WordPress über das Web-Interface zu steuern ist recht komfortabel. Zumindest in vielen Fällen. Gerade als Linux-Nutzer wünscht man sich aber dann doch manchmal eine Kommandozeile, gerade wenn Tätigkeiten automatisiert werden sollen. Zum Glück gibt es mit WP-CLI („WordPress Commandline Interface“) eine Lösung. Und was WP-CLI kann, kann sich sehen lassen: WordPress installieren, Plugins aktualisieren, Datenbank-Dumps erstellen und wieder einlesen, Kommentare verwalten und noch vieles mehr.
Der Vorteil bei Nutzung von WP-CLI ist zudem, dass die WordPress-Dateien nicht vom Web-Server beschreibbar sein müssen. Gegenüber den automatisierten Updates, die WordPress mitbringt, ist dies ein klares Plus an Sicherheit, da kompromittierte Plugins dadurch keine weiteren Dateien ändern können.
[toc]
Voraussetzungen
Um WP-CLI nutzen zu können, musst du SSH-Zugriff auf Deinen Server haben. Ein billiger Shared Hosting tut es hier also nicht. Auch empfiehlt es sich, ein bisschen Erfahrung mit der Kommandozeile zu haben. Ich gehe daher im folgenden davon aus, dass du die Grundlagen einer Linux-Shell beherrschst.
WP-CLI installieren
Die Installation von WP-CLI ist relativ einfach. Dazu wechselst du zunächst in dein Home-Verzeichnis (wo man nach dem Einloggen wahrscheinlich schon ist). Dort lädst du dann WP-CLI mit folgendem Kommando herunter:
curl -O https://raw.githubusercontent.com/wp-cli/builds/gh-pages/phar/wp-cli.phar
Es empfiehlt sich, zu testen, ob alles funktioniert:
$ php wp-cli.phar --info PHP binary: /usr/bin/php5 PHP version: 5.6.17-0+deb8u1 php.ini used: /etc/php5/cli/php.ini ....
Gibt es dies oder ähnliches aus, dann funktioniert alles. Du kannst die Datei dann in deinen Pfad verschieben und ausführbar machen. Als root kann man sie z.B. nach /usr/local/bin kopieren, hier verschiebe ich sie allerdings in mein lokales bin/-Verzeichnis:
chmod 755 wp-cli.phar mv wp-cli.phar ~/bin/wp
Nun heißt es also wp und kann entsprechend aufgerufen werden:
wp --info
Die Ausgabe hat sich hoffentlich nicht geändert.
So rufst du WP-CLI auf
Der Aufruf ist ja oben schon zu sehen, nur wird hinter wp dann noch ein Kommando und ggf. ein Unterkommando angehangen. So kannst du z.B. mit
wp comment list
alle Kommentare in deinem Blog auflisten lassen. Voraussetzung ist allerdings, dass du dieses Kommando innerhalb deiner WordPress-Instanz aufrufst (also dort, wo wp-login.php liegt oder tiefer im Verzeichnisbaum). Ansonsten kann ja WP-CLI schlecht wissen, auf welcher WordPress-Instanz es arbeiten soll.
Alternativ kannst du auch den Pfad zur WordPress-Instanz angeben:
wp --path=/var/www/example.org/htdocs/ comment list
Hier gehe ich davon aus, dass dein WordPress unter /var/www/example.org/htdocs/ liegt.
Multisite
Wenn du eine Multisite-Installation hast, wirst Du merken, dass du z.B. bei wp comment list nur die Kommentare des ersten Blogs angezeigt bekommst. Hier weiß WP-CLI nicht, welches Blog gemeint ist, da ja beide dieselbe WordPress-Installation und Datenbank besitzen.
Um eine bestimmte Site einer Multisite zu selektieren, musst du daher noch den --url-Parameter benutzen:
wp comment list --url=http://site2.example.org
Damit werden dann die Kommentare von site2.example.org aufgelistet. Dies gilt entsprechend für alle anderen Kommandos.
Die eingebaute Hilfe
WP-CLI hat eine ganze Menge von Kommandos und Unterkommandos. Hinzu kommen individuell noch diverse Parameter. Damit man sich das nicht alles merken oder dauernd nachschlagen muss, gibt es eine eingebaute Hilfe. Diese erreichst du, indem Du einfach
wp help
eingibst. Dies listet alle Kommandos und globale Parameter auf. Mit einem wp help <kommando> wird dann die Hilfe und die Unterkommandos zum entsprechenden Kommando ausgegeben und mit wp help <kommando> <unterkommando> dann die Beschreibung des Unterkommandos.
WP-CLI aktualisieren
Um WP-CLI zu aktualisieren, kannst du WP-CLI selbst nutzen, indem du
wp cli update
aufrufst. Stelle aber sicher, dass du das wp-Kommando auch schreiben kannst. Wenn du es global als root installiert hast, musst du wp cli update auch als root aufrufen, dann allerdings noch den Parameter --allow-root anhängen. Generell weigert sich WP-CLI nämlich, als root zu laufen.
Um herauszufinden, welche Version du installiert hast, kannst du wp cli version aufrufen. Um zu prüfen, ob ein Update bereitsteht, nutzt du wp cli check-update.
WordPress installieren
Um WordPress zu installieren, brauchst du
- eine schon eingerichtete Datenbank (also Datenbankname, Benutzername und Passwort)
- einen eingerichteten Web-Server, der auf das Verzeichnis zeigt, wo du WordPress installieren willst
Wechsel dazu in das Verzeichnis, wo WordPress installiert werden soll. WordPress kann dann in 3 einfachen Schritten installiert werden (auch einfach zu automatisieren):
1. WordPress herunterladen
Rufe folgenden Befehl auf, um WordPress herunterzuladen:
wp core download
Dies lädt die aktuellste Version von WordPress herunter. Willst Du eine andere Version herunterladen, kannst Du optional noch ein --version=<version> anhängen. <version> ersetzt du dabei durch die gewünschte Version, also z.B. wp core download --version=3.9.1.
Das lädt allerdings die englische Version von WordPress herunter. Willst du stattdessen die deutsche Version nutzen, muss noch der --locale-Parameter angehangen werden:
wp core download --locale=de_DE
Oder im Falle der Sie-Version:
wp core download --locale=de_DE_formal
2. WordPress konfigurieren
Als nächstes muss WordPress konfiguriert werden, also die wp-config.php geschrieben werden. Dazu gibt es den Befehl wp core config.
Diesen rufst du in der Basis-Version wie folgt auf:
wp core config --dbname=wp_database --dbuser=wp --dbpass=securepswd Dies konfiguriert die Datenbank mit den angegebenen Werten (die du natürlich ersetzen solltest). Zudem werden automatisch die Salts generiert. Auch wird geprüft, ob die Datenbank mit den angegeben Daten ansprechbar ist.
Ich persönlich würde die weitere Konfiguration mit einem Texteditor vornehmen. Manchmal ist es aber hilfreich, dies auch über ein Kommando erledigen zu können (Stichwort wieder Automatisierung). Dazu kann man weitere Konfigurationsdirektiven über das Flag --extra-php übergeben:
wp core config --dbname=testing --dbuser=wp --dbpass=securepswd --dbprefix=myprefix_ --extra-php <<PHP define( 'WP_DEBUG', true ); PHP
In diesem Fall setze ich zusätzlich zum Debug-Modus auch noch den Tabellenprefix (immer eine total gute Idee).
3. WordPress-Installation abschliessen
Jetzt haben wir also die Dateien am richtigen Ort und die Konfigurationsdatei geschrieben. Wir könnten jetzt schon auf per Web-Browser auf die Instanz zugreifen und den Installations-Wizard durchlaufen. Müssen wir aber nicht, denn wir können auch dies über die Kommandozeile erledigen:
wp core install --url=example.org \
--title="Titel der Website" \
--admin_user=dont_call_me_admin \
--admin_password=sicheres_passwort_0815_4711 \
--admin_email=my_email@example.org
Ich denke mal, das die Parameter hier selbsterklärend sind. Wer im übrigen keine Benachrichtigungs-E-Mail erhalten will, kann diese mit --skip-email unterdrücken.
Und damit haben wir eine voll funktionsfähige WordPress-Instanz aufgesetzt. Bislang natürlich ohne spezielles Theme und Plugins. Das kommt daher gleich dran. Vorher noch ein Wort in Sachen Sicherheit.
WordPress aktualisieren
Jeder weiß hoffentlich, wie wichtig es ist, WordPress auf dem aktuellsten Stand zu halten. Dankenswerterweise hilft auch hier WP-CLI. Um WordPress zu aktualisieren, ruft du folgenden Befehl auf:
wp core update
Dies lädt die aktuellste Version herunter und installiert diese. Dies installiert sowohl Unterversionen als auch Hauptversionen. Letztere allerdings will man ggf. vorher testen. Von daher empfiehlt es sich bei einer Automatisierung (z.B. via Cronjob), die Aktualisierungen auf Unterversionen einzuschränken. Dies geht mit
wp core update --minor
Manchmal will man außerdem eine spezielle Version installieren. Dies kannst du mit
wp core update --version=4.4.2
tun. Wenn die Versionsnummer kleiner als die installierte Version ist, musst du zudem --force benutzen, da WP-CLI dich das sonst nicht tun lässt.
Du kannst auch den Namen eines ZIP-Files angeben, wenn Du WordPress schon heruntergeladen hast:
wp core udpate latest.zip
Eventuell muss dann noch die Datenbank aktualisiert werden. Dies kannst du mit folgendem Befehl tun:
wp core update-db
Plugins mit WP-CLI verwalten
Nun also zu den Plugins. Hier kann man mit WP-CLI die komplette Verwaltung vornehmen, also Installation, Aktualisierung, Aktivierung usw. Das ist auch ungemein hilfreich, wenn man nicht mehr ins Web-Backend reinkommt.
Plugins installieren, aktivieren und löschen
Der erste Schritt ist wohl die Installation von Plugins. So kannst du mit dem Befehl
wp plugin install w3-total-cache
das Plugin W3 Total Cache installieren. Als nächstes kannst du es mit
wp plugin activate w3-total-cache
aktivieren. Oder aber du tust dies in einem Schritt mit
wp plugin install --activate w3-total-cache
Deaktivieren geht entsprechend mit deactivate. Es gibt auch noch toggle, welche diesen Status immer umschaltet, ich finde aber eine explizite Angabe meist sinnvoller.
Bleibt die Frage, welchen Namen man denn beim Plugin angeben muss. Und zwar ist dies der sogenannte slug (hier w3-total-cache). Dies ist der Teil der URL der Plugin-Seite des WordPress-Plugin-Verzeichnisses:
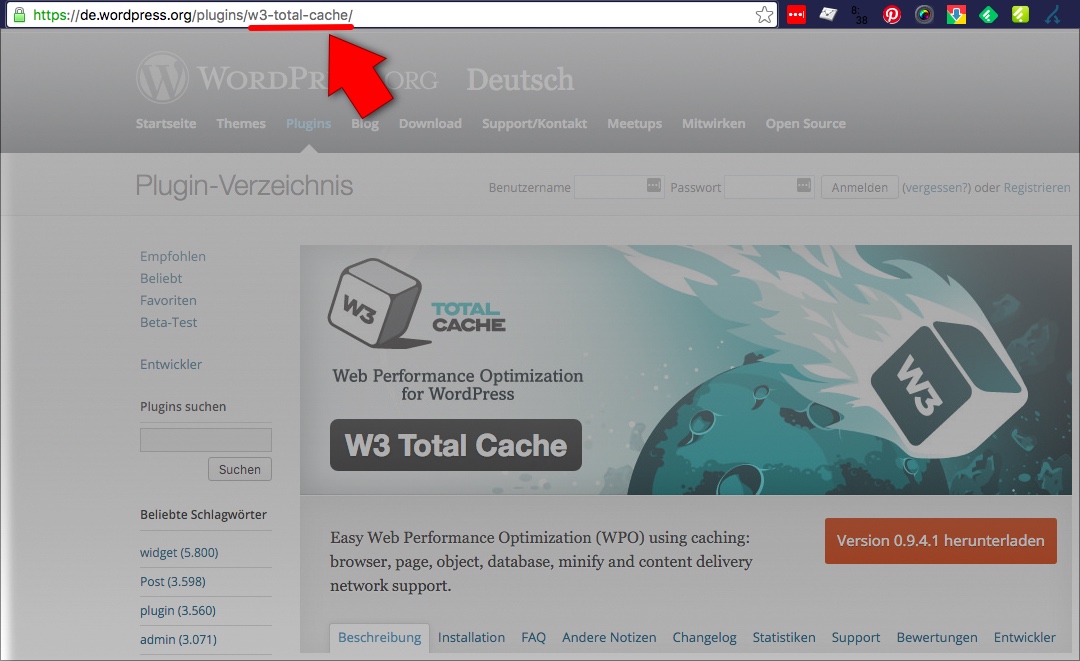
Wie man den Plugin-Slug für WP-CLI findet
Du kannst auch Plugins installieren, die nicht im WordPress-Verzeichnis vorhanden sind (z.B. kommerzielle Plugins). Dazu ersetzt du den Plugin-Slug einfach durch den Namen oder die URL eines ZIP-Files:
wp plugin install my-super-commercial-plugin.zip
wp plugin install https://example.org/plugins/my-super-commercial-plugin.zip
Plugins löschen
Löschen kannst du ein Plugin natürlich auch wieder. Das machst du wie folgt:
wp plugin deactivate w3-total-cache wp plugin uninstall w3-total-cache
Man kann auch das wieder zusammenfassen:
wp plugin uninstall --deactivate w3-total-cache
Alle Plugins deaktivieren
Wenn mal nichts mehr geht, ist eine der Ratschläge, einfach mal alle Plugins zu deaktivieren. Das ist natürlich schwerlich im Web-Interface zu erledigen, wenn nichts mehr geht. Wer WP-CLI hat, ist da klar im Vorteil, denn hier geht es einfach mit
wp plugin deactivate --all
Wie man alle Plugins wieder aktiviert, wird dem Leser als Hausaufgabe überlassen.
