern kann.
Ähnlich wie bei Facebook soll auch eine AMP-Seite bis zu 10 mal schneller laden und sie wird zudem ebenfalls über das eigene Content Delivery Network ausgeliefert. Wer einmal durch das Karussell klickt, wird merken, dass man dabei die Google-Domain nicht verlässt.
Im nächsten Artikel beschreibe ich dann, wie man AMP mit WordPress benutzt.
Wie in diesem Artikel beschrieben, pusht Google gerade massiv ihr Accelerated Mobile Pages-Projekt (AMP). Kurz gesagt, geht es dabei darum, mobile Webseiten schneller ausliefern zu können. Bei AMP geschieht das dadurch, dass einerseits die Webseite auf das Wesentliche reduziert wird (kein JavaScript, wenig CSS, definierte Lade-Reihenfolge) und die Seiten durch Google’s CDN ausgeliefert werden.
Wichtig ist AMP vor allem inzwischen für Nachrichtensites und Blogs, da AMP-Seiten seit Februar in der Suche prominent ganz oben dargestellt werden (wenn man als Top-Story qualifiziert). Aus SEO-Sicht kommt man also eigentlich um AMP nicht herum.
Wenn Du also ein WordPress-Blog hast, dann solltest Du zusehen, dass Du AMP aktivierst, was zum Glück nicht wirklich schwer ist.
AMP-Seiten im Google News-Karussell
AMP in WordPress dank Plugin
Wie immer bei WordPress gibt es natürlich schon längst ein Plugin namens AMP, diesmal sogar auch direkt aus dem Hause Automattic
Installiert und aktiviert man dies, so werden alle Artikel (nicht Seiten) automatisch mit einer AMP-Variante versehen. Ansehen kann man diese, indem man einfach /amp/ an die URL anhängt, also z.B. https://comlounge.net/lead-generierung-call-to-actions/amp/. Es wird dabei nur der Post-Content genutzt und in einen einfachen Layout-Rahmen gesteckt. Hat man ein Site-Icon definiert, so wird dies ebenfalls im Header angezeigt.
Diese AMP-Seite wird dabei vom eigentlichen Beitrag automatisch über <link rel="amphtml" href="..." /> verlinkt und ist somit durch Google auffindbar.

Beispiel AMP-Seite
AMP anpassen
Da das Plugin selbst keinerlei UI hat und somit keine Design-Änderungen zulässt, muss man sich anders behelfen. Wer das Yoast SEO-Plugin nutzt, kann z.B. das Yoast SEO AMP Glue plugin installieren, das mehr Möglichkeiten eröffnet. Damit kann man AMP nicht nur für Artikel, sondern auch für Seiten und Medienobjekte aktivieren. Vor allem aber kann man die Farben und auch das Site-Icon ändern oder ein Default-Featured Image setzen. Ein solches Bild ist nämlich wichtig, damit Google die Seite richtig indiziert.
Wer ein Site-Icon nutzt, wird sich vielleicht ärgern, dass es rund ausgeschnitten wird, was sich nicht für jedes Logo eignet. Zum Glück kann man dies recht einfach im Custom CSS-Feld mit folgendem Code ausschalten:
nav.amp-wp-title-bar .amp-wp-site-icon { border-radius: 0; }
Das Yoast-Plugin kümmert sich weiterhin automatisch um die Einbindung von Analytics in die AMP-Seite, wenn man Google Analytics von Yoast installiert hat. Es kann aber auch ein manueller Tracking-Code angegeben werden.
Eine Alternative zu diesem Plugin, was ja sehr in das Yoast-Ökosystem integriert ist, wäre das Plugin von Pagefrog, was nicht nur AMP-Versionen erstellt, sondern auch Versionen für den Facebook Instant Articles oder Apple News. Allerdings stellt man sich im Forum schon die Frage, ob es noch weiterentwickelt wird, da man von den Entwicklern nichts mehr hört. Da die letzte Version aber nur 2 Wochen alt ist (beim Yoast-Plugin gerade aber ähnlich), sollte man das vielleicht erstmal beobachten. Im Zweifel sollte man sicherlich beide Plugins mal ausprobieren und schauen, was für einen selbst besser funktionieret.
Featured Image anzeigen
Wenn vom Featured Image die Rede ist, so muss man unterscheiden zwischen dem, was Google indiziert und dem, was angezeigt wird. Standardmäßig wird nämlich das Bild gar nicht ausgegeben, sondern nur in den Metadaten aufgelistet. Das ist für Google ausreichend, um es im News-Karussell anzuzeigen, schön wäre aber dennoch, das auch auf der Seite sehen zu können.
Hat man sein eigenes Theme, kann man dies wie folgt in der functions.php lösen:
add_action( 'pre_amp_render_post', 'xyz_amp_add_custom_actions' );
function xyz_amp_add_custom_actions() {
add_filter( 'the_content', 'xyz_amp_add_featured_image' );
}
function xyz_amp_add_featured_image( $content ) {
if ( has_post_thumbnail() ) {
// Just add the raw <img /> tag; our sanitizer will take care of it later.
$image = sprintf( '%s', get_the_post_thumbnail() );
$content = $image . $content;
}
return $content;
}
Weitere Möglichkeiten, um seine AMP-Seite anzupassen, sind in diesem README aufgelistet.
Post-Inhalte mit Shortcodes anreichern
Noch ein kleiner Tipp zum Ende: Die AMP-Version einer Seite beinhaltet wirklich nur den Artikelinhalt und keine anderen Elemente (z.B. Ausgaben von anderen Plugins, die über oder unter einem Artikel erscheinen, wie z.B. verwandte Beiträge oder Werbung). Wer dies in der AMP-Version (für RSS gilt wohl dasselbe) mehr als nur den Inhalt ausliefern möchte, muss dies in den Artikel direkt reinschreiben. Dies kann z.B. mit Shortcodes gelöst werden, wobei man aber beim Schreiben dran denken muss, es auch wirklich manuell reinzuschreiben. Da der Shortcode Teil des Beitrags ist, erscheint die Ausgabe dann auch in der AMP-Version.