Plugins suchen
Nach Plugins suchen kannst du ebenfalls (z.B. um den Slug herauszufinden). Willst du z.B. ein SEO-Plugin installieren, kann der folgende Befehl helfen, das richtige (oder zumindest irgendeins) zu finden:
$ wp plugin search seo Success: Showing 10 of 1843 plugins. +-------------------------------+-------------------+--------+ | name | slug | rating | +-------------------------------+-------------------+--------+ | SEO | seo-wizard | 76 | | SEO Ultimate | seo-ultimate | 78 | | WordPress SEO Comments Plugin | blog-comments-seo | 88 | | Link to us - SEO Widget | link-to-us | 100 | | SEO by SQUIRRLY™ | squirrly-seo | 90 | | WP Meta SEO | wp-meta-seo | 90 | | SEO Post Content Links | content-links | 98 | | SEO Plugin LiveOptim | liveoptim | 88 | | Yoast SEO | wordpress-seo | 80 | | The SEO Framework | autodescription | 100 | +-------------------------------+-------------------+--------+
Um die nächsten 10 Einträge einzusehen, kannst du die Option –page=2 nutzen. Du kannst die Anzahl der Ergebnisse pro Seite mit Hilfe von --per-page=50 ändern.
Weiterhin kannst du die angezeigten Felder mit Hilfe des --fields-Parameters bestimmen. Gebe wp help plugin search ein, um eine komplette Liste der Felder zu erhalten.
Wenn du dieses Kommando in einem Script verwendest, willst du vielleicht auch ein anderes Ausgabeformat wählen. Dies kannst du mit --format tun, wobei man zwischen table, csv, json, count und yaml wählen kann. Sortieren (z.B. nach Rating) geht aber leider nicht.
Hier ein weiteres Beispiel:
$ wp plugin search seo --format=csv --per-page=2 --fields=name,slug,tested Success: Showing 2 of 1843 plugins. name,slug,tested SEO,seo-wizard,4.5.1 "SEO Ultimate",seo-ultimate,4.3.3
Beachte, dass hier noch eine Zeile mit Success angezeigt wird, was bei der Nutzung in einem Script vielleicht stören könnte. Willst du solche Meldungen unterbinden, musst du noch --quiet als Parameter anhängen. Gerade in Scripts macht diese Funktion wohl auch am ehesten noch Sinn, denn ansonsten sind Plugins wohl einfacher über das Web zu finden.
Plugins auflisten
Um herauszufinden, welche Plugins überhaupt installiert sind, kannst Du wp plugin list aufrufen:
$ wp plugin list +-------------------------------------+----------+-----------+----------+ | name | status | update | version | +-------------------------------------+----------+-----------+----------+ | above-the-fold-optimization | inactive | none | 2.3.14 | | advanced-custom-fields | active | none | 4.4.7 | | amp | active | none | 0.3.2 | | antispam-bee | active | none | 2.6.8 | ...
Plugins aktualisieren
Eine sehr hilfreiche Funktion von WP-CLI ist es, Plugins per Script aktualisieren zu können. Dies hat den Vorteil, dass die WordPress-Dateien einen anderen Besitzer als den Web-Server haben können. Somit kann ein Angreifer diese auch nicht ändern. wenn er „nur“ Zugriff auf das Web-Interface hat.
Zunächst aber will man wahrscheinlich den Status seiner Plugins erfahren. Dazu rufst du folgendes auf:
$ wp plugin status 5 installed plugins: I above-the-fold-optimization 2.3.14 A advanced-custom-fields 4.4.7 A amp 0.3.2 A antispam-bee 2.6.8 UA fb-instant-articles 2.9 ...
Anhand der ersten Spalte siehst du dann, dass above-the-fold-optimization nur installiert, aber nicht aktiviert ist, die drei nächsten auch aktiviert sind und fb-instant-articles ein Update braucht.
Dieses kannst du dann mit
wp plugin update fb-instant-articles
installieren. Willst du auf eine spezifische Version aktulisieren, kannst du das mit --version=1.2.3 tun.
Du kannst auch alle zu aktualisierenden Plugins auf einmal aktualisieren:
wp plugin update --all
Themes verwalten
Wenn alle Plugins bereit sind, braucht es noch ein Theme. Ich gehe hier zunächst davon aus, dass ein bestehendes Theme installiert werden soll. Dies funktioniert ähnlich wie bei Plugins.
Theme installieren
So installierst Du ein Theme mit
wp theme install <theme>
<theme> kann dabei sein:
- ein Theme-Slug im WordPress-Theme-Verzeichnis (z.B.
clean-journal) - der Name/Pfad eines ZIP-File
- die URL eines ZIP-Files
Du kannst das Theme dabei direkt mit --activate aktivieren oder das separat tun:
wp theme activate clean-journal
Themes aktualisieren, suchen, auflisten
Ähnlich wie bei Plugins kannst Du auch Themes aktualisieren. Dies geschieht mit
wp theme update <theme>
wobei man auch hier --all und --version wie bei den Plugins angeben kann.
Dasselbe gilt für die Kommandos list und status. Auch die entsprechen den oben beschriebenen Plugin-Kommandos.
Permalinks konfigurieren
Die Permalinks können ebenfalls mit WP-CLI verwaltet werden. Dies geht mit dem wp rewrite-Kommando. Will man die Permalink-Struktur auf /2016/04/postname ändern, so geht dies mit
wp rewrite structure '/%year%/%monthnum%/%postname%'Dabei kannst Du auch die Kategorie- und Schlagwort-Basis setzen (wie in den Permalink-Einstellungen):
wp rewrite structure --category_base '/kat/' --tag-base '/stichwort/' '/%year%/%monthnum%/%postname%'
Die Rewrite-Rules können dann mit wp rewrite flush aktualisiert oder mit wp rewrite list aufgelistet werden.
Benutzer verwalten
Kommen wir zur Benutzerverwaltung. Will man einen neuen Autor mit Benutzername klaus und E-Mail-Adresse klaus@comlounge.net anlegen, so ruft man Folgendes auf:
wp user create klaus klaus@comlounge.net --role=authorGibt man keine Rolle an, wird die Default-Rolle genutzt (normalerweise wohl subscriber). Weitere Parameter sind:
--user_pass=<pass>übergibt ein Passwort für den neuen Nutzer--display_name=<anzeigename>definiert den Anzeigenamen--first_name=<vorname>speichert den Vornamen--last_name=<nachname>entsprechend den Nachnamen--send_emailgibt an, ob eine Mail an den neuen Benutzer gesendet werden soll oder nicht--porcelaingibt nur die Benutzer-ID zurück, sinnvoll bei einer Automatisierung
Benutzer wieder löschen geht mit
wp user delete klaus
Will man dabei die Artikel des Benutzers an einen anderen Benutzer „übergeben“, so geht dies mit --reassign=<user_id>.
Dazu braucht man natürlich die ID, die man mit Hilfe der Benutzerliste herausbekommt:
wp user list
Auch hier gibt es wieder viele hilfreiche Parameter, wie z.B.
--role=<rolle>zeigt nur die Benutzer mit der angegebenen Rolle an--format=<format>definiert das Ausgabeformat (table,csv,json,count,yaml)
Datenbank verwalten
Wenn es um die Datenbank geht, ist ja zunächst mal ein Export (z.B. für ein Backup interessant). Das geht mit
wp db export
Praktischerweise muss man hier keinen Benutzernamen und Passwort angeben, da dies ja schon in der wp-config.php konfiguriert ist. Nach Ausführung des Kommandos liegt eine SQL-Datei mit dem Namen <dbname>.sql im aktuellen Verzeichnis. Willst du sie an einen anderen Ort exportieren, kannst du den Pfad dorthin angeben:
wp db export /tmp/export.sql
Das Importieren der Datenbank ist dann ebenfalls recht einfach möglich:
wp db import /tmp/import.sql
Praktisch ist manchmal auch, einfach einen Datenbank-Prompt zu haben. Dies geht ganz einfach mit
wp db cli
Weitere Kommandos können die Datenbank optimieren, reparieren usw. Weiteres findest du mit Hilfe von wp help db heraus.
Kommentarverwaltung mit WP-CLI
Spätestens, wenn sich Tausende bis Milliarden von Spam-Kommentaren angesammelt haben, wünscht man sich einen Weg, diese relativ flott löschen zu können. Das Web-Backend ist dabei nur leider alles andere als flott und kann das Lösch-Glück ggf. mit einem Timeout ins Gehege kommen. Abhilfe schafft auch hier wieder WP-CLI:
wp comment delete $(wp comment list --status=spam --format=ids)Hier arbeiten sogar 2 Kommandos zusammen: Mit wp comment list werden alle Kommentare angezeigt, die den Status spam haben. Der Parameter --format=ids definiert, dass nur die IDs ausgegeben werden. Diese werden dann von wp comment delete als Eingabe genutzt.
Für die normale Kommentar-Moderation ist die Kommandozeile wahrscheinlich eher schlecht geeignet, für Batch-Operationen wie oben bietet sie sich aber definitiv an. Gerade wegen der Timeouts.
Suchen und Ersetzen
Wer schon einmal eine WordPress-Instanz umziehen musste, wird sich darüber gefreut haben, dass das Meiste an Konfiguration in der Datenbank und nicht etwa in Konfigurationsdateien abgelegt wird. Will man also die URL der Site ändern, ist das nicht so einfach möglich und mit vielen Plugins dennoch oftmals manuelle Arbeit.
Einfacher ist da mal wieder die Kommandozeile. Bei WP-CLI gibt es daher das passende Kommando:
wp search-replace live.example.org dev.example.orgIn diesem Beispiel werden alle Vorkommen von live.example.org durch dev.example.org ersetzt. WP-CLI handhabt dabei ebenfalls von PHP serialisierte Daten.
Wer dem Suchen und Ersetzen erstmal nicht so traut, der kann sich mit Hilfe von --dry-run ausgeben lassen, wie viele Vorkommnisse in welcher Tabelle denn geändert werden würden:
$ wp search-replace live.example.org dev.example.org +------------------+-----------------------+--------------+------+ | Table | Column | Replacements | Type | +------------------+-----------------------+--------------+------+ | wp_options | option_name | 1 | SQL | | wp_options | option_value | 15 | PHP | | wp_users | user_email | 4 | SQL | +------------------+-----------------------+--------------+------+
In dieser Ausgabe sieht man jetzt z.B., dass der Such-String auch in E-Mail-Adressen vorkommt. Diese will man wahrscheinlich nicht ändern und zum Glück kann man das search-replace dabei auf bestimmte Tabellen (wie wp_options) einschränken. Dazu gibt man einfach die gewünschten Tabellen noch am Ende an:
wp search-replace live.example.org dev.example.org wp_options wp_irgendwas ...
Allerdings muss man sich dazu schon ein bisschen auskennen oder sollte zumindest noch einmal sicherstellen, dass man ein Backup hat (das macht ihr doch eh immer, oder?). Ansonsten ist ein wp db export ja schnell gemacht.
Multisite
Bei einer Multisite ist natürlich noch mehr zu beachten, z.B. dass man das Suchen und Ersetzen auf den richtigen Sites durchführt. WP-CLI arbeitet daher zunächst auf der Standard-Site oder der durch den --url-Parameter angegeben Site. Mit Hilfe von --network kannst du das Suchen und Ersetzen aber auf allen Sites gleichzeitig durchführen.
Plugins und Erweiterungen für WP-CLI
WP-CLI beinhaltet schon recht viele Kommandos. Mehr ist aber immer besser und daher kann WP-CLI mit Hilfe von Plugins erweitert werden. Mehr noch: Manche Plugins, wie W3 Total Cache haben schon Support für WP-CLI eingebaut. Hast du also W3 Total Cache und WP-CLI installiert, kannst Du mit
wp total-cache flushden Cache von der Kommandozeile aus leeren. Die Liste aller Kommandos erhält man dabei wie beschrieben mit wp help.