Die Shortcodes selbst können dabei entweder von bestehenden Plugins kommen oder man kann sie als Entwickler selbst im Theme definieren. Wichtig ist dabei nur, dass kein JavaScript funktioniert und das CSS entweder über das Custom CSS-Feld des Yoast-Plugins oder aber auch in der functions.php speziell für AMP eingebunden werden muss. Für Werbung wird wahrscheinlich ein Bild mit Link am besten funktionieren.
Fazit
Generell ist die Aktivierung von AMP dank des Plugins recht einfach. Man sollte allerdings in der Suchkonsole darauf achten, dass Google die AMP-Seiten auch richtig indiziert. Zudem steckt AMP und vor die Wordpress-Integration noch ein bisschen in den Kinderschuhen. Da wird sicherlich in Zukunft noch einiges passieren, sowohl am Standard als auch an der WordPress-Implementierung. Wir werden euch auf dem Laufenden halten!
Wer kennt das nicht: um die eigene Homepage kümmert man sich zuletzt (scheinbar gerade als Web-Agentur). Ein Fehler natürlich, denn schliesslich ist die Homepage nicht nur zum Selbstzweck da, sondern soll ja vielleicht auch mal irgendwie einen Kunden generieren. Und aus diesem Grund sind auch wir mal hingegangen und haben alles schön neu gemacht. Dauert dann auch länger als man denkt 😉
Ich wollte erst schreiben: „Und nun ist sie fertig“, ist sie aber natürlich gar nicht, denn gepflegt werden will sie ja auch. Und so plane ich auch, mal wieder regelmäßig zu bloggen und generell hier aktiver zu sein.
Wer ansonsten wissen will, was wir eigentlich tun, kann sich „Was wir können angucken“ oder aber in unsere Case-Studies schauen. Da kommen auch demnächst noch ein paar mehr hinzu (und leider darf man ja auch nicht über alles sprechen, auch wenn es spannend ist).
Technik: HTTP/2, Responsive, AMP
Technisch ist auch etwas passiert: So baut sie nun nicht mehr auf Plone, sondern auf WordPress auf. Das Theme ist eine Eigenentwicklung und baut auf Bootstrap auf und zudem kommt Beaver Builder zum Einsatz, was ich sehr praktisch finde, um etwas komplexere Layouts schnell umsetzen zu können. Es hat auch seine Tücken, aber es ist insgesamt deutlich schneller, als wenn ich alles in CSS und Shortcodes bauen würde.
Die Website läuft nun auch rein unter https und nutzt HTTP/2 (unter nginx), um maximale Performance zu erzielen. Auch der Inhalt wurde dementsprechend optimiert (mehr geht natürlich immer, aber ich bin erstmal zufrieden). Zudem haben wir das Accelerated Mobile Pages-Plugin installiert und angepasst, so dass Google im Zweifel auch hier glücklich sein sollte und die mobile Performance optimal ist. Responsive ist sie natürlich auch.
Blogging
Wie schon erwähnt, will ich mehr bloggen (heute heißt das ja Content Marketing) und die Themen werden sich rund um Python-, WordPress- und Web-Entwicklung generell drehen, aber auch Bürgerbeteiligung und Marketing sollen ihren Platz haben. Ein paar neue Artikel habe ich schon geschrieben, weitere sind in der Pipeline und weitere Ideen habe ich auch schon.
Wer ansonsten wissen will, was wir eigentlich tun, kann sich „Was wir können angucken“ oder aber in unsere Case-Studies schauen. Da kommen auch demnächst noch ein paar mehr hinzu (und leider darf man ja auch nicht über alles sprechen, auch wenn es spannend ist). Ansprechen darf man uns natürlich auch!
In meinem ersten Tutorial auf diesem Blog will ich darstellen, wie man Gemeindegrenzen auf einer Auf Open Street Map basierenden Karte darstellen kann. Die Gemeindegrenzen (in diesem Fall NRW) selbst nehme ich dabei nicht direkt von OSM, sondern aus einem Shapefile, das ich in diesem Fall von der Seite zur Landtagswahl des Innenministeriums herunterlade. Als Grundlage für die OSM-Darstellung nehme ich die JavaScript-Library leaflet.js.
Shapefile in GeoJSON überführen
Die Hauptaufgabe ist nun, das Shapefile mit den Gemeindegrenzen in das GeoJSON-Format zu überführen, denn dies ist das Format, das leaflet erwartet. Lädt man die Geometrie der Gemeinden (direkter Downloadlink) herunter und entpackt das ZIP-File, so erhält man folgende laut zu einem Shapefile zugehörigen Dateien:
DVG1_Gemeinden_utm.dbf
DVG1_Gemeinden_utm.prj
DVG1_Gemeinden_utm.shp
DVG1_Gemeinden_utm.shx
Wichtig ist dabei im Prinzip nur die Datei mit Endung .shp, da diese die eigentlichen Geometrien enthält.
Um diese Datei in GeoJSON umzuwandeln gibt es zum Glück ein Tool, dass sich ogr2ogr nennt und im GDAL-Paket zu finden ist. Unter OSX kann man dies mit macports wie folgt installieren:
sudo port install gdal +geos
Bevor man die Konvertierung startet, muss man zwei Dinge beachten. Zunächst einmal die Art der Projektion. So gibt es verschiedene Verfahren, die Erdkugel auf eine rechteckige Karte zu projizieren. Das Shapefile benutzt UTM (wie im Dateinamen zu erkennen), leaflet bzw. OSM mag aber lieber EPSG:3857. Hier muss man also entweder umrechnen oder in leaflet die Projektion umstellen, was mit dem Plugin Proj4Leaflet geht. Ich werde hier aber die Daten schon vorher auf die Ziel-Projektion umrechnen.
Das zweite Problem ist die Datenmenge. Die Definition der Gemeindegrenzen ist nämlich sehr genau, was bedeutet, das die Polygone sehr viele Punkte beinhalten. Dies bedeutet aber, dass die Karte eher behäbig daherkommt. Da es bei der Darstellung aber eher auf die Flächen ankommt und man sowieso nicht bis auf den letzten Stein herunter zoomen kann, können und sollten diese Polygone vereinfacht werden.