Wenn du wissen willst, welche andere Plugins WP-CLI-Unterstützung haben oder welche gar nur neue Befehle bereitstellen, dann kannst du das im Tool-Verzeichnis nachsehen.
Packages
Es gibt aber nicht nur Plugins, sondern auch noch sogenannte Packages. Diese sind im Gegensatz zu Plugins nur in WP-CLI aktiv. Sie werden daher vom Web-Frontend gar nicht erst geladen und sind auch nicht von WordPress selbst abhängig. D.h. sie können auch ausgeführt werden, wenn WordPress noch gar nicht aktiv oder defekt ist.
Eine Liste der verfügbaren Packages gibt es im Package-Index oder über die Kommandozeile selbst:
wp package browse
Installiert wird ein Package wie folgt:
wp package <package_name>
Ein Beispiel wäre:
wp package install petenelson/wp-cli-size
Danach gibt es dann ein neues Kommando namens wp size:
wp size database
Artikel-Revisionen verwalten
Ähnlich wie zu viele Spam-Kommentare in der Datenbank können auch zu viele Artikel-Revisionen WordPress ausbremsen. Doch wie löscht man die nicht mehr benötigten Revisionen alle auf einmal? Hier kommt das Plugin wp-revisions-cli zum Einsatz. Ein Problem nur: Es existiert nur als Source-Code-Repository auf github und nicht im WordPress-Plugin-Verzeichnis.
Was also tun?
Wie oben beschrieben, kann man Plugins auch aus einem ZIP-File installieren. Weiterhin muss diese Datei gar nicht lokal vorliegen, sondern kann auch per URL referenziert werden. Die URL bekommt man dabei von github, denn dort wird das Repository auch als ZIP-Datei bereitgestellt:
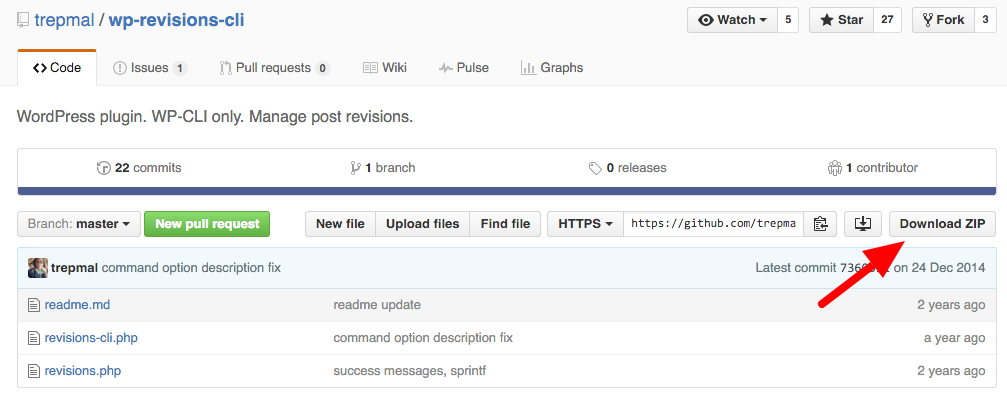
Download-Link zum WP-Revisions-Plugin
Mit einem Rechtsklick kann man dann die URL des Links kopieren und dann das Plugin damit installieren:
wp plugin install --activate https://github.com/trepmal/wp-revisions-cli/archive/master.zipDies installiert und aktiviert das Revisions-Plugin. In WordPress selbst sieht man außer dem Plugin in der Plugin-Liste nichts davon, denn es stellt nur ein WP-CLI-Kommando bereit.
Nun, da das Plugin installiert ist, kann du mit wp help revisions die vom Plugin bereitgestellten Unterkommandos ansehen.
Revisionen ansehen
Alle gespeicherten Revisionen kannst du mit
wp revisions list
auflisten lassen. Das sind wahrscheinlich recht viele, so du die maximale Anzahl von anzulegenden Revisionen nicht in wp-config.php eingeschränkt hast (das kannst du z.B. mit wp revisions status prüfen). Mit Hilfe von --post_id= und --post_type= kannst du die Liste aber entsprechend auf einen Artikel oder einen Artikeltyp einschränken.
Revisionen löschen
Eigentlich wollten wir Revisionen aber ja löschen. Hier gibt es gleich zwei Kommandos: clean und dump.
Der Unterschied zwischen den Kommandos ist, dass dump einfach alle Revisionen komplett löscht, während man bei clean mehr Kontrolle hat. Mit wp revisions dump sind also einfach alle Revisionen weg.
Will man aber noch 5 Revisionen behalten und nur alle älteren löschen, dann kann man das mit
wp revisions clean 5
tun. Optional kann man auch wieder die oben schon beschriebenen Parameter --post_id und --post_type angeben, um nur einen Artikel oder einen Artikel-Typ zu behandeln.
Es gibt noch viel mehr…
Obwohl der Artikel schon recht lang ist, gibt es in WP-CLI natürlich noch viel mehr. Ich werde den Artikel also ggf. noch erweitern. Wer selbst noch ein bisschen stöbern will, kann dies aber natürlich mit wp help tun.
Und wenn ihr WP-CLI schon nutzt, wäre ich an interessanten Anwendungsfällen in den Kommentaren sehr interessiert.
Wer kennt das nicht? Man schreibt einen tollen Beitrag und was fehlt? Genau: Ein Titelbild. Wenn man dann nicht selbst zum Fotoapparat greifen will (wie ich das hier oft tue), stellt sich die Frage: Wie findet man passende Bilder und wie baut man diese rechtssicher in sein Blog oder seine Website ein? Und da ich gerade auf der re:publica war und dort vom Lizenzhinweis-Generator gehört habe, schien es mir sinnvoll, auf das Thema Bilder und Internet noch einmal einzugehen.
Wo finde ich Bilder?
Zunächst also die Frage: Wo finde ich Bilder? Und wie jeder weiß, lautet die Antwort: Im Internet.
Dass bei der Nutzung von Bildern aus dem Netz allerlei rechtliche Gefahren drohen, wissen dabei sicherlich auch schon viele Leute. Bekannt dürfte auch sein, dass man in solchen Fällen nach Bildern mit einer Creative Commons (CC)-Lizenz Ausschau halten sollte. Denn Bilder mit CC-Lizenz dürfen unter bestimmten Bedingungen frei verwendet werden. Eine der Quellen, wo es viele solcher CC-lizensierten Bilder gibt, ist Wikimedia Commons.
Primär dient Wikimedia Commons als Mediendatenbank für Wikipedia und angeschlossene Projekte. Da die Mediendateien dort aber nicht speziell für Wikimedia lizensiert sind, sondern eben als Creative Commons, können sie natürlich auch woanders eingebunden werden. Und mit über 31 Mio. Mediendateien ist die Auswahl nicht gerade klein.
Einzig das Finden kann ein Problem sein. Eine Möglichkeit ist, zunächst die Medienart zu wählen, und dann die entsprechende Kategorie:

Wikimedia Commons: Erst Medienart wählen
Wikimedia Commons: Dann Kategorie wählen
Wie man aber sieht, ist dies nicht die zeitgemäßeste Art, Bilder zu suchen. Moderner wäre hier ein visuelles Tool. Zum Glück gibt es das auch und es nennt sich Google.
Bezogen auf Wikimedia Commons geht das so: Will ich dort nach Robotern suchen, dann gehe ich zunächst zur Google Bilder-Suche (kommt jetzt etwas überraschend, ich weiß). Dann gebe ich zur Suche nach „robot“ Folgendes ein:
site:commons.wikimedia.org robot
site: ist dabei das Zauberwort, denn dadurch wird Google angewiesen, nur solche Ergebnisse auszugeben, die auf der Website mit dieser Domain vorkommen. Und so finden wir also schließlich viele, viele Roboter.
Wie baue ich Bilder rechtssicher ein?
Wer jetzt meint: „Super, bau ich das Bild mal einfach ein, ist ja CC-lizensiert!“ der wird sich ggf. später über eine Abmahnung freuen. Denn Bild einbauen ist nicht gleich Bild einbauen.
Wie Henning Krieg und Thorsten Feldmann in ihrem Jahresrückblick Social Media Recht 2016 auf der re:publica berichteten, soll es wohl auch Fotografen geben, die ihre Bilder auf Wikimedia Commons hochladen und es darauf anlegen, dass ein Bild falsch eingebaut wird, um diese Personen dann abzumahnen. Uncool, aber zumindest in Deutschland erlaubt.
Lizenz beachten
Damit das nicht passiert, muss man die Lizenz beachten. Das beginnt damit, dass es überhaupt die richtige Lizenz für die eigene Website ist. Bei Creative Commons kann man als Urheber nämlich seine eigene Lizenz aus einem Baukasten zusammenbauen. Und dabei kann man auch entscheiden, ob das Werk auch kommerziell oder nur nicht-kommerziell genutzt werden. Auch kann man angeben, ob es verändert werden darf.
Hast du also eine kommerzielle Website, darfst du schon keine Bilder verwenden, die nur für die nicht-kommerzielle Nutzung freigegeben sind. Willst du ein Bild in eine Collage einbauen, dann solltest du darauf achten, dass man es auch verändern darf. All dies steht in den Lizenzvereinbarungen und die Creative-Commons-Website hilft zudem dabei, die CC-Icons zu identifizieren.
Bei Wikimedia Commons scheint es nur Werke zu geben, die relativ frei sind, also auch kommerziell genutzt werden dürfen. Dennoch sollte man auf Nummer sicher gehen. Das gilt erst recht, wenn man Bilder aus anderen Quellen nutzen will. Auch hierbei kann Google wieder helfen, denn man kann Google anweisen, die Suche auf eine bestimmte Lizenz zu begrenzen.
Klickt man nämlich auf „Suchoptionen“, erscheinen weitere Sucheinschränkungen und man kann hier die gewünschten Nutzungsrechte selektieren:

Google: Nutzungsrechte selektieren
Natürlich sollte man bei einem Bild danach immer noch sicher gehen, dass es auch wirklich unter der gewünschten Lizenz veröffentlicht wurde, denn Google kann sich ja auch mal vertun.
(Im Übrigen sind auch die anderen Suchoptionen hilfreich. So hilft die Auswahl von „transparent“ unter „Farbe“ z.B. dabei, Logos mit einem transparenten Hintergrund zu finden)
Lizenzhinweis richtig einbauen
Wenn du das richtige Bild mit der richtigen Lizenz gefunden hast, bleibt noch der richtige Einbau des Lizenzhinweises. Wie oben schon erwähnt, kann man sonst abgemahnt werden (wie z.B. dieser Fall zeigt). Doch wie genau der Lizenzhinweis aussehen muss, ist vielleicht nicht immer ganz klar.
Für Wikimedia Commons kann da der auch auf der re:publica vorgestellte Lizenzhinweis-Generator helfen. Dieser funktioniert wie folgt:
- Man ruft lizenzhinweisgenerator.de auf
- Man gibt die URL einer Mediendatei auf Wikimedia Commons oder eines Wikipedia-Artikels ein
- Ist es ein Wikipedia-Artikel, zeigt der Generator alle dort verwendeten Bilder an und man selektiert das gewünschte Bild.
- Man selektiert eine Nutzungsart (Online oder Print)
- Man selektiert, ob es in einer Collage/Galerie/etc. oder einzeln verwendet werden soll
- Man gibt an, ob man es noch verändern will
Am Ende erscheint dann der fertige Lizenzhinweis in verschiedenen Formaten. Baut man diesen entsprechend ein, sollte man dann vor Abmahnungen gefeit sein.
So sieht das am Ende dann aus:
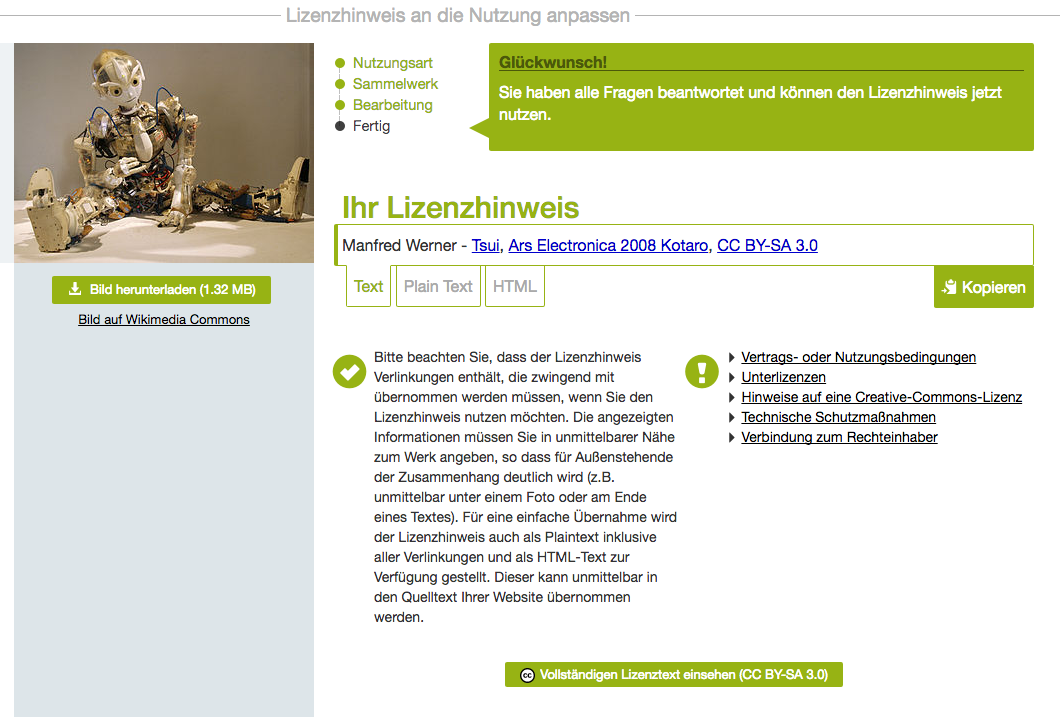
Wikimedia Commons: Nutzungsrechte für ein Roboter-Bild.
(Manfred Werner – Tsui (https://commons.wikimedia.org/wiki/File:Ars_Electronica_2008_Kotaro.jpg), „Ars Electronica 2008 Kotaro“, https://creativecommons.org/licenses/by-sa/3.0/legalcode)
Und dies ist der dafür notwendige Lizenzhinweis (der hiermit dann auch eingebaut wäre):
Fazit
Wie man sieht, ist es gar nicht so schwer, interessante Bilder für sein Blog oder seine Website zu finden. Und wenn man dennoch kein passendes Bild findet, helfen verwandte Bilder vielleicht dabei, mit etwas Kreativität doch noch ein passendes Titelbild selbst zu erstellen. Dies muss man bei abstrakteren Themen ja eh tun (z.B. beim Thema Verkehrswege-Planungsbeschleunigungsgesetz).
Und dank des Lizenzhinweis-Generators ist auch die rechtssichere Einbindung dann hoffentlich kein Problem mehr.
Bildnachweis Titelbild:
Rama; edited by user Jaybear, Leica-II-Camera-1932 cropped, Komposition von Christian Scholz, CC BY-SA 3.0
Wie letztens berichtet, hat Facebook auf der diesjährigen f8-Entwicklerkonferenz ein neues Feature präsentiert: Facebook Messenger-Bots. Zeit also, sich einmal anzuschauen, was man mit diesen Chat-Bots so machen kann. In diesem Tutorial beschreibe ich daher zunächst das Setup und anschließend eine Beispiel-Implementierung eines einfachen Bots mit Hilfe von Flask und Python. Dies in einer anderen Sprache zu implementieren sollte dabei aber kaum komplizierter sein. Alles, was du können musst, ist, einen Web-Server aufzusetzen, JSON zu verarbeiten und HTTP-Requests abzusenden. Die Facebook-Dokumentation findest du ansonsten hier.
[toc]
Was du für einen Facebook Messenger-Bot brauchst
Um einen Facebook Messenger-Bot zu implementieren brauchst du nicht viel. Hauptsächlich benötigst du einen Web-Server mit SSL-Unterstützung, auf dem der Bot dann laufen soll. Weiterhin bedarf es einer Facebook-Seite und einer Facebook-App. Es können dazu auch bestehende Seiten und Apps genutzt werden. Beides muss nicht zwangsläufig veröffentlicht sein, um den Bot damit betreiben zu können.
Die Seite dient dabei als Ankerpunkt des Bots, denn auf Facebook sendet man Nachrichten ja entweder an Personen oder an Seiten. Die App dient dazu, die notwendige Infrastruktur (wie den Webhook) bereitzustellen. Damit kann dann ein Mensch über die Seite mit deiner App und damit deinem Server kommunizieren.
Für dieses Tutorial benötigst du außerdem noch Python 3, flask und die requests-Library. Python-Kenntnisse sind sicherlich auch hilfreich. Wie oben schon gesagt, sollten die Konzept aber recht einfach auf andere Sprachen zu übertragen sein.
Python aufsetzen
Zunächst setzen wir die Server-Seite auf. Ich gehe davon aus, dass Python 3 installiert ist. Python 2.7 tut es sicherlich auch, nur die Syntax ist dann leicht anders. Zudem braucht man das venv-Paket. Wechsel dann in das Verzeichnis, in dem der Bot leben soll. Dort erstellst Du dann ein virtual environment und installierst die notwendigen Pakete:
pyvenv . source bin/activate pip install flask requests
Danach erstellst Du zum Testen eine einfache Flask-App mit dem Namen bot1.py. Diese dient zunächst nur zum Testen des Servers.
https://gist.github.com/mrtopf/e8604b71ac9e54370628eafa45f9b160
Danach kann man den Server mit python bot1.py starten.
Als nächstes musst du dann deinen Web-Server so konfigurieren, dass er diesen Python-Server unter einer öffentlichen URL bereitstellt. Wichtig ist dabei, dass er unter https, also verschlüsselt, erreichbar sein muss. Da dies hier ein bisschen zu weit führen würde, verweise ich dazu mal auf Google. (Dort findet man z.B. eine Anleitung für nginx mit uwsgi). Ich persönlich habe das einfach auf unserer Domain laufen lassen (denn die hat schon SSL) und unter nginx wie folgt konfiguriert:
location /testbot { proxy_pass http://127.0.0.1:8888; }
Wenn alles funktioniert hat, sollte der Server dann unter dem Pfad /testbot mit Hello, World! antworten.
Seite und App einrichten
Wenn du noch keine Seite hast, die du mit dem Bot assoziieren willst, musst du eine erstellen. Dies geht unter diesem Link. Der Typ dürfte egal sein, für meinen Test habe ich einfach Community genommen. Die Seite selbst muss dazu nicht veröffentlich werden, sie muss aber existieren.
Auch bei der App kann man entweder eine bestehende App nutzen oder eine neue erstellen. Dies geht mit Hilfe dieses Links. Ich habe dazu den Typ „Website“ gewählt und das sieht dann wie folgt aus:
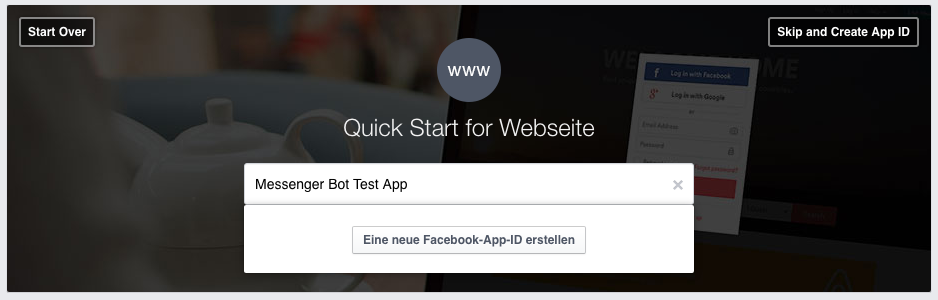
Facebook Messenger-Bot: App erstellen
Als nächstes musst du eine Kontakt-E-Mail-Adresse angeben und die Kategorie auf „Apps für Seiten“ stellen. Test-Version bleibt ausgeschaltet. Nach Absenden des Formulars bist du an sich fertig, du kannst dann auf „Skip Quickstart“ oben rechts klicken. Danach erscheint das App-Dashbord.
Seite und App für den Facebook Messenger-Bot verknüpfen
Im App-Dashboard gibt es jetzt einen neuen Menüpunkt „Messenger“. Klickt man auf diesen zum ersten Mal, erscheint eine Info-Box, die man bestätigen muss. Danach erscheint dann folgender Screen:
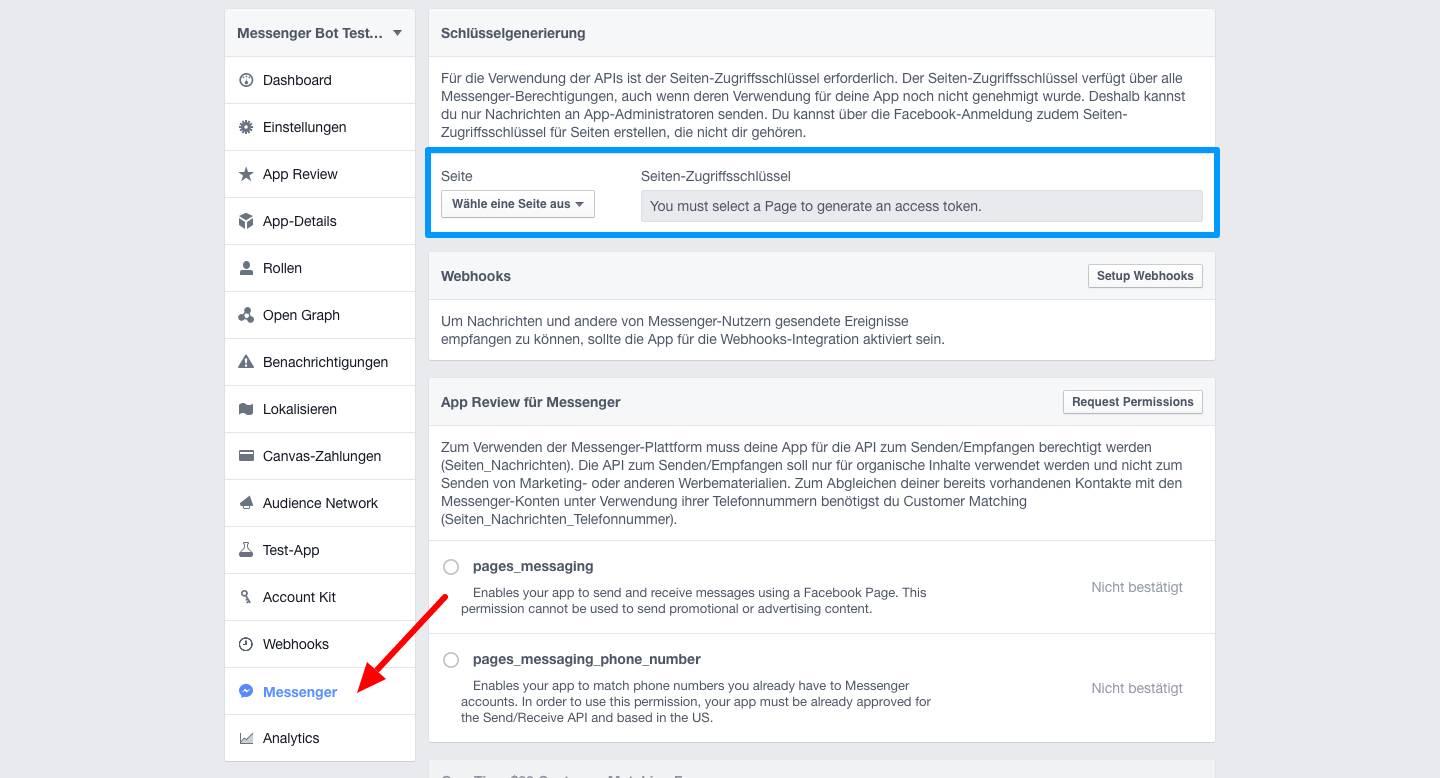
Facebook Messenger-Bot: Das App-Dashboard
Dort kannst du diese App mit der entsprechenden Seite verknüpfen. Wähle dazu in dem oberen Bereich (hier blau umrahmt) die zu verknüpfende Seite aus (ggf. gehen dabei ein paar Facebook-Popups auf, die nach weiteren Berechtigungen fragen). Ist dies geschehen, erscheint ein Access-Token neben der Seitenauswahl. Klicke darauf, um es zu kopieren. Beachte, dass dies dort nicht stehen bleibt. Wenn du es also erneut brauchst, musst du erneut die Seite auswählen und es erscheint wieder (bleibt wohl auch immer gleich).
Dieses Token wird dann im folgenden Aufruf genutzt, den du in einer Shell tätigen musst:
curl -ik -X POST "https://graph.facebook.com/v2.6/me/subscribed_apps?access_token=<token>"
Der Aufruf sollte ein {"success":true} zurückgeben.
Damit erhält dann die App Updates von der Seite (denn normalerweise empfängt ja eine Seite Chat-Nachrichten und keine App). Wenn Du das nicht tust, dann wird nie eine Nachricht an die Seite bei der App und damit bei deinem Bot/Server ankommen. Das Token ist zudem nur für genau diese App- und Seiten-Kombination gültig.
Webhooks einrichten
Damit nun die App auch Nachrichten empfängt, muss ein Webhook eingerichtet werden. Dies ist der Server-Endpunkt auf deiner Seite, wo Facebook dann die vom Benutzer empfangenen Nachrichten hinschickt.
Dazu kannst du folgendes flask-Programm nutzen, das du unter bot2.py speichern kannst.
https://gist.github.com/mrtopf/1e7f1500ae1277fd04ec8887a9bcba25
Wichtig dabei ist die Zeichenkette cd7czs87czds8chsiuh9eh3k3bcjhdbjhb. Diese kannst du selbst wählen und dient dazu, dass Facebook weiß, dass dieser Server und die App vom selben Autor kommen (also ein shared secret). Diese Zeichenkette muss sowohl in deinem Programm als auch im Webhook-Dialog eingetragen sein.