Beide Probleme lassen sich glücklicherweise direkt mit ogr2ogr lösen und der zugehörige Aufruf sieht wie folgt aus:
ogr2ogr -f geojson -simplify 20 -t_srs EPSG:4326 -a_srs EPSG:4326 gemeinden.json DVG1_Gemeinden_utm.shp
Die einzelnen Argumente bedeuten dabei folgendes:
- -f geojson definiert das Zielformat, das wir wünschen
- -simplify 20 vereinfacht die Polygone. Mit dem Faktor 20 erhält man dabei statt einer 43 MB-Datei eine nur 4,9 MB grosse Datei. Den Wert habe ich dabei durch Ausprobieren ermittelt, indem ich mehrere Werte angegeben habe und auf der Karte geschaut habe, wo die Polygone zu grob wurden.
- – t_srs EPSG:4326 definiert die Ziel-Projektion
- -a_srs EPSG:4326 definiert die Ausgabe-Projektion (was genau der Unterschied zu oben ist, ist mir leider nicht so klar, aber so funktioniert es)
Eine Besonderheit von ogr2ogr ist dabei, dass zunächst die Zieldatei angegeben wird und dann erst die Quelldatei. Also aufpassen!
Man beachte auch die Projektion, denn entgegen meiner vorherigen Behauptung mit EPSG:3857 arbeitet leaflet dann wohl doch lieber mit EPSG:4326 (wenn ich das richtig verstehe ist letztere der Koordinatensatz auf einer Kugel, während 3857 die projizierte Version ist. Ob leaflet das dann automatisch umrechnet, ist mir nicht so ganz klar, mit 4326 funktioniert es aber auf jeden Fall).
Hat man nun die Datei, muss man sie nur noch anzeigen. Dazu initialisiert man zunächst leaflet (und jquery gleich mit). Laden wir zunächst die notwendigen Dateien vom CDN:
<link rel="stylesheet" href="http://cdn.leafletjs.com/leaflet-0.5/leaflet.css" />
<script src="http://code.jquery.com/jquery-1.9.1.min.js"></script>
<script src="http://code.jquery.com/jquery-migrate-1.1.1.min.js"></script>
<script src="http://cdn.leafletjs.com/leaflet-0.5/leaflet.js"></script>
Dann noch ein bisschen CSS für eine Fullscreen-Map:
<style>
html, body, #map {
height: 100%;
}
</style>
Die Karte selbst ist nur ein DIV:
<div id="map"></div>
Dann brauchen wir noch Code zum Initialisieren der Karte grob auf NRW (ausserdem benötigt man noch einen API-Key von cloudmade.com, wobei man zum Experimentieren aber alternativ auf die Tiles von OSM nutzen kann. Die Nutzung ist dort allerdings eingeschränkt):
<script>
$(document).ready(function() {
var map = L.map('map').setView([51.463, 7.18], 10);
L.tileLayer('http://{s}.tile.cloudmade.com/API-KEY/{z}/{x}/{y}.png', {
attribution: 'Map data © <a href="http://openstreetmap.org">OpenStreetMap</a> contributors, <a href="http://creativecommons.org/licenses/by-sa/2.0/">CC-BY-SA</a>, Imagery © <a href="http://cloudmade.com">CloudMade</a>',
maxZoom: 18
}).addTo(map);
</script>
Nun müssen wir nur noch das GeoJSON-Objekt laden und anzeigen. Dies geschieht per getJSON-Aufruf:
$.getJSON("/gemeinden/gemeinden.json", function(data) {
L.geoJson(data, {
style: function(feature) {
switch (feature.properties.KN) {
default:
return {
fillColor: '#00'+(0x1000000+(Math.random())*0xffffff).toString(16).substr(1,2)+"00",
fillOpacity: 0.5,
weight: 2,
color: '#111',
opacity: 0.7,
dashArray: '4'
}
}
}
}).addTo(map);
});
Wichtig ist dabei hauptsächlich der Aufruf von L.geoJSON und der Angabe der Daten. Mit der style-Funktion ist man zusätzlich noch in der Lage einzelne Flächen einzufärben (hier per random-Grün), die Grenzen zu stylen usw. Mehr Informationen erhält man hier.
Ein komplettes Demo gibt es auch!
Heute habe ich dank des Ausfalls unseres Mailservers bei Strato den dort befindlichen Mailman auf unserem neuen Mailserver (kein Strato mehr) installiert. Da dabei ein paar Besonderheiten anfallen was die Kombination mit nginx betrifft, will ich das hier kurz dokumentieren, damit ich das beim nächsten Server schnell wieder parat habe. Ich gehe dabei davon aus, dass nginx schon installiert ist.
Zunächst einmal muss man mailman selbst installieren:
apt-get install mailman
thttpd
Da mailman auf cgi-bin aufbaut, nginx aber kein cgi-bin unterstützt, scheint der einfachste Weg zu sein, noch thttpd zu installieren (fastcgi geht theoretisch auch, wollte aber aus mir unbekannten Gründen kein PATH_INFO an Mailman weiterleiten):
apt-get install thttpd
Bei thttpd handelt es sich dabei um einen sehr kleinen HTTP-Server, der cgi-bin unterstützt und den wir als Proxy benutzen werden.
Dazu muss thttpd natürlich konfiguriert werden, was in der Datei /etc/thttpd/thttpd.conf passiert. Hier die wichtigsten Zeilen:
port=7999
dir=/usr/lib/cgi-bin
nochroot
user=www-data
cgipat=/**
host=127.0.0.1
Wichtig ist also, dass wir auf einem anderen Port als 80 laufen, dass wir nur auf 127.0.0.1 hören, dass wir kein chroot machen, unter www-data laufen und dass wir alle URLs als cgi-Scripts interpretieren und nicht nur die mit Prefix /cgi-bin/
Dann muss der Daemon noch ggf. in /etc/default/thttpd eingeschaltet werden und mit
/etc/init.d/thttpd start
gestartet.
nginx
Für nginx brauchen wir ggf. einen neuen virtual host, in den wir folgendes eintragen:
server {
listen 80;
server_name meinedomain;
access_log /var/log/nginx/domain.access.log;
error_log /var/log/nginx/domain.net.error.log;
location /mailman/ {
proxy_pass http://127.0.0.1:7999/mailman/;
proxy_set_header Host $host;
}
location /images/mailman {
alias /usr/share/images/mailman;
}
location /pipermail {
alias /var/lib/mailman/archives/public;
autoindex on;
}
}
Wir richten also einen ganz normalen reverse-Proxy ein.