Sobald der Bot mit python bot2.py dann läuft, kannst du auf den Button „Webhooks“ im Messenger-Bereich der App klicken (nicht den Menüpunkt „Webhooks“).
Folgendes erscheint und hier trägst du dieselbe Zeichenkette wie im Script ein:
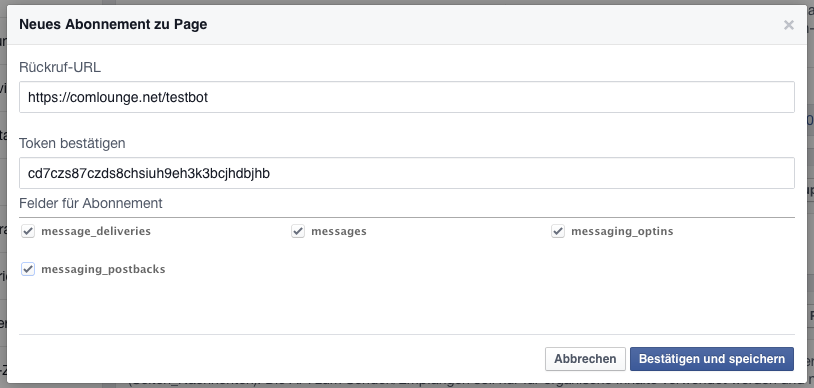
Setup der Facebook Messenger Webhooks
Am besten nutzt du natürlich ein eigenes Token. Die Berechtigungen klickst du am besten alle an.
Wenn alles funktioniert hat, sollte nach Absenden des Formulars ein „Abgeschlossen“ im Webhook-Bereich erscheinen.
Und damit haben wir jetzt die Seite und die App verknüpft sowie die App mit dem Server.
Nachrichten empfangen und senden
Das heißt, dass wir jetzt bereit sind, Nachrichten zu empfangen. Dazu braucht es natürlich noch etwas Code.
Regeln wir zunächst den Empfang. Sendet ein Benutzer nun etwas an den Bot (bzw. der Seiten-Administrator, solange der Bot noch nicht von Facebook freigeschaltet wurde), so kommt dies an dem Webhook an, der auch die Verifizierung geregelt hat. Es ist also dieselbe URL, nur ein POST- statt einem GET-Request.
Die Nachricht selbst ist JSON-kodiert und sieht bei einem „Hallo Bot!“ wie folgt aus:
https://gist.github.com/mrtopf/9c2220729a7b7cff683f290597470cff
Wichtig ist der messaging-Teil, der eine Liste von Nachrichten enthält. Diese wiederum enthalten eine Message-ID (mid), eine Sequenz-Nummer (mir ist nicht bekannt, ob die auch gemischt angekommen können), den Empfänger (die Seiten-ID) sowie den Sender als ID und einen Timestamp. Die Sender-ID ist dabei nicht die Facebook-ID des Benutzers, sondern eine eigene ID für diese Anwendung.
Mit bot3.py können wir dies nun lesen und mit einer einfachen Textnachricht antworten:
https://gist.github.com/mrtopf/91b2b3fbe970c7b4849fc77a8272a6d2
Wie man sieht, braucht man zum Senden ein Page-Token. Dies ist dasselbe Token, das man oben im curl-Befehl benutzt hat. Du findest es wie gehabt im Menüpunkt „Messenger“ im App-Dashboard ganz oben nach Auswahl der verknüpften Seite. Solange PAGE_TOKEN nicht das richtige Token enthält, wird der Bot nicht antworten.
Mit Hilfe dieses Tokens kann dann die Graph-API angesprochen werden. Der Bot sendet die Nachricht also nicht als Antwort direkt an den Webhook zurück, sondern asynchron. Dies hat den Vorteil, dass man auch später noch Nachrichten schicken kann, ohne dass der Benutzer erst wieder etwas sagen muss. Man sollte dabei nur die Facebook-Richtlinien und den gesunden Menschenverstand beachten. So dürfen z.B. keine reinen Werbenachrichten darüber versendet werden.
Das Format der Nachrichten werde ich ausführlicher in einem separaten Artikel beschreiben (zusammen mit den strukturierten Nachrichten). Im Prinzip sieht eine Text-Nachricht aber wie folgt aus:
https://gist.github.com/mrtopf/9db67af2036b9cee390df382011358c2
Die Recipient-ID ist dabei die Sender-ID aus der Anfrage.
Ein Bild senden
Ein Bild sagt mehr als 1000 Worte! Wie also sendet man ein Bild? Ironischerweise, indem man gefühlt 1000 Worte schreibt, denn der Code für ein Bild ist schon ein bisschen größer. Hier ist die Methode send_image():
https://gist.github.com/mrtopf/3b63c5eb1e43a518a5e21c9d683f352e
Diese kann man einfach in bot3.py einfügen und dann wie folgt aufrufen:
https://gist.github.com/mrtopf/936e0ddae9c4cf21b44cea60b9ad77e8
Hier wird also zusätzlich zum Text noch eine weitere Text-Nachricht und dann ein Bild gesendet. Das sieht im Messenger dann wie folgt aus:
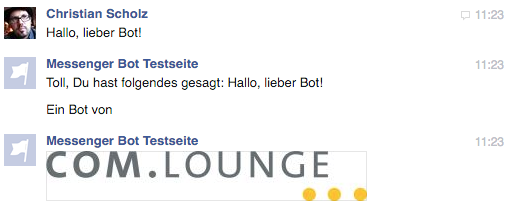
Messenger Bot Beispiel: Antwort mit Text und Bild
Die Struktur der Nachricht ist dabei so komplex, da es schon in Richtung strukturierter Nachrichten geht. Da dieser Artikel aber schon ein wenig lang ist, gibt es weitere Details und eine Beispiel-Implementierung im nächsten Artikel.
Troubleshooting
Wenn man einen Bot implementiert, funktioniert natürlich nicht immer alles. Ein paar der Probleme, die ich hin und wieder hatte und wie man diese behebt, findest du hier:
Der Bot bekommt keine Nachrichten
Wenn der Bot keine Requests bekommt, kann es sein, dass man vergessen hat, die Page-App-Verbindung herzustellen. Dazu führt man einfach den oben beschriebenen curl-Befehl mit dem Page-Access-Token aus.
Die Webhooks konnten nicht (mehr) erreicht werden
Es kann manchmal bei der Entwicklung sein, dass der Server nicht immer läuft. Facebook merkt das ggf. und beendet dann die Webhook-Verbindung. Dies sieht man dann im Menüpunkt „Benachrichtigungen“ im App-Dashboard. Der einfachste Weg, diese wieder zu aktivieren, ist eine erneute Aktivierung des Webhooks. Dazu entfernt man den bestehenden Webhook im Menüpunkt „Webhooks“ im App-Dashboard. Danach kann man den ihn mit dem Verifizierungs-Token im Menüpunkt „Messenger“, wie oben beschrieben, neu erstellen. Danach sollte wieder alles funktionieren (soweit der Server funktioniert).
Ein Fehler im Script ist aufgetreten
Hat man einen Fehler in seinem Server und antwortet dieser daher mit etwas anderem als Status-Code 200, gibt es ein kleines Timeout bei Facebook. D.h. nach Fixen des Fehlers muss man ca. 1 Minute warten, bis Facebook wieder Nachrichten an den Server schickt. Leider etwas nervig und es wäre schön, wenn unveröffentlichte Bots diese Einschränkung nicht hätten.
Ich hoffe, diese Tutorial war hilfreich. Im nächsten Artikel beschreibe ich dann, wie man strukturierte Nachrichten sendet, wie diese strukturiert sind und wie man einen Willkommens-Screen erstellt.
Bildnachweis:
D J Shin, S.H Horikawa – Star Strider Robot (スターストライダーロボット) – Front, D J Shin, QSH Tin Wind Up Mechanical Robot (Giant Easelback Robot) Side, Collage von Christian Scholz, CC BY-SA 3.0
_–_Front.jpg){kind=link}
_Side.jpg){kind=link}
Layouts mit Cards oder Boxen sieht man ja immer noch recht viel. Man braucht dazu nur auf unsere Blog-Startseite zu schauen oder die verwandten Artikel in diesem Artikel. Je nach Inhalt haben diese Boxen dann aber gerne mal unterschiedliche Höhen. In diesem Artikel erfährst Du, wie man Boxen mit gleicher Höhe nur in CSS implementiert.
Schauen wir das Problem mal im Detail an: Nimmt man einfach eine panel-Klasse von Bootstrap, eine feste Breite und einen float:left , sieht das so aus:
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Der Code dazu:
<style>
.panel-test {
width: 30%;
padding: 20px;
float: left;
margin: 10px;
border: 1px solid #aaa;
}
</style>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist kurze Headline</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
Recht schön sieht das nicht aus (zumindest nicht, wenn dann große Löcher entstehen).
Eine Abhilfe kann hier die Definition einer festen Höhe sein. Dann muss man aber sehr genau darauf achten, dass man nicht zu viel Text schreibt, da dieser sonst aus der Box läuft oder abgeschnitten würde.
Boxen mit gleicher Höhe dank flexbox
Zum Glück gibt es ein CSS-Konstrukt, das hier Abhilfe schafft und inzwischen auch vom Großteil der Browser unterstützt wird.
Gemeint ist das flexbox-Modell (hier geht es zum Standard). Dies ist eine Layout-Methode, die Boxen innerhalb eines Containers effizient verteilen und ausrichten kann, auch wenn die Größen unterschiedlich/unbekannt sind.
Die Grundidee ist, dass Boxen innerhalb eines Containers anhand einer Achse ausgerichtet und verteilt werden. Dies kann dann mit entsprechenden Direktiven genauer gesteuert werden.
Allerdings soll dies jetzt keine komplette Einführung sein, sondern nur ein Beispiel, wie man das obige Problem mit Hilfe des Flexbox-Modus lösen kann.
Dazu brauchen wir zunächst einen Container und die Boxen dann innerhalb des Containers:
<div id="flex-container">
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist kurze Headline</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
<div>
<h3>Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält</h3>
</div>
</div>
Als nächstes muss das CSS eigentlich nur noch um die entsprechenden Flex-Direktiven erweitert werden:
<style>
#flex-container {
display: -webkit-flex;
display: -ms-flex;
display: flex;
-webkit-flex-wrap: wrap;
-ms-flex-wrap: wrap;
flex-wrap: wrap;
}
.panel-test2 {
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
width: 30%;
padding: 20px;
float: left;
margin: 10px;
border: 1px solid #aaa;
}
</style>
Wie man sieht, wird hier das Flex-Layout mit display: flex sowohl für den Container als auch die Child-Elemente eingeschaltet. Dies führt schon automatisch dazu, dass alle Boxen die gleiche Höhe bekommen. Die Höhe ist dabei die des größten Elements.
Allerdings würden dann alle Boxen in einer Zeile erscheinen und entsprechend schmaler werden. D.h. die definierte Breite würde ignoriert werden.
Damit stattdessen die vordefinierte Breite von 30% genutzt wird, wird flex-wrap: wrap eingesetzt. Dies sagt dem Container, dass „überschüssige“ Boxen in die nächste Zeile rutschen sollen.
Das Ergebnis sieht dann so aus:
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist kurze Headline
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Dies ist eine Test-Headline, die ein bisschen länger ist, da sie viel Text enthält
Wie man sieht, ist die Lösung für dieses Problem relativ einfach.
Man sollte dabei natürlich auf Browser-Kompatibilitäten achten. So gibt es Flexbox in allen modernen Browsern und im IE ab Version 11. Testen sollte man es aber natürlich dennoch.
Als ich dieses Blog aufsetzte, war ich natürlich auch auf der Suche nach einem Plugin, mit dem ich verwandte Artikel verlinken kann. Es gibt diverse Plugins für WordPress, die das automatisiert machen können, wie z.B. Yet Another Related Posts Plugin oder Contextual Related Posts – ich aber will diese Artikel manuell aussuchen. So habe ich mehr Kontrolle und bin mir sicher, dass die Artikel auch Sinn machen.
Die Anforderungen
Die Anforderungen waren für mich im Detail:
- Ich will bei einem Artikel zu anderen Artikeln angeben
- Bis zu 3 Verweise sollen unter dem Artikel erscheinen
- Verlinke ich einen Artikel, soll dieser Artikel auch automatisch einen Backlink bekommen.
- Trotzdem sollen insgesamt nur 3 Artikel in der Liste angezeigt werden, wobei die ausgehenden Links Vorrang haben sollen.
Ich habe mir zunächst das Manual Related Posts Plugin angeschaut, das allerdings seit 7 Monaten nicht mehr aktualisiert wurde. Zudem hatte ich auch ein paar Probleme mit dem Styling, da er z.B. feste style-Angaben in den Code schreibt, die man zwar theoretisch per Filter ändern kann, was aber für mich nicht so richtig funktioniert hat.
Die nächste Idee war dann, das direkt selbst im Theme zu implementieren. Problem hierbei: Benutzer-Interfaces in WordPress zu implementieren ist nicht gerade ein Spaß (zumindest out of the box). Und an dieser Stelle kam dann das Advanced Custom Fields Plugin ins Spiel. Hier muss man zwar immer noch selbst ein bisschen Code schreiben, aber die UI-Arbeit ist damit zum Glück schon erledigt. (Dank geht an Claudia von Chilliscope, die mich wieder dran erinnerte, dass es dieses Plugin ja auch noch gibt).
Was ist das Advanced Custom Fields Plugin (ACF)?
Kurz gesagt, lassen sich mit dem Advanced Custom Fields Plugin neue Metadaten-Felder für Artikel, Seiten und Custom Content Types definieren. Diese Felder sind dabei deutlich ausgereifter im UI als die Standard-WordPress-Implementierung. Hinzu kommt eben, dass man sich um das Benutzer-Interface dann gar nicht mehr selbst kümmern muss.
Allerdings muss man schon etwas programmieren können, um ACF nutzen zu können, denn es fragt nur die Daten ab, zeigt sie aber zunächst nicht wieder an. Dazu muss man das Theme entsprechend anpassen, was PHP-Kenntnisse benötigt.
Verwandte Artikel mit Advanced Custom Fields implementieren
Wie geht man also nun vor, um eine manuelle Verlinkung von Artikeln zu implementieren? Am Anfang steht die Definition des benötigten Feldes, in dem man die Artikel aussucht, die man verlinken will. Dazu legt man unter dem Menüpunkt Eigene Felder zunächst eine neue Gruppe an, die man beliebig nennen kann. Bei mir heißt sie „Post Links“. Direkt darunter kann man dann ein neues Feld erstellen. Als Titel habe ich „Verwandte Artikel“ gewählt, als internen Namen „related_posts“ und als Feld-Typ Beziehung. Man hätte auch den Artikel-Typ nehmen können, aber dann bekommt man nur eine lange Liste von Artikeln angezeigt. Das Beziehungs-Feld dagegen hat noch eine Suche eingebaut ähnlich dem Link-Dialog.
Wichtig für mich war weiterhin, dass ich nur Posts erlaube, dass man nicht zwingend etwas auswählen muss, und dass man mehrere Artikel selektieren kann.
Insgesamt sieht das dann so aus:
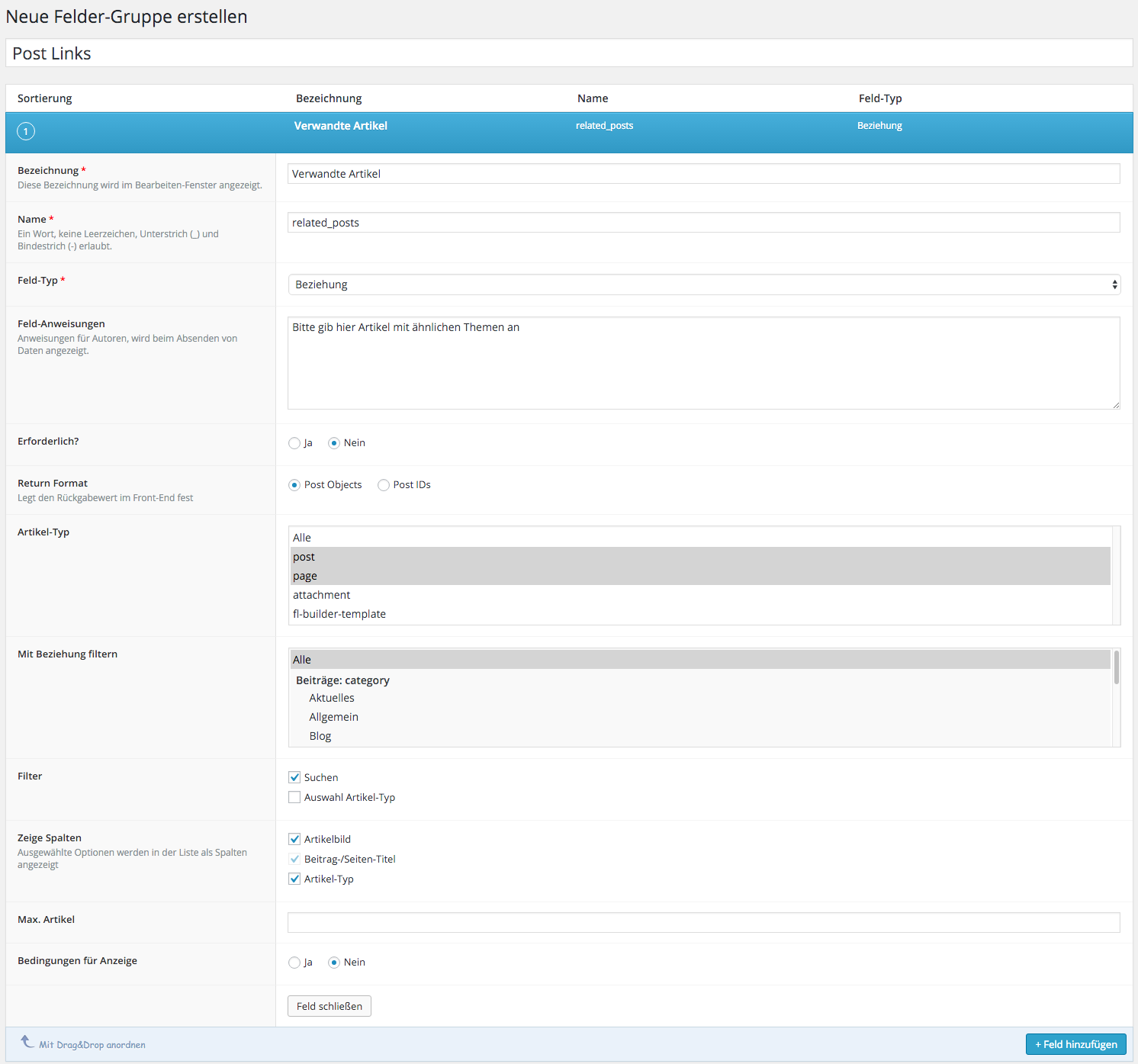
Beziehungsfeld für die verwandten Artikel anlegen
Bei den Optionen kann man dann noch angeben, dass die Gruppe unter dem Inhalt („normal“) angezeigt werden soll und dass der Stil „Standard“ sein soll (also mit Rahmen). Und bitte nicht vergessen, vorher auch das Feld hinzuzufügen, die Optionen gelten nämlich für die ganze Gruppe.

Optionen in ACF einstellen
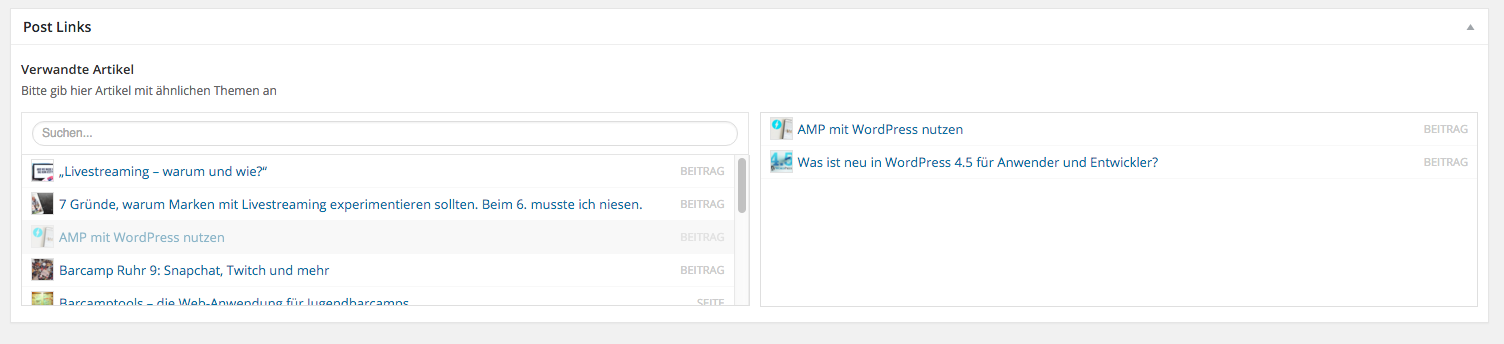
Hat man das alles gemacht, erscheint rechts in der Seitenleiste bei den Artikeln eine neue Box namens „Post Links“, wo man dann beliebig viele Artikel selektieren kann (von denen wir später aber nur maximal 3 anzeigen).
Das Beziehungsfeld in Aktion
Optional: Feld-Liste als PHP exportieren
Ich persönlich habe dies zunächst auf meiner Test-Installation gemacht und habe danach unter „Eigene Felder“ den Punkt „Export“ und dann „Export als PHP“ gewählt. Heraus kommt PHP-Code, der in die functions.php im Theme eingebaut werden kann.
Der Vorteil: Ich muss die Feld-Definition nicht bei jedem Blog vornehmen, sondern sie ist fest im Theme verankert (ACF muss aber installiert sein). In meinem Fall kann ich einfach das Theme auf die Live-Site deployen und schon erscheinen die Felder. So würde ich mir das bei allen Plugins wünschen.
Man sollte allerdings die Gruppe im Backend wieder löschen, nachdem man den PHP-Code ins Theme eingebaut hat, da ansonsten die Felder doppelt erscheinen könnten.
Verwandte Artikel ausgeben
Jetzt können wir Artikel selektieren, jedoch werden sie noch nicht ausgegeben. Gehen wir dazu am besten Schritt für Schritt vor. Dazu habe ich in der Datei single.php im HTML einen neuen Bereich für die Artikel-Liste geschaffen und folgenden Code für die Liste selbst genutzt:
<?php
$related = get_field("related_posts");
// output all the related articles
if( $related ): ?>
<h2>Vielleicht auch total interessant:</h2>
<div class="row">
<?php foreach( $related as $post): setup_postdata($post); ?>
<div class="col-md-4">
<div class="panel">
<a href="<?php the_permalink(); ?>" title="<?php echo esc_attr( the_title_attribute( 'echo=0' ) ); ?>" rel="bookmark">
<?php echo the_post_thumbnail("featured-wide", array( 'class' => 'img-responsive') ); ?>
<div class="panel-heading">
<h5 class="entry-title clearfix"> <?php the_title(); ?> </h5>
</div>
</a>
</div>
</div>
<?php endforeach; ?>
</div>
<?php
wp_reset_postdata();
endif;
?>
Noch erfüllt das allerdings nicht alle Anforderungen, vor allem werden die auf diesen Artikel zeigenden Artikel noch nicht dargestellt. Außerdem werden mehr als 3 Artikel angezeigt, wenn sie vorhanden sind. Darauf kann man natürlich im Backend achten, wenn aber noch die eingehenden Links dazukommen, können es auch deutlich mehr als 3 werden.
Eingehende Links darstellen
Um die eingehenden Artikel-Verlinkungen auch darstellen zu können, muss man die Datenbank befragen. Dies geht mit folgendem Code-Schnipsel:
$incoming = get_posts(array(
'post_type' => 'post',
'meta_query' => array(
array(
'key' => 'related_posts', // name of custom field
'value' => '"' . get_the_ID() . '"', // matches exaclty "123", not just 123. This prevents a match for "1234"
'compare' => 'LIKE'
)
)
));
Es wird hier wieder das Feld related_posts genutzt, allerdings wird gefragt, welche Artikel die ID des aktuellen Artikels in diesem Feld beinhalten. Die Liste dieser Artikel wird dann in $incoming abgespeichert.
Als nächstes müssen wir das noch mit den ausgehenden Links zusammenführen und auf 3 Artikel insgesamt begrenzen:
if (!$related) {
$related = array();
}
$related = array_merge($related, $incoming); // merge own and incoming together
// limit to 3 articles, own links always take precedence
$related = array_slice($related, 0, 3);
Wichtig ist auch der erste Teil, wo wir sicherstellen, dass die $related-Variable auch wirklich ein Array ist, damit array_merge keinen Fehler wirft.