Schliesslich müssen wir mailman nur noch sagen, dass er statt /cgi-bin/mailman jetzt auf /mailman/ hört. Dazu müssen wir die Datei /usr/lib/mailman/Mailman/mm_cfg.py anpassen, so dass die folgenden Zeilen darin vorkommen:
DEFAULT_URL_PATTERN = 'http://%s/mailman/'
PRIVATE_ARCHIVE_URL = '/mailman/private'
IMAGE_LOGOS = '/images/mailman/'
Nach Neustart von nginx sollte dann das Mailman-Interface unter http://domain/mailman/admin/[meineliste] zu finden sein.
Das funktioniert natürlich nur, wenn Mailman und die Mailingliste auch richtig eingerichtet wurde. Dazu gibt es hier weiterführende Doku.
Weitere Hinweise zur Mailman-Migration
Da ich bei der Migration auch die URL von cgi-bin/mailman auf /mailman/ geändert habe, müssen die Listen noch angepasst werden. Dies geschieht in /var/lib/mailman über den Befehl
bin/withlist -l -a -r fix_url
Der geht alle Listen durch und trägt dort das Default-URL-Pattern ein.
Foto CC-BY-NC-SA von Éole Wind
Am Freitag und Samstag letzter Woche war ich in Düsseldorf und habe am Videocamp und Webvideopreis teilgenommen (meine persönlichen Eindrücke hier und hier). Ich habe dort zusammen mit Michael Praetorius eine Session zum Thema Livestreaming gegeben und Alex Knopf hat es dankenswerterweise aufgenommen. Hier das Video:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Die Slides wird es dann später auch noch geben.
So wie man im Web wissen will, welche Browser am meisten genutzt werden, so ist im Bereich Newsletter-Marketing natürlich interessant, wie die Marktanteile bei E-Mail-Clients aussehen. Schliesslich geht es immer darum, an der richtigen Stelle zu optimieren. Direkt klar dürfte sein, dass die Desktop-Nutzung auch in diesem Bereich zurück geht und der Mobilbereich zulegt. Die Frage wäre noch, wie es im Webmail-Bereich aussieht.
Bei litmus haben Sie nun im Rahmen ihres „2016 State of Email“-Reports eine Analyse von 13 Milliarden E-Mails aus 2015 durchgeführt und die Ergebnisse sehen wie folgt aus: Apple Mail liegt mit 33% Marktanteil klar an der Spitze, gefolgt von GMail mit 15%, Apple iPad 12% und Google Android mit 10%.
Überraschung: Mobil nimmt zu, Desktop nimmt ab
Ok, kaum überraschend: Die mobile Nutzung ist allein 2015 um 17% auf 55% gestiegen (2008 waren es nur 8%). An zweiter Stelle steht Webmail mit 26% und dann kommt erst Desktop mit 19% (von ca. 35% 2014). Im mobilen Bereich ist Apple mit 45% Marktanteil insgesamt der klare Gewinner.
Obwohl Webmail verglichen mit 2014 wieder zugelegt hat, geht die Nutzung 2015 wieder zurück. An der Spitze ist immer noch GMail, verlor jedoch im Laufe des Jahres Marktanteil um die 8%. Litmus führt dies auf den schlechten Support für Responsive Design zurück, was Nutzer veranlasst, dann doch lieber den nativen Client zu nutzen. Ich persönlich finde das ja sehr verwunderlich, warum Google da keinen besseren Job macht.
Alle weiteren Informationen könnt ihr der Infografik unten oder dem Blog-Post bei litmus entnehmen.

Es tut sich was in Sachen Open Data und eine aktuelle Entwicklung will ich hier kurz beschreiben, nämlich die um das Transparenzgesetz NRW.
So gab es am Montag im Landtag NRW auf Einladung der Fraktion der Grünen ein Fachgespräch zum Thema Transparenzgesetz. Eingeladen waren Vertreter der Initiative aus Hamburg, die inzwischen ein solches Gesetz haben, aber auch Vertreter der Initiative NRW blickt durch. Dabei handelt es sich um einen Zusammenschluss von Mehr Demokratie e.V., dem Bund der Steuerzahler und Transparency International und ihr Anliegen ist, ein solches Transparenzgesetz auch für Nordrhein-Westfalen auf die Beine zu stellen.