Insgesamt kommen wir dann auf folgenden Code:
<?php
$related = get_field("related_posts");
// merge in articles pointing to this post
$incoming = get_posts(array(
'post_type' => 'post',
'meta_query' => array(
array(
'key' => 'related_posts', // name of custom field
'value' => '"' . get_the_ID() . '"', // matches exaclty "123", not just 123. This prevents a match for "1234"
'compare' => 'LIKE'
)
)
));
if (!$related) {
$related = array();
}
$related = array_merge($related, $incoming); // merge own and incoming together
// limit to 3 articles, own links always take precedence
$related = array_slice($related, 0, 3);
// output all the related articles
if( $related ): ?>
<h2>Vielleicht auch total interessant:</h2>
<div class="row">
<?php foreach( $related as $post): setup_postdata($post); ?>
<div class="col-md-4">
<div class="panel">
<a href="<?php the_permalink(); ?>" title="<?php echo esc_attr( the_title_attribute( 'echo=0' ) ); ?>" rel="bookmark">
<?php echo the_post_thumbnail("featured-wide", array( 'class' => 'img-responsive') ); ?>
<div class="panel-heading">
<h5 class="entry-title clearfix"> <?php the_title(); ?> </h5>
</div>
</a>
</div>
</div>
<?php endforeach; ?>
</div>
<?php
wp_reset_postdata();
endif;
?>
Und das ist auch der Code, der jetzt hier auf der Site im Einsatz ist. Dank Advanced Custom Fields war das recht flott zu implementieren und erfüllt alle meine Anforderungen. Ein ingesamt kleines Beispiel, aber man sieht gut daran, dass hier mit etwas Fantasie noch sehr viel mehr möglich ist.
Was habt ihr denn so damit gebaut?
Wer kennt das nicht: Man hat ein frisches WordPress-Blog und ein nettes Theme gefunden, doch irgendwie fehlen dem Theme noch 1-2 kleine Features, wie eine Lightbox oder ähnliches. Gibt es für das Problem kein passendes WordPress-Plugin, sondern nur ein jQuery-Plugin, stellt sich dann die Frage, wie man dies in das Theme einbaut.
Daher will ich in dieser Anleitung zeigen, wie man ein jQuery-Script in 2 einfachen Schritten in das eigene oder ein bestehendes Theme einbauen kann.
1. Das jQuery-Plugin im Theme-Verzeichnis ablegen
Dazu erstellt man, wenn es noch nicht vorhanden ist, ein neues Verzeichnis namens js/ innerhalb des Theme-Ordners. Dort kopiert man das jQuery-Script hinein, z.B. /js/query.plugin.min.js. Auch eigene Scripts kann man dort ablegen.
2. Das jQuery-Plugin aktivieren
Damit das jQuery-Plugin auch genutzt wird, muss man WordPress noch sagen, wo es liegt und wie es eingebunden werden soll. Dies geschieht in der functions.php des Themes.
Dort schreibst Du jetzt einfach folgenden Code rein, wobei Du den Dateinamen des Plugins natürlich entsprechend anpassen musst:
add_action( 'wp_enqueue_scripts', 'add_my_scripts' );
function add_my_scripts () {
wp_enqueue_script(
'my-plugin', // eigener Name
get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
}Folgendes passiert hier:
add_actionsagt WordPress, dass es für die Aktionwp_enqueue_scriptsauch noch unsere Funktionadd_my_scriptsaufrufen soll. Diese ist in der 2. Zeile ff. definiert.- Wenn WordPress die Seite darstellen will, geht es u.a. auch alle registrierten Funktionen für diese Aktion durch und ruft dann unsere Funktion auf
- Mit
wp_enqueue_script(Nicht verwechseln mit dem Aktionsnamen) sagen wir dann WordPress, welche JavaScript-Dateien auf der Seite zusätzlich auftauchen sollen (Plugins und das Theme selbst können auch schon welche definiert haben). - Dieser Funktion übergibt man als Parameter den Namen des Scripts, den Pfad zur eigentlichen JS-Datei und eine Liste von Abhängigkeiten (optional).
Hierbei musst Du auf folgende Sachen achten:
- Der Name muss einmalig sein (hier „my-plugin“). Dieses identifiziert das Plugin gegenüber WordPress. Der Name sollte am besten klein geschrieben sein und keine Leerzeichen enthalten.
- Der Pfad muss natürlich stimmen (hier
/js/jquery.plugin.min.js). - Die Abhängigkeiten müssen stimmen, in diesem Fall normalerweise einfach
array("jquery"). Schließlich binden wir ja ein jQuery-Plugin ein und das benötigt sicherlich jQuery als Grundlage. WordPress weiß dadurch, dass es erst (das mitgelieferte) jQuery laden soll und dann unser Script.
Achtung: Child-Themes
Wenn Du ein Child-Theme nutzt (z.B. um das Original-Theme nicht ändern zu müssen), dann ändert sich der Aufruf wie folgt:
wp_enqueue_script( 'my-plugin', // eigener Nameget_stylesheet_directory_uri() . '/js/jquery.plugin.min.js', // Pfad array('jquery') // Abhängigkeiten );
Es wird also get_template_directory_uri durch get_stylesheet_directory_uri ersetzt, damit WordPress im richtigen Verzeichnis nachschaut (im Child-Theme und nicht im Haupt-Theme).
Und damit sollte das Plugin erfolgreich eingebunden sein.
Optional: Eigenes JavaScript als Datei einbinden
Oftmals muss man die Funktionen, die das jQuery-Plugin bereitstellt, auch noch aufrufen. Dies geschieht entweder direkt im Footer der Seite (also wahrscheinlich dann in footer.php) oder man lagert dies in ein eigenes Script aus. Gerade wenn es mehr Code wird, macht dies aus Organisations- und Performance-Sicht Sinn.
Nehmen wir also an, Du legst den JavaScript-Code in /js/scripts.js ab, dann musst Du noch einen weiteren wp_enqueue_script-Aufruf zu add_my_scripts hinzufügen:
add_action( 'wp_enqueue_scripts', 'add_my_scripts' ); function add_my_scripts () { wp_enqueue_script( 'my-plugin', // eigener Name get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad array('jquery') // Abhängigkeiten );// jetzt noch eigenes Script ladenwp_enqueue_script( 'my-script', // eigener Name get_template_directory_uri() . '/js/scripts.js', // Pfad array('my-plugin') // Abhängigkeiten );
}
Hier siehst Du folgende Änderungen im Aufruf:
- Das Script hat einen anderen Namen (
my-script) - Der Pfad ist entsprechend anders (dieselben Regeln für ein Child-Theme gelten)
- Die Abhängigkeit ist nicht mehr
jquery, sondern jetztmy-plugin, also das Plugin, welches Du in Deinem Script benutzt. Man hätte auch nochjqueryzusätzlich angeben können (dann alsarray('jquery', 'my-plugin')), aber damy-pluginschonjqueryals Abhängigkeit hat, ist das nicht unbedingt notwendig.
Script-Versionen definieren
Der obige Aufruf von wp_enqueue_script funktioniert super, solange man immer dieselbe Version eines Scripts/Plugins nutzt. Aktualisiert man das Script aber, kann es je nach Caching-Setup dazu kommen, dass Benutzer noch die alte Version ausgeliefert bekommen. Um dies zu vermeiden, kann man an den Aufruf noch eine Versionsnummer übergeben, z.B. so:
wp_enqueue_script(
'my-script', // eigener Name
get_template_directory_uri() . '/js/scripts.js', // Pfad
array('my-plugin'), // Abhängigkeiten
'20160323'
);
Wie man sieht, wurde mangels offizieller Versionsnummer einfach ein Datum als Versions-String genutzt. Lädt man fertige Plugins aus dem Netz herunter, sollte man die offizielle Versionsnummer dort eintragen (immer als String).
Script im Footer laden
Nicht alles muss im Header der Seite geladen werden. Genauer genommen sollte eigentlich alles, was möglich ist, im Footer geladen werden. Dadurch kann eine Seite teilweise deutlich schneller angezeigt werden.
Um ein Script von WordPress in den Footer laden zu lassen, kannst Du einen weiteren Parameter an wp_enqueue_script anhängen:
wp_enqueue_script(
'my-script', // eigener Name
get_template_directory_uri() . '/js/scripts.js', // Pfad
array('my-plugin'), // Abhängigkeiten
'20160323', // Versionsnummer
true // lade es im Footer
);
Also einfach noch true anhängen und schon wird es im Footer geladen.
Scripts im Admin-Bereich laden
Wenn ihr das so, wie oben beschrieben, einbaut, dann werden die angegebenen Scripts nur im Frontend geladen. Normalerweise reicht das auch, denn es geht ja um das Theme und damit um die öffentliche Ansicht.
Wenn ihr aber jetzt Plugin- oder Theme-Entwickler seid, dann wollt ihr bestimmte JavaScript-Dateien ggf. auch im Admin-Bereich laden. Dazu nutzt ihr einfach eine andere Aktion, nämlich statt wp_enqueue_scripts dann admin_enqueue_scripts. Wichtig: Es geht hier um den Aktionsnamen, nicht etwa um die Funktion zum Definieren der Scripts, diese ist weiterhin wp_enqueue_script (Singular).
Das erste Beispiel würde also für den Admin-Bereich wie folgt aussehen:
add_action( 'admin_enqueue_scripts', 'add_my_scripts' );
function add_my_scripts () {
wp_enqueue_script(
'my-plugin', // eigener Name
get_template_directory_uri() . '/js/jquery.plugin.min.js', // Pfad
array('jquery') // Abhängigkeiten
);
}
Ich hoffe, euch damit geholfen zu haben. Fragen könnt ihr gerne in den Kommentaren hinterlassen. Generell hilft auch, die Doku zu wp_enqueue_script und der zugehörigen Aktion wp_enqueue_scripts zu lesen oder aber Dinge einfach auszuprobieren.
Wie in diesem Artikel beschrieben, pusht Google gerade massiv ihr Accelerated Mobile Pages-Projekt (AMP). Kurz gesagt, geht es dabei darum, mobile Webseiten schneller ausliefern zu können. Bei AMP geschieht das dadurch, dass einerseits die Webseite auf das Wesentliche reduziert wird (kein JavaScript, wenig CSS, definierte Lade-Reihenfolge) und die Seiten durch Google’s CDN ausgeliefert werden.
Wichtig ist AMP vor allem inzwischen für Nachrichtensites und Blogs, da AMP-Seiten seit Februar in der Suche prominent ganz oben dargestellt werden (wenn man als Top-Story qualifiziert). Aus SEO-Sicht kommt man also eigentlich um AMP nicht herum.
Wenn Du also ein WordPress-Blog hast, dann solltest Du zusehen, dass Du AMP aktivierst, was zum Glück nicht wirklich schwer ist.
AMP-Seiten im Google News-Karussell
AMP in WordPress dank Plugin
Wie immer bei WordPress gibt es natürlich schon längst ein Plugin namens AMP, diesmal sogar auch direkt aus dem Hause Automattic
Installiert und aktiviert man dies, so werden alle Artikel (nicht Seiten) automatisch mit einer AMP-Variante versehen. Ansehen kann man diese, indem man einfach /amp/ an die URL anhängt, also z.B. https://comlounge.net/lead-generierung-call-to-actions/amp/. Es wird dabei nur der Post-Content genutzt und in einen einfachen Layout-Rahmen gesteckt. Hat man ein Site-Icon definiert, so wird dies ebenfalls im Header angezeigt.
Diese AMP-Seite wird dabei vom eigentlichen Beitrag automatisch über <link rel="amphtml" href="..." /> verlinkt und ist somit durch Google auffindbar.

Beispiel AMP-Seite
AMP anpassen
Da das Plugin selbst keinerlei UI hat und somit keine Design-Änderungen zulässt, muss man sich anders behelfen. Wer das Yoast SEO-Plugin nutzt, kann z.B. das Yoast SEO AMP Glue plugin installieren, das mehr Möglichkeiten eröffnet. Damit kann man AMP nicht nur für Artikel, sondern auch für Seiten und Medienobjekte aktivieren. Vor allem aber kann man die Farben und auch das Site-Icon ändern oder ein Default-Featured Image setzen. Ein solches Bild ist nämlich wichtig, damit Google die Seite richtig indiziert.
Wer ein Site-Icon nutzt, wird sich vielleicht ärgern, dass es rund ausgeschnitten wird, was sich nicht für jedes Logo eignet. Zum Glück kann man dies recht einfach im Custom CSS-Feld mit folgendem Code ausschalten:
nav.amp-wp-title-bar .amp-wp-site-icon { border-radius: 0; }
Das Yoast-Plugin kümmert sich weiterhin automatisch um die Einbindung von Analytics in die AMP-Seite, wenn man Google Analytics von Yoast installiert hat. Es kann aber auch ein manueller Tracking-Code angegeben werden.
Eine Alternative zu diesem Plugin, was ja sehr in das Yoast-Ökosystem integriert ist, wäre das Plugin von Pagefrog, was nicht nur AMP-Versionen erstellt, sondern auch Versionen für den Facebook Instant Articles oder Apple News. Allerdings stellt man sich im Forum schon die Frage, ob es noch weiterentwickelt wird, da man von den Entwicklern nichts mehr hört. Da die letzte Version aber nur 2 Wochen alt ist (beim Yoast-Plugin gerade aber ähnlich), sollte man das vielleicht erstmal beobachten. Im Zweifel sollte man sicherlich beide Plugins mal ausprobieren und schauen, was für einen selbst besser funktionieret.
Featured Image anzeigen
Wenn vom Featured Image die Rede ist, so muss man unterscheiden zwischen dem, was Google indiziert und dem, was angezeigt wird. Standardmäßig wird nämlich das Bild gar nicht ausgegeben, sondern nur in den Metadaten aufgelistet. Das ist für Google ausreichend, um es im News-Karussell anzuzeigen, schön wäre aber dennoch, das auch auf der Seite sehen zu können.