(mehr …)
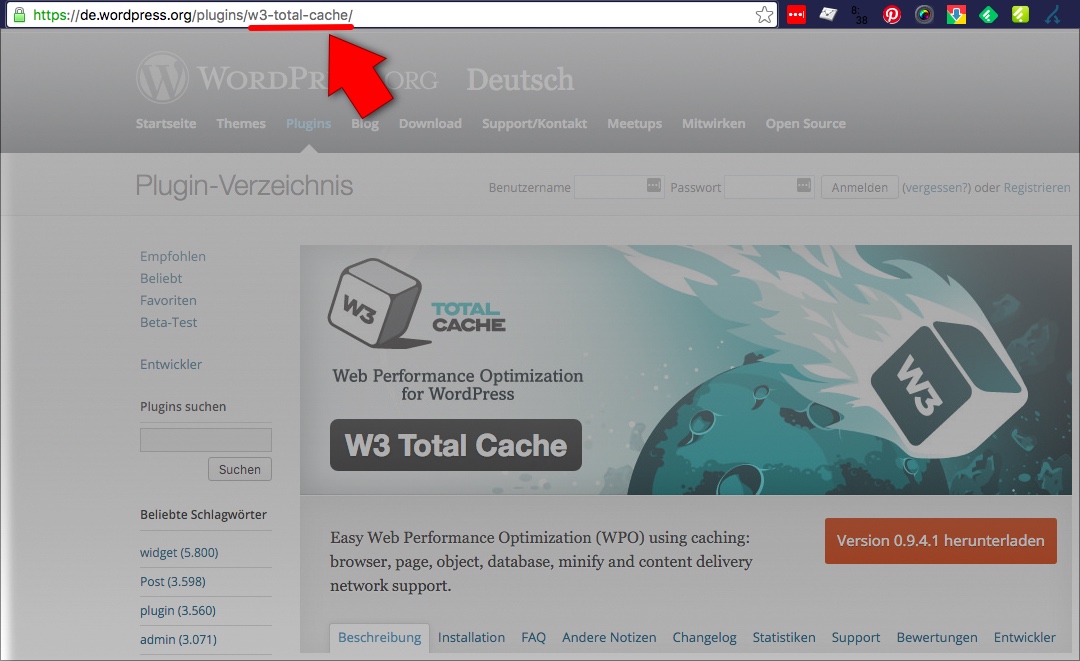
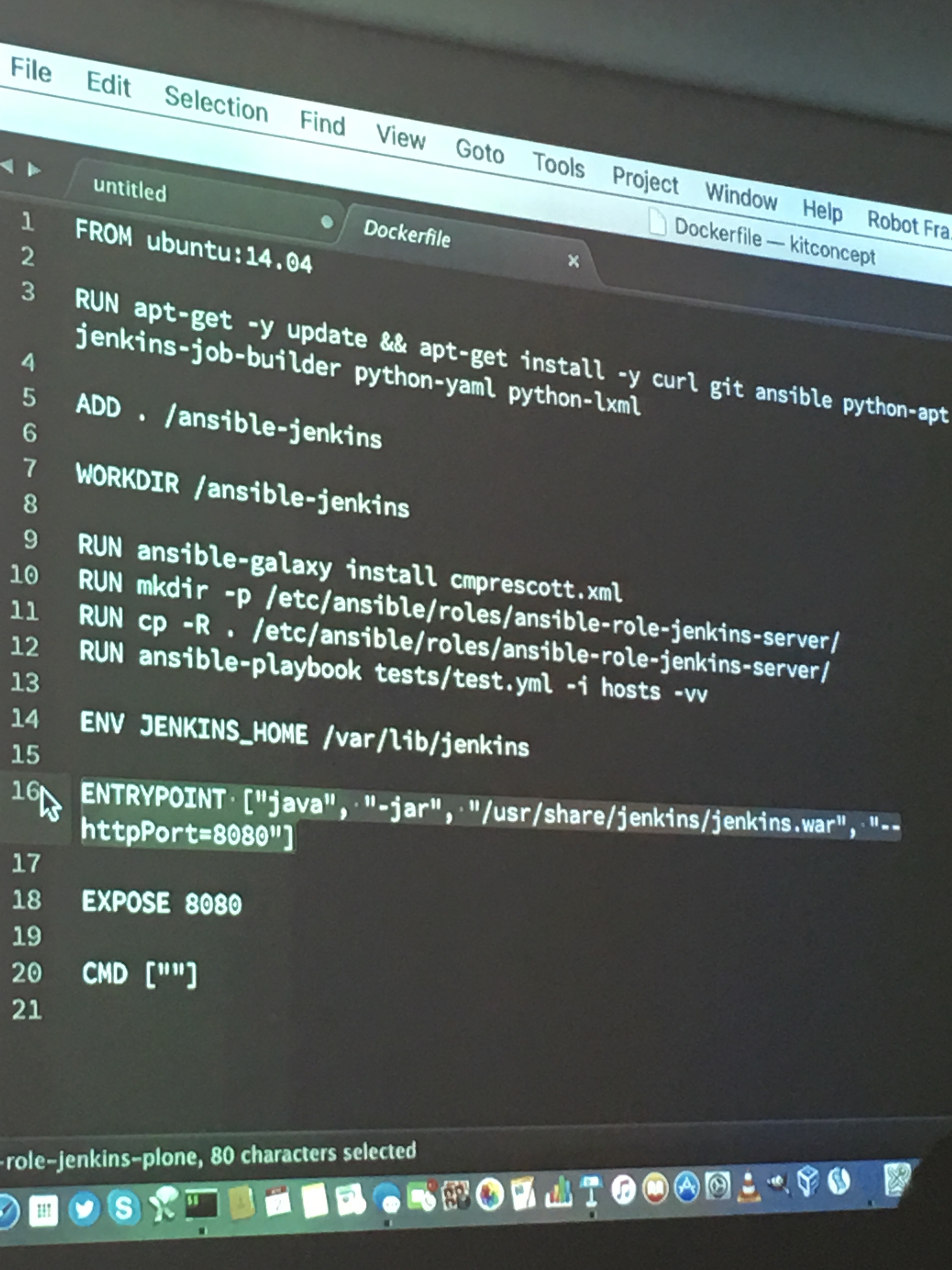

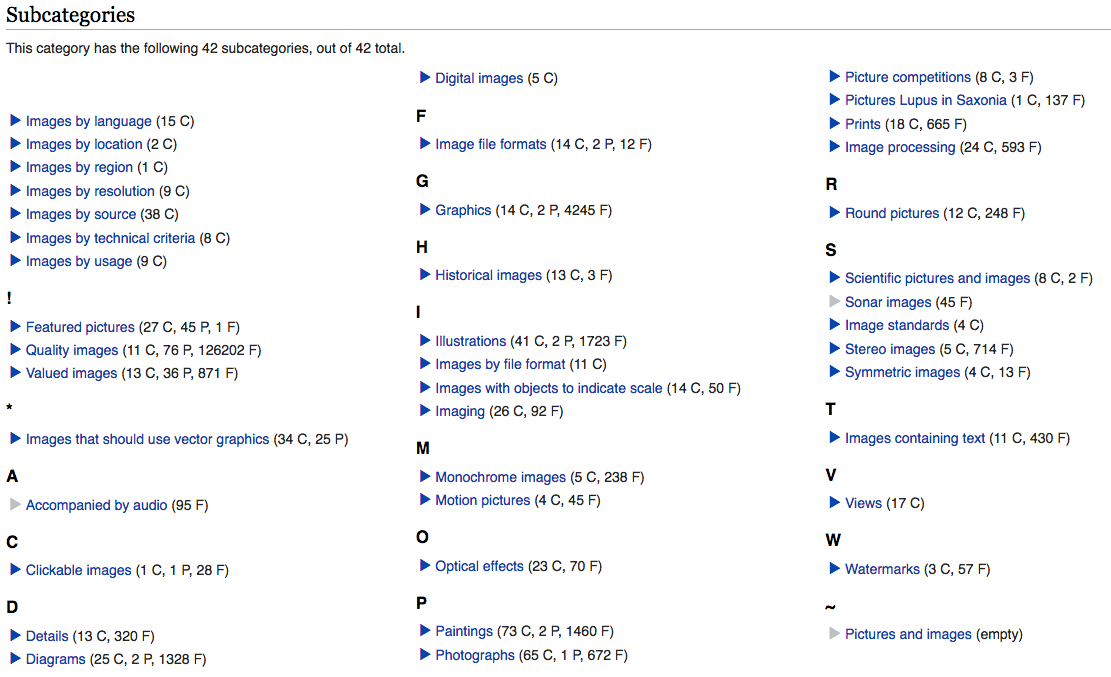
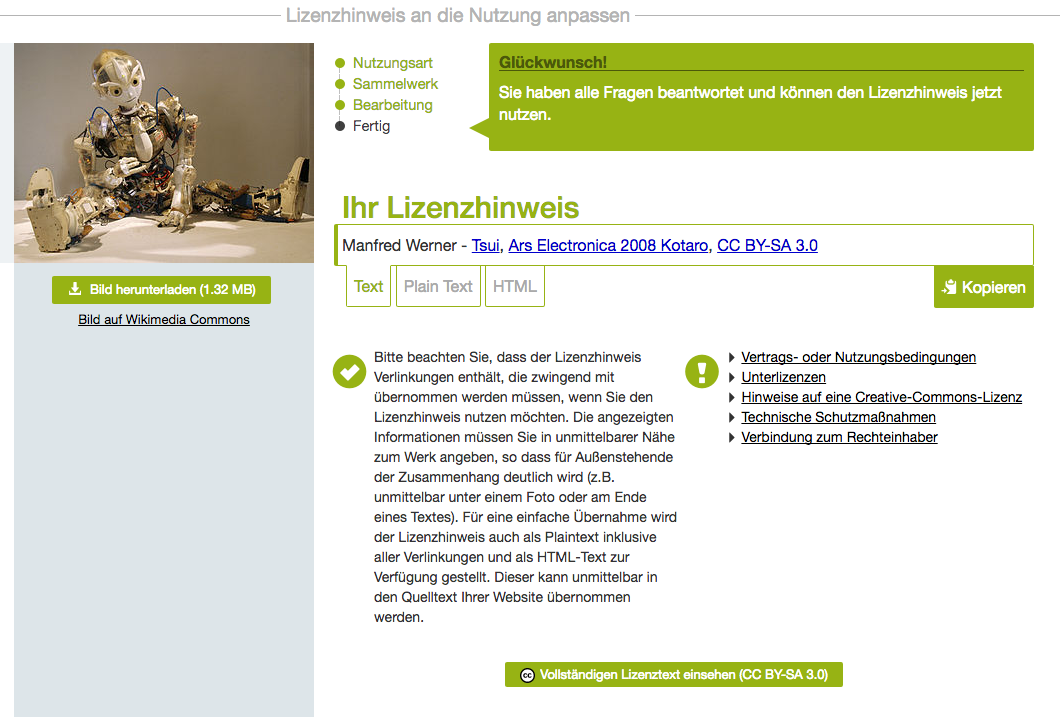
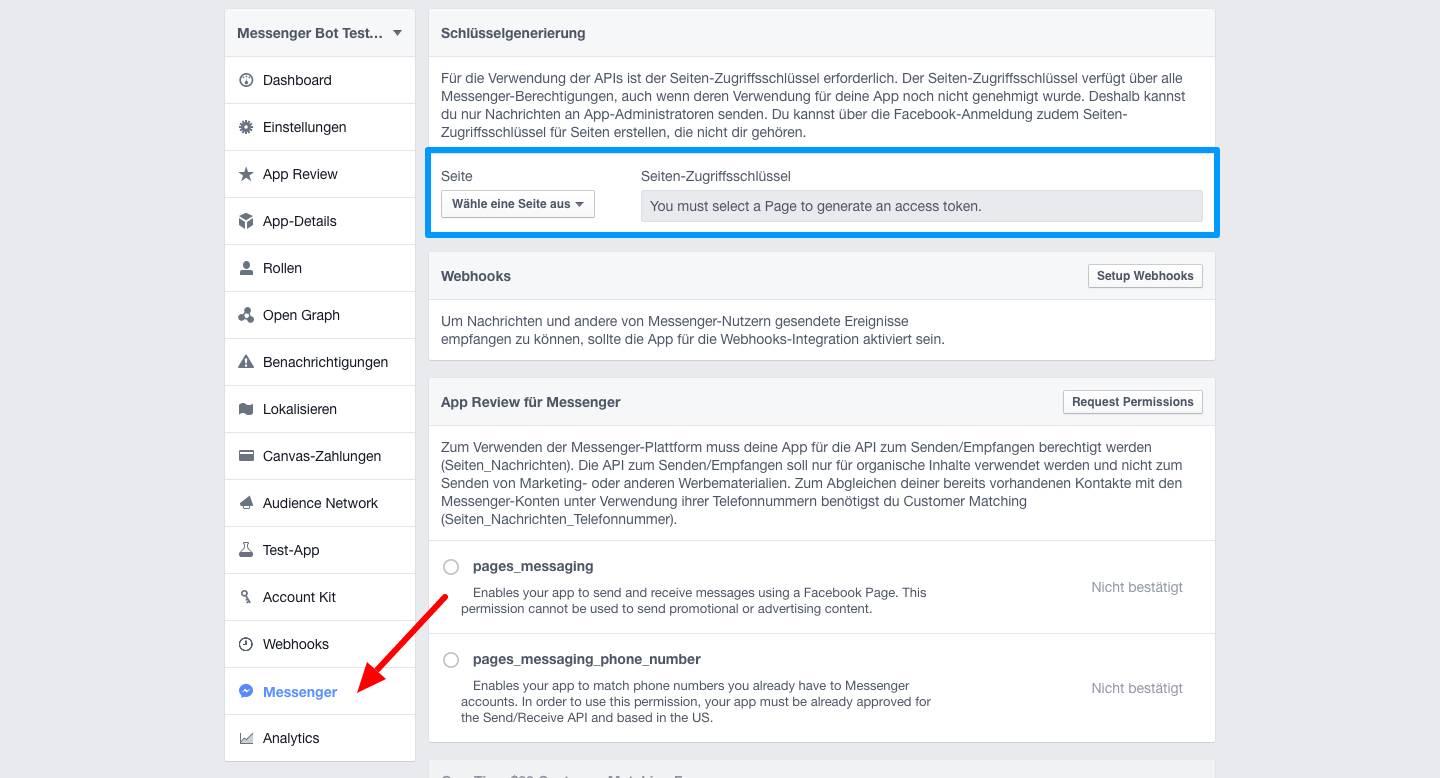