Hat man sein eigenes Theme, kann man dies wie folgt in der functions.php lösen:
add_action( 'pre_amp_render_post', 'xyz_amp_add_custom_actions' );
function xyz_amp_add_custom_actions() {
add_filter( 'the_content', 'xyz_amp_add_featured_image' );
}
function xyz_amp_add_featured_image( $content ) {
if ( has_post_thumbnail() ) {
// Just add the raw <img /> tag; our sanitizer will take care of it later.
$image = sprintf( '%s', get_the_post_thumbnail() );
$content = $image . $content;
}
return $content;
}
Weitere Möglichkeiten, um seine AMP-Seite anzupassen, sind in diesem README aufgelistet.
Post-Inhalte mit Shortcodes anreichern
Noch ein kleiner Tipp zum Ende: Die AMP-Version einer Seite beinhaltet wirklich nur den Artikelinhalt und keine anderen Elemente (z.B. Ausgaben von anderen Plugins, die über oder unter einem Artikel erscheinen, wie z.B. verwandte Beiträge oder Werbung). Wer dies in der AMP-Version (für RSS gilt wohl dasselbe) mehr als nur den Inhalt ausliefern möchte, muss dies in den Artikel direkt reinschreiben. Dies kann z.B. mit Shortcodes gelöst werden, wobei man aber beim Schreiben dran denken muss, es auch wirklich manuell reinzuschreiben. Da der Shortcode Teil des Beitrags ist, erscheint die Ausgabe dann auch in der AMP-Version.
Die Shortcodes selbst können dabei entweder von bestehenden Plugins kommen oder man kann sie als Entwickler selbst im Theme definieren. Wichtig ist dabei nur, dass kein JavaScript funktioniert und das CSS entweder über das Custom CSS-Feld des Yoast-Plugins oder aber auch in der functions.php speziell für AMP eingebunden werden muss. Für Werbung wird wahrscheinlich ein Bild mit Link am besten funktionieren.
Fazit
Generell ist die Aktivierung von AMP dank des Plugins recht einfach. Man sollte allerdings in der Suchkonsole darauf achten, dass Google die AMP-Seiten auch richtig indiziert. Zudem steckt AMP und vor die Wordpress-Integration noch ein bisschen in den Kinderschuhen. Da wird sicherlich in Zukunft noch einiges passieren, sowohl am Standard als auch an der WordPress-Implementierung. Wir werden euch auf dem Laufenden halten!
In meinem ersten Tutorial auf diesem Blog will ich darstellen, wie man Gemeindegrenzen auf einer Auf Open Street Map basierenden Karte darstellen kann. Die Gemeindegrenzen (in diesem Fall NRW) selbst nehme ich dabei nicht direkt von OSM, sondern aus einem Shapefile, das ich in diesem Fall von der Seite zur Landtagswahl des Innenministeriums herunterlade. Als Grundlage für die OSM-Darstellung nehme ich die JavaScript-Library leaflet.js.
Shapefile in GeoJSON überführen
Die Hauptaufgabe ist nun, das Shapefile mit den Gemeindegrenzen in das GeoJSON-Format zu überführen, denn dies ist das Format, das leaflet erwartet. Lädt man die Geometrie der Gemeinden (direkter Downloadlink) herunter und entpackt das ZIP-File, so erhält man folgende laut zu einem Shapefile zugehörigen Dateien:
DVG1_Gemeinden_utm.dbf DVG1_Gemeinden_utm.prj DVG1_Gemeinden_utm.shp DVG1_Gemeinden_utm.shx
Wichtig ist dabei im Prinzip nur die Datei mit Endung .shp, da diese die eigentlichen Geometrien enthält.
Um diese Datei in GeoJSON umzuwandeln gibt es zum Glück ein Tool, dass sich ogr2ogr nennt und im GDAL-Paket zu finden ist. Unter OSX kann man dies mit macports wie folgt installieren:
sudo port install gdal +geos
Bevor man die Konvertierung startet, muss man zwei Dinge beachten. Zunächst einmal die Art der Projektion. So gibt es verschiedene Verfahren, die Erdkugel auf eine rechteckige Karte zu projizieren. Das Shapefile benutzt UTM (wie im Dateinamen zu erkennen), leaflet bzw. OSM mag aber lieber EPSG:3857. Hier muss man also entweder umrechnen oder in leaflet die Projektion umstellen, was mit dem Plugin Proj4Leaflet geht. Ich werde hier aber die Daten schon vorher auf die Ziel-Projektion umrechnen.
Das zweite Problem ist die Datenmenge. Die Definition der Gemeindegrenzen ist nämlich sehr genau, was bedeutet, das die Polygone sehr viele Punkte beinhalten. Dies bedeutet aber, dass die Karte eher behäbig daherkommt. Da es bei der Darstellung aber eher auf die Flächen ankommt und man sowieso nicht bis auf den letzten Stein herunter zoomen kann, können und sollten diese Polygone vereinfacht werden.
Beide Probleme lassen sich glücklicherweise direkt mit ogr2ogr lösen und der zugehörige Aufruf sieht wie folgt aus:
ogr2ogr -f geojson -simplify 20 -t_srs EPSG:4326 -a_srs EPSG:4326 gemeinden.json DVG1_Gemeinden_utm.shp
Die einzelnen Argumente bedeuten dabei folgendes:
- -f geojson definiert das Zielformat, das wir wünschen
- -simplify 20 vereinfacht die Polygone. Mit dem Faktor 20 erhält man dabei statt einer 43 MB-Datei eine nur 4,9 MB grosse Datei. Den Wert habe ich dabei durch Ausprobieren ermittelt, indem ich mehrere Werte angegeben habe und auf der Karte geschaut habe, wo die Polygone zu grob wurden.
- – t_srs EPSG:4326 definiert die Ziel-Projektion
- -a_srs EPSG:4326 definiert die Ausgabe-Projektion (was genau der Unterschied zu oben ist, ist mir leider nicht so klar, aber so funktioniert es)
Eine Besonderheit von ogr2ogr ist dabei, dass zunächst die Zieldatei angegeben wird und dann erst die Quelldatei. Also aufpassen!
Man beachte auch die Projektion, denn entgegen meiner vorherigen Behauptung mit EPSG:3857 arbeitet leaflet dann wohl doch lieber mit EPSG:4326 (wenn ich das richtig verstehe ist letztere der Koordinatensatz auf einer Kugel, während 3857 die projizierte Version ist. Ob leaflet das dann automatisch umrechnet, ist mir nicht so ganz klar, mit 4326 funktioniert es aber auf jeden Fall).
Hat man nun die Datei, muss man sie nur noch anzeigen. Dazu initialisiert man zunächst leaflet (und jquery gleich mit). Laden wir zunächst die notwendigen Dateien vom CDN:
<link rel="stylesheet" href="http://cdn.leafletjs.com/leaflet-0.5/leaflet.css" />
<script src="http://code.jquery.com/jquery-1.9.1.min.js"></script>
<script src="http://code.jquery.com/jquery-migrate-1.1.1.min.js"></script>
<script src="http://cdn.leafletjs.com/leaflet-0.5/leaflet.js"></script>
Dann noch ein bisschen CSS für eine Fullscreen-Map:
<style>
html, body, #map {
height: 100%;
}
</style>
Die Karte selbst ist nur ein DIV:
<div id="map"></div>
Dann brauchen wir noch Code zum Initialisieren der Karte grob auf NRW (ausserdem benötigt man noch einen API-Key von cloudmade.com, wobei man zum Experimentieren aber alternativ auf die Tiles von OSM nutzen kann. Die Nutzung ist dort allerdings eingeschränkt):
<script>
$(document).ready(function() {
var map = L.map('map').setView([51.463, 7.18], 10);
L.tileLayer('http://{s}.tile.cloudmade.com/API-KEY/{z}/{x}/{y}.png', {
attribution: 'Map data © <a href="http://openstreetmap.org">OpenStreetMap</a> contributors, <a href="http://creativecommons.org/licenses/by-sa/2.0/">CC-BY-SA</a>, Imagery © <a href="http://cloudmade.com">CloudMade</a>',
maxZoom: 18
}).addTo(map);
</script>
Nun müssen wir nur noch das GeoJSON-Objekt laden und anzeigen. Dies geschieht per getJSON-Aufruf:
$.getJSON("/gemeinden/gemeinden.json", function(data) {
L.geoJson(data, {
style: function(feature) {
switch (feature.properties.KN) {
default:
return {
fillColor: '#00'+(0x1000000+(Math.random())*0xffffff).toString(16).substr(1,2)+"00",
fillOpacity: 0.5,
weight: 2,
color: '#111',
opacity: 0.7,
dashArray: '4'
}
}
}
}).addTo(map);
});
Wichtig ist dabei hauptsächlich der Aufruf von L.geoJSON und der Angabe der Daten. Mit der style-Funktion ist man zusätzlich noch in der Lage einzelne Flächen einzufärben (hier per random-Grün), die Grenzen zu stylen usw. Mehr Informationen erhält man hier.
Ein komplettes Demo gibt es auch!
Heute habe ich dank des Ausfalls unseres Mailservers bei Strato den dort befindlichen Mailman auf unserem neuen Mailserver (kein Strato mehr) installiert. Da dabei ein paar Besonderheiten anfallen was die Kombination mit nginx betrifft, will ich das hier kurz dokumentieren, damit ich das beim nächsten Server schnell wieder parat habe. Ich gehe dabei davon aus, dass nginx schon installiert ist.
Zunächst einmal muss man mailman selbst installieren:
apt-get install mailman
thttpd
Da mailman auf cgi-bin aufbaut, nginx aber kein cgi-bin unterstützt, scheint der einfachste Weg zu sein, noch thttpd zu installieren (fastcgi geht theoretisch auch, wollte aber aus mir unbekannten Gründen kein PATH_INFO an Mailman weiterleiten):
apt-get install thttpd
Bei thttpd handelt es sich dabei um einen sehr kleinen HTTP-Server, der cgi-bin unterstützt und den wir als Proxy benutzen werden.
Dazu muss thttpd natürlich konfiguriert werden, was in der Datei /etc/thttpd/thttpd.conf passiert. Hier die wichtigsten Zeilen:
port=7999 dir=/usr/lib/cgi-bin nochroot user=www-data cgipat=/** host=127.0.0.1
Wichtig ist also, dass wir auf einem anderen Port als 80 laufen, dass wir nur auf 127.0.0.1 hören, dass wir kein chroot machen, unter www-data laufen und dass wir alle URLs als cgi-Scripts interpretieren und nicht nur die mit Prefix /cgi-bin/
Dann muss der Daemon noch ggf. in /etc/default/thttpd eingeschaltet werden und mit
/etc/init.d/thttpd start
gestartet.
nginx
Für nginx brauchen wir ggf. einen neuen virtual host, in den wir folgendes eintragen:
server {
listen 80;
server_name meinedomain;
access_log /var/log/nginx/domain.access.log;
error_log /var/log/nginx/domain.net.error.log;
location /mailman/ {
proxy_pass http://127.0.0.1:7999/mailman/;
proxy_set_header Host $host;
}
location /images/mailman {
alias /usr/share/images/mailman;
}
location /pipermail {
alias /var/lib/mailman/archives/public;
autoindex on;
}
}
Wir richten also einen ganz normalen reverse-Proxy ein.
Schliesslich müssen wir mailman nur noch sagen, dass er statt /cgi-bin/mailman jetzt auf /mailman/ hört. Dazu müssen wir die Datei /usr/lib/mailman/Mailman/mm_cfg.py anpassen, so dass die folgenden Zeilen darin vorkommen:
DEFAULT_URL_PATTERN = 'http://%s/mailman/' PRIVATE_ARCHIVE_URL = '/mailman/private' IMAGE_LOGOS = '/images/mailman/'
Nach Neustart von nginx sollte dann das Mailman-Interface unter http://domain/mailman/admin/[meineliste] zu finden sein.
Das funktioniert natürlich nur, wenn Mailman und die Mailingliste auch richtig eingerichtet wurde. Dazu gibt es hier weiterführende Doku.
Weitere Hinweise zur Mailman-Migration
Da ich bei der Migration auch die URL von cgi-bin/mailman auf /mailman/ geändert habe, müssen die Listen noch angepasst werden. Dies geschieht in /var/lib/mailman über den Befehl
bin/withlist -l -a -r fix_url
Der geht alle Listen durch und trägt dort das Default-URL-Pattern ein.
Foto CC-BY-NC-SA von Éole Wind
Am Freitag und Samstag letzter Woche war ich in Düsseldorf und habe am Videocamp und Webvideopreis teilgenommen (meine persönlichen Eindrücke hier und hier). Ich habe dort zusammen mit Michael Praetorius eine Session zum Thema Livestreaming gegeben und Alex Knopf hat es dankenswerterweise aufgenommen. Hier das Video:
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Die Slides wird es dann später auch noch geben.