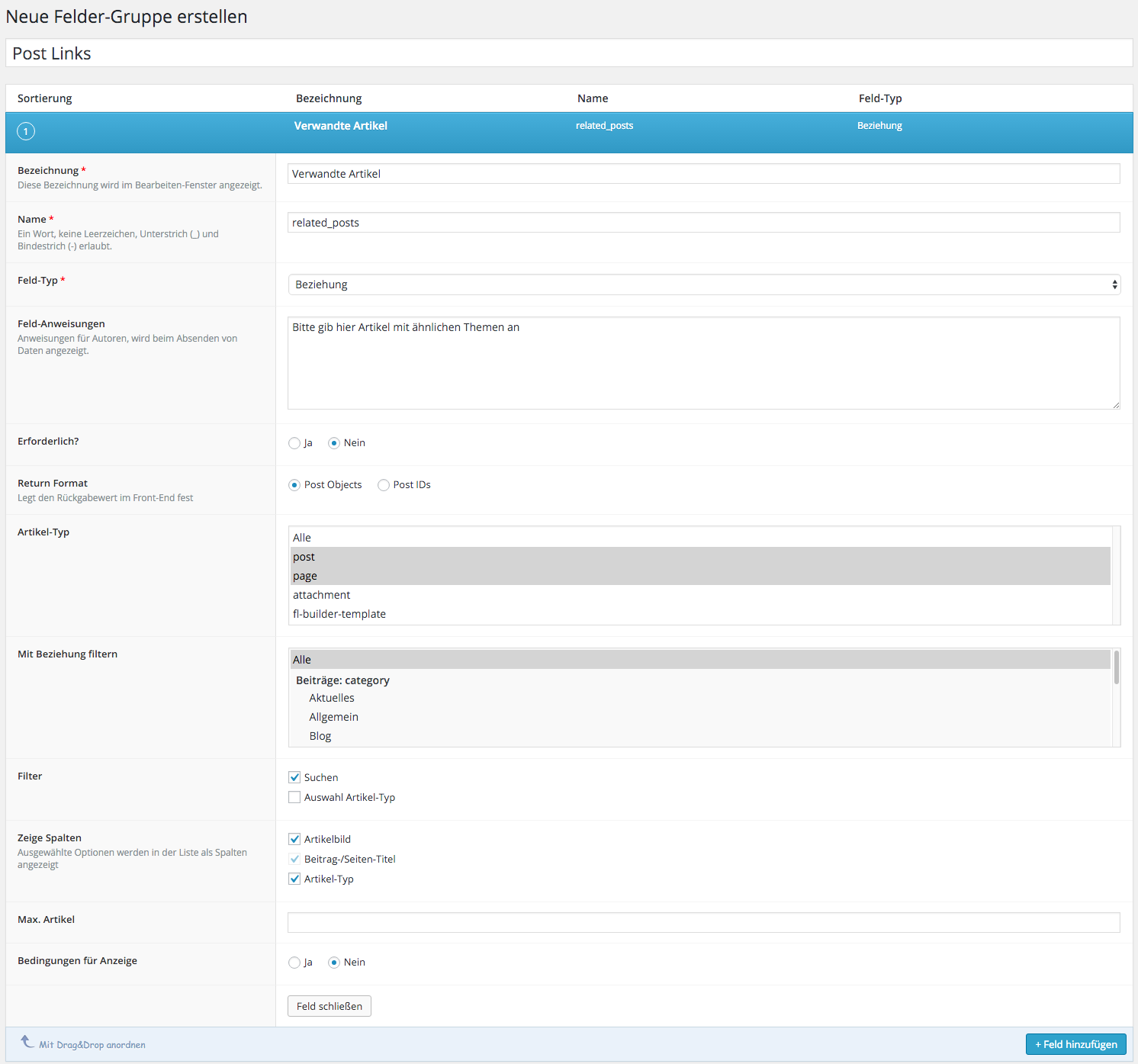

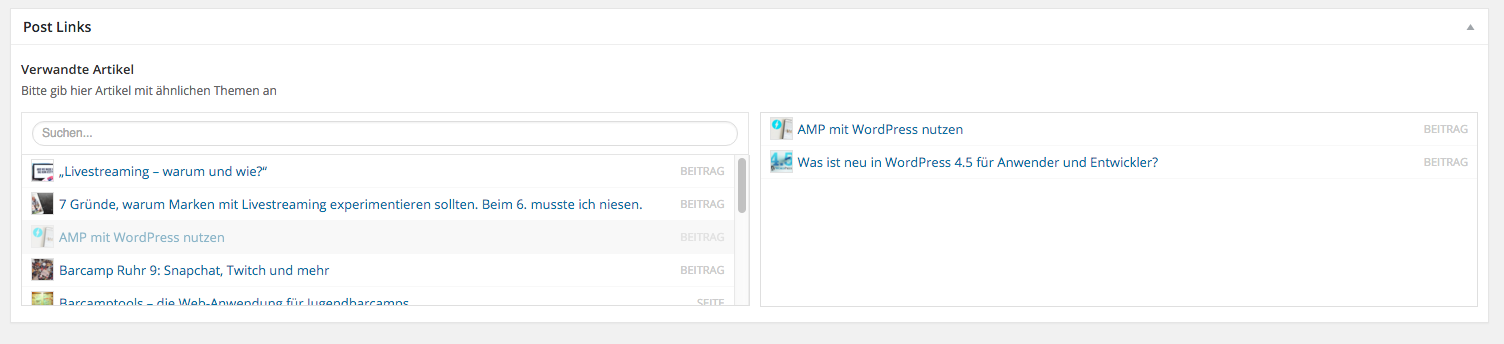
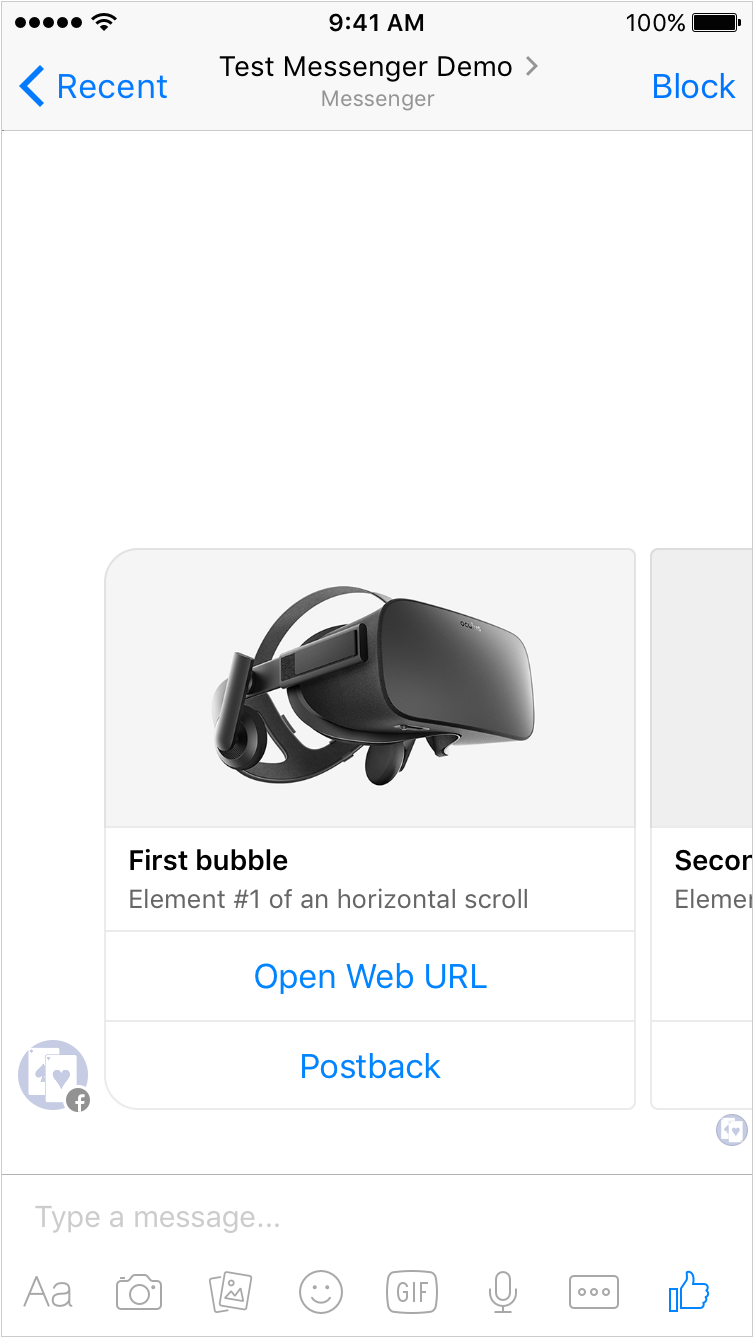





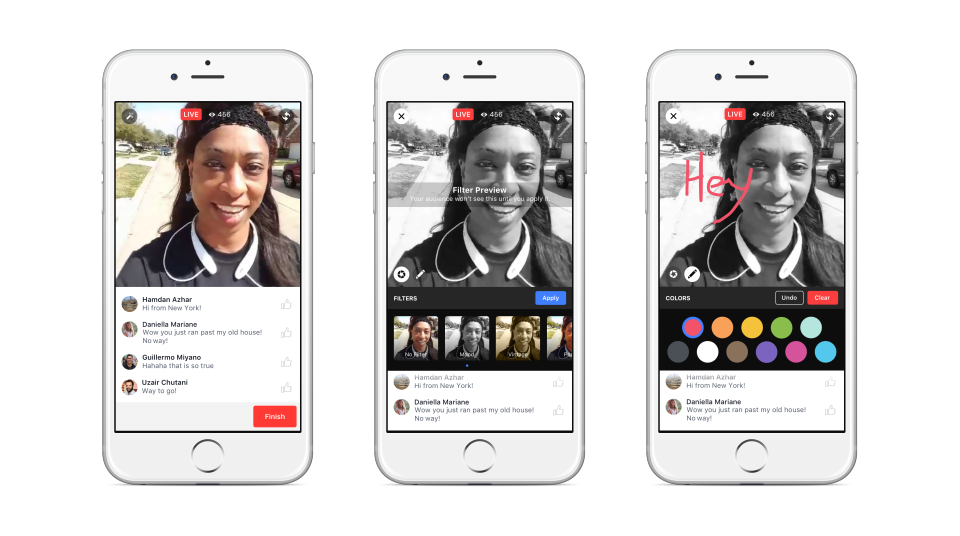
_–_Front.jpg){kind=link}
_Side.jpg){kind=link}